Трансформатор для компьютера
Что такое трансформатор? | Компьютер и жизнь
Приветствую, друзья!
Мы с вами уже знакомились с тем, как работают некоторые «кирпичики», из которых состоит современный компьютер.
Вы уже знаете, как работают диоды, а также полевые и биполярные транзисторы.
Сегодня мы с вами узнаем, как устроен еще один такой «кирпичик» — трансформатор.
Он не просто жужжит или гудит, но выполняет очень важные функции!
Если бы не изобрели эту штуку, у нас не было бы ничего – не телевидения, ни радио, ни компьютеров, ни электрического света в домах.
Мы не будем рассматривать подробно всё многообразие трансформаторов (их много), но ограничимся тем, что имеет отношения к компьютеру и периферийным устройствам.
Что такое трансформатор?
Слово «трансформатор» происходит от латинского transformo (преобразовывать). Мы рассмотрим трансформаторы — преобразователи напряжения, как наиболее нас интересующие.
Бывают еще другие трансформаторы, например, тока.
Трансформатор напряжения позволяет получить напряжение одной величины из напряжения другой величины. Все вы видели высоковольтные линии с высокими опорами, по которым передается высокое напряжение 6000, 35 000, 110 000, 220 000 или 500 000 Вольт.
В домашней же электрической сети и присутствует напряжения 220 вольт (В). Преобразование высокого напряжения в 220 В осуществляется с помощью здоровенных трансформаторов в тонны весом, которые находятся в трансформаторных подстанциях.
Из напряжения 220 В мы можем получить дома более низкое напряжение нужной величины с помощью небольшого трансформатора. Удобно, не правда ли?
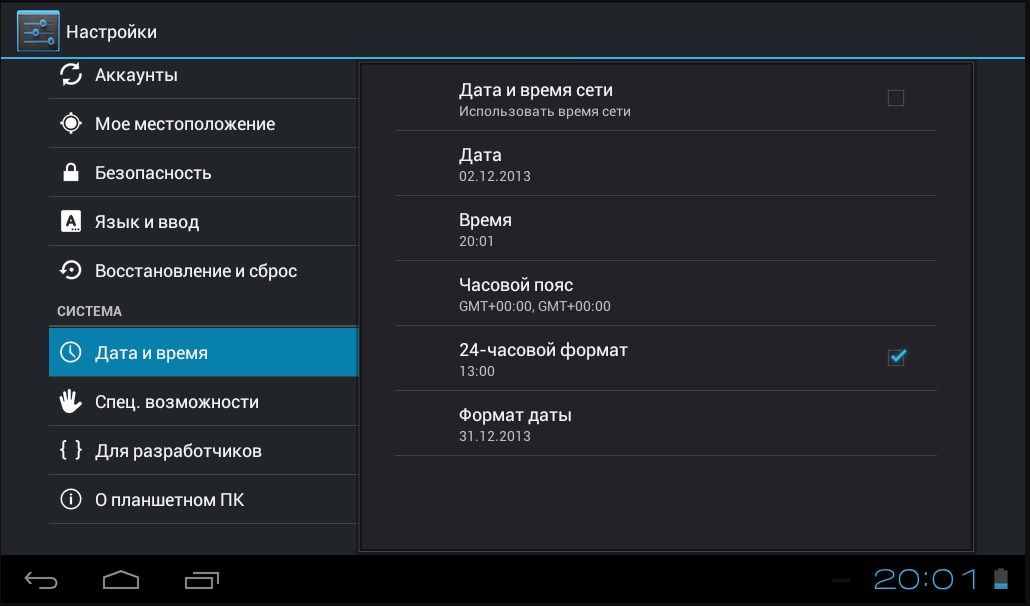
Как устроен трансформатор
Низкочастотный трансформатор содержит в себе сердечник из сплава на основе железа и размещенные на нем обмотки из провода. В упрощенном виде трансформатор содержит две обмотки — первичную и вторичную. Они изолированы друг от друга и не имеют электрического контакта.
Они изолированы друг от друга и не имеют электрического контакта.
На первичную обмотку подается преобразуемое напряжение, со вторичной снимается напряжение, нужное нам.
Это и отражено в символическом изображении трансформатора в электрических схемах. Обмотки изображают в виде волнистых линий с отводами, сердечник — одной (или несколькими, зависит от стандарта) прямой линией.
При подаче переменного тока в первичную обмотку в ней возникает переменное магнитное поле.
Магнитное поле характеризуется такой числовой величиной, как магнитный поток.
Чем больше ток в первичной обмотке и чем больше там витков, тем сильнее возникающий магнитный поток.
Это магнитный поток наводит (генерирует) переменное напряжение во вторичной обмотке.
Если подключить к вторичной обмотке нагрузку, по ней потечет переменный ток. Следует отметить, что частота переменного напряжение во вторичной обмотке будет равна частоте напряжения в первичной обмотке.
Что будет, если первичную обмотку подключить к источнику постоянного напряжения? Появится ли постоянное напряжение на вторичной обмотке, ведь при протекании тока в первичной обмотке в ней генерируется магнитный поток?
Нет, не появится! Напряжение во вторичной обмотке находится только при переменном магнитном потоке, а при постоянном токе он постоянен.
Роль сердечника заключается в том, что он почти полностью концентрирует в себе магнитный поток.
Без сердечника магнитная связь обмоток было бы слабее.
И мощность, отдаваемая вторичной обмоткой в нагрузку, было бы гораздо меньше.
Полная теория трансформатора довольно сложна.
Чтобы исчерпывающим образом описать его работу, необходимо применять математический аппарат с интегралами, производными и прочими сложными понятиями.
Мы не будем здесь этого делать, но приведем несколько базовых соотношений, имеющих практическую пользу.![]()
Габаритная мощность и КПД трансформатора
Для начала отметим, что, чем больше поперечное сечение сердечника (или магнитопровода) трансформатора, тем большую мощность можно получить на вторичных обмотках.
Именно поэтому большие трансформаторы, установленные в трансформаторных подстанциях и питающие несколько многоэтажек, имеют большой вес и габариты.
Маломощные трансформаторы, отдающие мощность в несколько Ватт (Вт), умещаются на ладони.
Трансформатор характеризуется габаритный мощностью, т.е. суммарной мощностью, отдаваемой всеми вторичными обмотками.
Как известно, мощность Р2 = U2 * I2, где U2, I2 – соответственно, напряжение и ток вторичной обмотки трансформатора.
Отметим, что не вся мощность, потребляемая первичной обмоткой от источника передается во вторичную. Часть мощности идет на нагрев проводов и сердечника.
Кроме того, некоторая часть магнитного потока, создаваемого первичной обмоткой, рассеивается в пространстве и не участвуют в наведении напряжения во вторичных обмотках.
Именно поэтому, КПД (коэффициент полезного действия) трансформатора, т.е. отношение мощности вторичной обмотки P2 к мощности первичной обмотки P1 меньше 100%.
КПД: η = P2 / P1
В общем случае, чем больше габаритная мощность трансформатора, тем больше его КПД.
КПД маломощных трансформаторов может составлять величину 60 – 80%. КПД мощных трансформаторов в распределительных подстанциях может иметь величину 99% .
Провода в обмотках нагреваются потому, что они имеют не нулевое сопротивление. Прохождения тока по проводнику, обладающему сопротивлением, вызывает, по закону Джоуля-Ленца, его нагрев.
Именно поэтому обмотки трансформатора выполняют из меди, как материала, обладающего низким удельным сопротивлением.
Количество витков на вольт и сечение магнитопровода трансформатора
Напряжение на вторичной обмотке пропорционально количеству витков провода в ней. Чем больше витков, тем больше напряжение на ней.
Маломощный трансформатор характеризуется такой вспомогательной величиной, как количество витков на вольт.
Она связана достаточно сложной зависимостью с сечением магнитопровода трансформатора.
Для маломощных однофазных трансформаторов c сердечником из отдельных пластин приближённая формула имеет вид:
w = 50/S, где S — сечение магнитопровода в кв. сантиметрах, w – количество витков на вольт.
Таким образом, если сечение магнитопровода имеют величину, скажем 4 кв. см, то для него w = 50/4 = 12,5.
Если первичная обмотка рассчитана на напряжение 220 вольт количество витков в ней должно быть: w1 = 220*12,5 = 2750. А если нам надо, например, иметь 15 вольт на вторичной обмотке, надо намотать w2 = 15*12,5 = 188 витков.
В заключение первой части рассмотрим, что такое коэффициент трансформации.
Коэффициент трансформации трансформатора
Трансформатор характеризуется ещё такой величиной, как коэффициент трансформации. Коэффициент трансформации k — это отношение напряжения вторичной обмотки к напряжению первичной обмотки: k = U2/U1. Если имеется несколько вторичных обмоток разными напряжениями, то для каждой будет свой коэффициент трансформации.
Из вышесказанного видно, что коэффициент трансформации определяется соотношением витков вторичной и первичной обмоток: k = w2/w1.
Для приведенных выше цифр в примере k = 15/220 = 188/2750 = 0,068
Для понижающего трансформатора коэффициент трансформации будет меньше единицы, для повышающего – больше.
Бывают трансформаторы с коэффициентом трансформации, равным единице.
В этом случае трансформатор служит для гальванической развязки разных частей схемы.
Во второй части мы продолжим знакомство с этой интересной штуковиной.
Можно еще почитать:
Как устроен компьютерный блок питания. Часть 1.
Как устроен компьютерный блок питания. Окончание.
Какой мощности нужен стабилизатор напряжения для компьютера?
Автор:
Сергей Куртов
Время прочтения: 5 мин
Дата публикации: 14-02-2023
Рейтинг статьи: (2)
Содержание
Персональный компьютер начал становиться распространенным устройством в каждой семье еще с начала века. Спустя столько времени мало что изменилось кроме того, что некоторые десктопным системам предпочитают ноутбуки или даже планшеты. Как бы там ни было, десктопный ПК - это все еще крайне востребованное устройство как в быту, так и в различных сферах деятельности.
Компьютер, телевизор и холодильник - это, вероятно, наиболее часто используемые электроприборы в украинской семье. Возможно, именно поэтому они регулярно выходят из строя по причине сильных перепадов напряжения в электросети. Именно поэтому мы рассмотрим, нужен ли стабилизатор напряжения для компьютера и какой стабилизатор в принципе для него подойдет.
Возможно, именно поэтому они регулярно выходят из строя по причине сильных перепадов напряжения в электросети. Именно поэтому мы рассмотрим, нужен ли стабилизатор напряжения для компьютера и какой стабилизатор в принципе для него подойдет.
Безопасна ли работа ПК в нестабильной сети
Все комплектующие компьютера работают не напрямую от сети, а от блока питания. БП формирует постоянный ток нескольких номиналов напряжения, которые разводятся на материнскую плату, процессор, видеокарту, жесткие диски и прочую периферию. Монитор же питается от отдельного внешнего или встроенного блока питания.
Импульсные блоки питания практически всеядны. Они справляются со своей задачей даже при серьезных отклонениях входного напряжения и практически при любых искажениях его формы, так как в любом случае напряжение будет выпрямляться и понижаться. Как бы там ни было, даже для электроники, работающей от импульсного блока питания, лавинообразные скачки сетевого напряжения опасны. Если повезет, сработает встроенная защита блока питания (если БП достаточно качественный и имеет хорошую защиту). В ином случае выходит из строя материнская плата или другие комплектующие.
В ином случае выходит из строя материнская плата или другие комплектующие.
Таким образом, вероятность выхода компьютера из строя из-за всеядного импульсного блока питания хоть и крайне мала, она имеется. Поэтому, возможно, стоит задуматься о недорогом устройстве, которое позволит избежать возможной поломки дорогостоящих комплектующих.
Выбор стабилизатора для компьютера
Одним из ключевых параметров при выборе огромной номенклатуры техники является мощность. Компьютерный БП, к примеру, должен питать всю систему, поэтому его мощность подбирается в соответствии с комплектующими. Рассмотрим, какой мощности нужен стабилизатор напряжения для компьютера.
Как известно, мощность нельзя выбирать впритык, нужно создавать определенный запас, чтобы устройство не работало на пределе возможностей и, возможно, для определенного потенциала в будущем. Вот, БП для компьютера вполне разумно выбирать со значительным запасом, так как он может пригодиться в дальнейшем апгрейде системы или при добавлении дополнительных жестких дисков, вентиляторов и прочей периферии. Таким образом, блок питания по умолчанию имеет запас по мощности, что избавляет от необходимости создавать серьезный запас для стабилизатора. Если блок питания выбран верно, то при полной нагрузке системы он не будет работать на полную мощность. Поэтому делать стандартный 30% запас для стабилизатора не имеет смысла. Особенно, если учитывать, что большую часть времени о полной нагрузке речи не идет.
Таким образом, блок питания по умолчанию имеет запас по мощности, что избавляет от необходимости создавать серьезный запас для стабилизатора. Если блок питания выбран верно, то при полной нагрузке системы он не будет работать на полную мощность. Поэтому делать стандартный 30% запас для стабилизатора не имеет смысла. Особенно, если учитывать, что большую часть времени о полной нагрузке речи не идет.
Так как компьютер без монитора - бесполезное устройство, не стоит забывать и о нем. С блоком питания для монитора абсолютно та же история: он подобран производителем и больше монитор потреблять просто не может.
Таким образом, можно просуммировать мощности блоков питания монитора, системного блока и прочей периферии, и на этом всё? Не совсем. Дело в том, что из-за специфики конструкции большинства бытовых стабилизаторов, номинальная мощность выдается только при 220В на входе. Компенсация просадок, к примеру, уменьшает максимальную выходную мощность, так как стабилизаторы работают на основе изменения коэффициента трансформации автотрансформатора. Таким образом, нужно выбирать стабилизатор не по номинальной, а по минимальной мощности при компенсации, которая обычно указывается производителем. Если минимальная мощность соответствует сумме мощностей блоков питания и периферии, можно не сомневаться, что этого хватит.
Таким образом, нужно выбирать стабилизатор не по номинальной, а по минимальной мощности при компенсации, которая обычно указывается производителем. Если минимальная мощность соответствует сумме мощностей блоков питания и периферии, можно не сомневаться, что этого хватит.
Как насчет более глобальной защиты?
Чаще всего для бытовой техники и электроники выбираются ступенчатые стабилизаторы напряжения релейного или электронного типа. Работают они по одинаковому принципу, только в первом случае силовыми ключами являются электромагнитные реле, а во втором - полупроводниковые симметричные тиристоры. Релейные модели, как правило, вдвое или втрое дешевле электронных аналогов.
А теперь представим, что Вы купили доступный стабилизатор невысокой мощности и от него подключили компьютер. Стабилизатор будет стоять где-то рядом, подключаясь в розетку. Электромагнитные реле, щелкающие при смене ступени стабилизации, могут раздражать. По-хорошему релейные стабилизаторы не должны стоять в жилом помещении из-за этого недостатка. Тогда установить электронный аналог? Возможно, но цена такого решения будет значительно выше и тут стоит задуматься: может немного добавить и установить релейный стабилизатор для всей квартиры?
Тогда установить электронный аналог? Возможно, но цена такого решения будет значительно выше и тут стоит задуматься: может немного добавить и установить релейный стабилизатор для всей квартиры?
Релейный стабилизатор для дома, скажем, на 7-9 кВт по цене будет в среднем в полтора-два раза дороже, чем электронный аналог на киловатт-полтора для одного лишь компьютера. Стоит понимать, что, заплатив немного больше, Вы защитите все оборудование в доме, суммарная цена которого будет в разы выше. Релейный стабилизатор, установленный в котельной дома или прихожей квартиры не будет Вас беспокоить переключением ступеней.
Что касается компьютера, то отдельно для него стоит установить ИБП. Бюджетный линейно-интерактивный источник бесперебойного питания не только защитит ПК аналогично стабилизатору, но и позволит избежать неприятных случаев, когда внезапное обесточивание сети приводит к потере несохраненных данных. И цена такого решения для компьютера будет ниже, чем электронный стабилизатор малой мощности.
Комплект трансформатора преобразователя напряжения для настольного компьютера на 110 или 220 Вольт, 110220Volts.com
Вероятно, в вашем браузере отключен JavaScript.
Для использования функций этого веб-сайта в вашем браузере должен быть включен JavaScript.
Будьте первым, кто оставит отзыв об этом продукте
Артикул: DESKTOP-5STAR
- 110220volts покупка преобразователя напряжения стала быстрой и легкой! Преобразователи 5STAR предназначены для того, чтобы избавить вас от головной боли, связанной с покупкой преобразователя напряжения для вашей бытовой техники и электроники. Больше никаких сложностей с поиском трансформатора преобразователя напряжения, который подойдет для ваших электронных устройств. Трансформатор преобразователя напряжения DESKTOP-5STAR предназначен для работы с настольным компьютером ЛЮБОГО размера и модели В ЛЮБОЙ МИРЕ! Включая ваш принтер и динамики.
Доступность: в складе
$ 199,99 $ 100,00
- Описание продукта
- Спецификации
- CMS
- Обзор продукта
Описание продукта
- Преобразователь напряжения DESKTOP-5STAR обладает следующими возможностями:
- Помимо преобразования электроэнергии, этот преобразователь оснащен защитой от перенапряжения и регулировкой напряжения, чтобы гарантировать, что ваш настольный компьютер будет постоянно получать электроэнергию, защищая ваш настольный компьютер от электричества. скачки и пики.
- Вольтметр отображает входное и выходное напряжение для вашего удобства.
- Простота в использовании, все, что вам нужно сделать, это выбрать входное напряжение в соответствии со страной, где будет использоваться этот преобразователь (110–120 или 220–240 Вольт), и подключить ваше оборудование к розетке, рассчитанной на электроэнергию.
 необходимые для работы вашего оборудования. (либо 110, либо 220 вольт)
необходимые для работы вашего оборудования. (либо 110, либо 220 вольт) - 110220 вольт даже включает краткое руководство по настройке устройства и советы по поиску и устранению неисправностей
- Выберите страну, в которой вы будете использовать этот преобразователь напряжения, и мы предоставим вам соответствующий штепсельный адаптер, это позволит вам без проблем подключить преобразователь к стене!
- DESKTOP-5STAR В комплект трансформатора преобразователя напряжения входят:
- 1 трансформатор преобразователя напряжения, который будет работать с любым настольным компьютером в любой точке мира.
- 1 Комплект переходников для вилок, который позволит вам подключить преобразователь к розетке, куда бы вы ни направлялись.
- 1 Руководство по быстрому запуску и устранению неисправностей, которое поможет вам быстро настроить устройство.
- DESKTOP-5STAR Гарантии:
- Мы гарантируем беспроблемную покупку конвертера DESKTOP-5STAR.
 ВСЕ устройства DESKTOP-5STAR проходят визуальный осмотр и тестирование перед отправкой в пункт назначения.
ВСЕ устройства DESKTOP-5STAR проходят визуальный осмотр и тестирование перед отправкой в пункт назначения. - МЫ ГАРАНТИРУЕМ, что преобразователь напряжения DESKTOP-5STAR будет работать с настольным компьютером любого размера и модели в любой точке мира.
- Наши преобразователи DESKTOP-5STAR считаются специальными товарами, а это означает, что в течение 45-дневного гарантийного периода, если у вас возникнут какие-либо проблемы, такие как DOA, неисправное устройство или установка этого устройства на работу с вашим настольным компьютером, мы обменяем ваш преобразователь напряжения DESKTOP-5STAR с совершенно новым блоком.
- На все модели 5STAR также распространяется наша 5-летняя ГАРАНТИЯ С ЗАМЕНОЙ деталей и работ.
- Мы гарантируем беспроблемную покупку конвертера DESKTOP-5STAR.
4559
. Преобразователи
Преобразователи 5STAR предназначены для избавления от головной боли, связанной с покупкой преобразователя напряжения для бытовой техники и электроники.
Больше никаких сложностей с поиском трансформатора преобразователя напряжения, который подойдет для ваших электронных устройств.
Преобразователь напряжения DESKTOP-5STAR предназначен для работы с настольными компьютерами ЛЮБОГО размера и модели В ЛЮБОЙ МИРЕ! Включая ваш принтер и динамики.
Технические характеристики
Спецификации
Вход и
Выходное напряжение
Метры напряжения
Входное напряжение
. Время
Выключатель с задержкой - перенапряжение
и защита от перенапряжения
задерживают
введение тока
для вас
безопасность оборудования
Надежная переноска
ручка Вход 80 -
140 и 120 - 240
вольт Точность
Регулировка выхода
+/- 4% Универсальность
Выходная розетка
Размеры: 5,75" X
7,25" X 9,75"
Вес: 15,5 фунтов Максимальная мощность:
0 18.
 2 Amps @
2 Amps @ 110 вольт / 9,10
Amps @ 220 Volts
Обзор продукта
Напишите свой собственный обзор
, которые купили этот продукт, также приобрели
(2)00.
(2) 90000004
(2)00000000.
(2)00000000.
(2)000000.
. Кэмерон Р. Вульф
Трансформеры зрения действительно полезны?
Базовое изображение архитектуры преобразователя видения (создано автором) Преобразователи — это тип архитектуры глубокого обучения, основанный в первую очередь на модуле самоконтроля, который первоначально был предложен для выполнения последовательных задач (например, перевода предложение с одного языка на другой). Недавние исследования глубокого обучения дали впечатляющие результаты, адаптировав эту архитектуру к задачам компьютерного зрения, таким как классификация изображений. Преобразователи, применяемые в этой области, обычно называются (что неудивительно) преобразователями зрения.
Преобразователи, применяемые в этой области, обычно называются (что неудивительно) преобразователями зрения.
Подождите... как можно использовать модель языкового перевода для классификации изображений? Хороший вопрос. Хотя в этом посте эта тема будет подробно рассмотрена, основная идея состоит в том, чтобы:
- преобразовать изображение в последовательность сглаженных фрагментов изображения
- передать последовательность фрагментов изображения через модель преобразователя
- взять первый элемент выходной последовательности преобразователя и пропустите его через модуль классификации
По сравнению с широко используемыми моделями сверточных нейронных сетей (CNN), преобразователям зрения не хватает полезных индуктивных смещений (например, инвариантность перевода и локальность). Тем не менее, оказалось, что эти модели довольно хорошо работают по сравнению с популярными вариантами CNN в задачах классификации изображений, а последние достижения сделали их эффективность — как с точки зрения объема данных, так и требуемых вычислений — более разумной. Таким образом, преобразователи зрения теперь являются жизнеспособным и полезным инструментом для практиков глубокого обучения.
Таким образом, преобразователи зрения теперь являются жизнеспособным и полезным инструментом для практиков глубокого обучения.
собственное внимание
Архитектура преобразователя состоит из двух основных компонентов: сетей прямой связи и собственного внимания. Хотя сети с прямой связью знакомы большинству, я обнаружил, что самовнимание зачастую понимается менее широко. В Интернете можно найти множество подробных описаний само-внимания, но здесь я приведу краткий обзор этой концепции для полноты картины.
что такое внимание к себе? Само-внимание принимает n элементов (или токенов) в качестве входных данных, преобразует их и возвращает n токена на выходе. Это модуль последовательности к последовательности, который для каждого входного маркера выполняет следующие действия:
- Сравнивает этот маркер с любым другим маркером в последовательности
- Вычисляет показатель внимания для каждой из этих пар
- Устанавливает текущий маркер равна средневзвешенному значению всех входных токенов, где веса задаются баллами внимания
Такая процедура адаптирует каждый токен во входной последовательности, просматривая полную входную последовательность, определяя в ней наиболее важные токены, и адаптация представления каждого токена на основе наиболее подходящих токенов. Другими словами, задается вопрос: «На какие токены стоит обратить внимание?» (отсюда и название самовнимание).
Другими словами, задается вопрос: «На какие токены стоит обратить внимание?» (отсюда и название самовнимание).
многоголовое внимание к себе. Вариант внимания, используемый в большинстве трансформеров, немного отличается от приведенного выше описания. А именно, трансформеры часто используют «многоголовую» версию внимания к себе. Хотя это может показаться сложным, это совсем не так. Многоголовое само-внимание просто использует несколько разных модулей само-внимания (например, восемь) параллельно. Затем выходные данные этих моделей внутреннего внимания объединяются или усредняются, чтобы снова объединить их выходные данные.
откуда это взялось? Несмотря на использование внутреннего внимания в трансформерах, эта идея предшествует архитектуре трансформеров. Он активно использовался с архитектурами рекуррентных нейронных сетей (RNN) [6]. Однако в этих приложениях внутреннее внимание обычно использовалось для агрегирования скрытых состояний RNN вместо выполнения преобразования от последовательности к последовательности.
Архитектура трансформатора
Архитектура трансформатора Vision очень похожа на оригинальную архитектуру трансформатора, предложенную в [4]. Таким образом, базовое понимание архитектуры преобразователя, особенно компонента кодировщика, полезно для понимания преобразователей машинного зрения. В этом разделе я опишу основные компоненты трансформатора, показанные на рисунке ниже. Хотя это описание предполагает использование текстовых данных, также могут использоваться различные способы ввода (например, сглаженные участки изображения, как в преобразователях зрения).
Архитектура трансформатора (из [4]) построение входа. Преобразователь принимает на вход последовательность жетонов. Эти токены генерируются путем передачи текстовых данных (например, одного или нескольких предложений) через токенизатор, который делит их на отдельные токены. Затем эти токены, каждый из которых связан с уникальным целочисленным идентификатором, преобразуются в соответствующие им векторы внедрения путем индексирования обучаемой матрицы внедрения на основе идентификаторов токенов, формируя ( N x d) матрицу входных данных (т.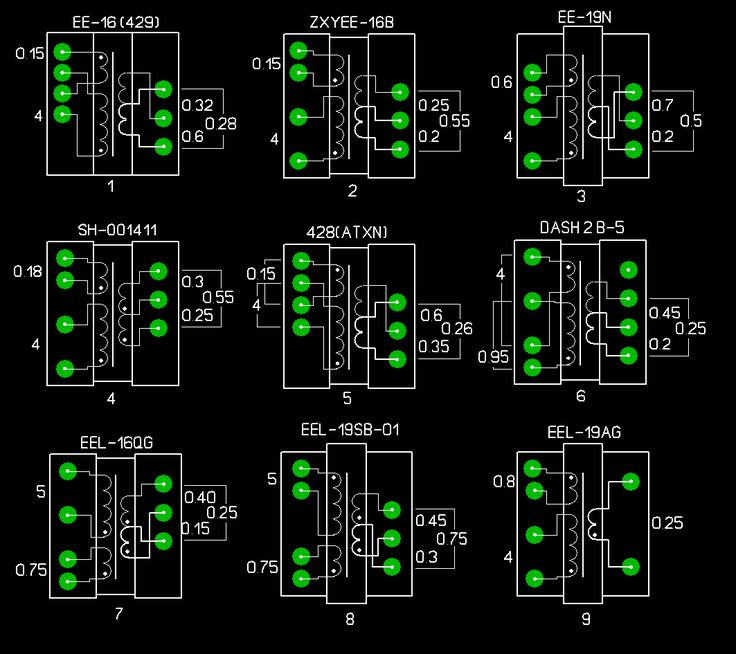 е.
е. N маркеров, каждый из которых представлен вектором размерности d ).
Как правило, вся мини-партия размером (B x N x d) , где B — размер партии, сразу передается на трансформатор. Чтобы избежать проблем с различными последовательностями, имеющими разную длину, все последовательности дополняются (т. е. с использованием нулевых или случайных значений), чтобы иметь одинаковую длину N . Заполненные области игнорируются внутренним вниманием.
После токенизации и внедрения входных данных необходимо выполнить последний шаг — добавить позиционные вложения к каждому входному токену. Само-внимание не имеет понятия о положении — все жетоны рассматриваются одинаково независимо от их положения. Таким образом, обучаемые вложения позиции должны быть добавлены к каждому входному токену, чтобы ввести информацию о позиции в преобразователь.
Архитектура преобразователя энкодера (из [4]) энкодер. Энкодерная часть преобразователя имеет много повторяющихся слоев идентичной структуры. В частности, каждый уровень содержит следующие модули:
Энкодерная часть преобразователя имеет много повторяющихся слоев идентичной структуры. В частности, каждый уровень содержит следующие модули:
- Многоголовое самообслуживание
- Нейронная сеть прямого распространения
За каждым из этих модулей следует нормализация уровня и остаточное соединение. При передаче входной последовательности через эти слои представление каждого токена преобразуется с использованием:
- представления других релевантных токенов в последовательности
- обученная многослойная нейронная сеть, реализующая нелинейное преобразование каждого отдельного токена
Когда несколько таких слоев применяются подряд, эти преобразования производят конечная выходная последовательность одинаковой длины с контекстно-зависимыми представлениями для каждого токена.
Преобразователь архитектуры декодера (из [4]) декодер. Декодеры не относятся к преобразователям машинного зрения, архитектура которых состоит только из кодировщиков. Тем не менее, мы кратко рассмотрим здесь архитектуру декодера для полноты картины. Как и энкодер, декодер преобразователя содержит несколько уровней, каждый со следующими модулями:
- Маскированное внимание с несколькими головками
- Внимание с несколькими головками, кодировщик-декодер
- Нейронная сеть с прямой связью
Маскированное внимание к себе похоже на нормальное/двунаправленное внимание к себе, но предотвращает «заглядывание вперед» во входной последовательности (т. е. это необходимо для последовательных задач, таких как языковой перевод). Каждый токен может быть адаптирован только на основе токенов, которые идут перед ним во входной последовательности. Само-внимание кодера-декодера также очень похоже на нормальное само-внимание, но представления от кодировщика также используются в качестве входных данных, что позволяет объединить информацию от кодировщика и декодера. Затем результат этого вычисления снова передается через нейронную сеть с прямой связью.
различные варианты архитектуры. В дополнение к модели преобразования последовательности в последовательность, описанной в этом разделе, существует множество архитектурных вариантов, в которых используются одни и те же базовые компоненты. Например, архитектуры преобразователя только для кодировщика, обычно используемые в задачах понимания языка, полностью отказываются от части преобразователя декодера, в то время как архитектуры преобразователя только декодера обычно используются для генерации языка. Трансформатор Vision обычно использует архитектуру преобразователя только для кодировщика, поскольку нет генеративного компонента, который требует использования замаскированного внутреннего внимания.
предварительное обучение с самоконтролем
Хотя преобразователи изначально были предложены для задач преобразования последовательности в последовательность, их популярность резко возросла по мере того, как архитектура позже применялась для таких задач, как генерация текста и классификация предложений. Одной из основных причин широкого успеха трансформеров было использование методов предварительной подготовки с самоконтролем.
Задачи с самостоятельным наблюдением (например, предсказание замаскированных слов; см. рисунок выше) могут быть созданы для обучения преобразователей на необработанных, немаркированных текстовых данных. Поскольку такие данные широко доступны, преобразователи могут быть предварительно обучены на большом количестве текстовых данных, прежде чем их можно будет точно настроить для контролируемых задач. Такая идея была популяризирована BERT [7], который добился потрясающих улучшений в понимании естественного языка. Однако этот подход был принят во многих более поздних применениях трансформаторов (например, GPT-3 [9].]).
Интересно, что, несмотря на огромное влияние самоконтролируемого обучения в приложениях на естественном языке, этот подход не был столь успешным в преобразователях зрения, хотя во многих работах предпринимались попытки применить эту идею [11, 12].
некоторые революционные приложения-трансформеры…
Имея общее представление об архитектуре трансформатора, полезно представить в перспективе огромное влияние, которое эта архитектура оказала на исследования в области глубокого обучения. Первоначально архитектура трансформатора была популяризирована благодаря успеху в языковом переводе [4]. Однако эта архитектура продолжает революционизировать многочисленные области исследований глубокого обучения. Несколько известных применений трансформаторов (в хронологическом порядке) перечислены ниже:
- BERT использует предварительное обучение с самоконтролем для изучения высококачественных языковых представлений [бумага] [код]
- GPT-2/3 использует архитектуры преобразователя только для декодера, чтобы произвести революцию в генеративном языковом моделировании [блог] [бумага]
- AlphaFold2 использует архитектуру преобразователя для решения давней проблемы сворачивания белков [бумага][код]
- DALLE-2 использует латентные (и диффузные) CLIP для достижения шокирующих результатов в мультимодальной генерации [блог][бумага]
Хотя области применения трансформаторов обширны, главный вывод, который я хочу подчеркнуть, прост: трансформаторы чрезвычайно эффективны при решении самых разных задач .
Изображение стоит 16x16 слов: трансформеры для распознавания изображений в масштабе [1]
Хотя архитектура трансформера оказала огромное влияние на область обработки естественного языка, расширение этой архитектуры на компьютерное зрение потребовало времени. Первоначальные попытки объединить популярные архитектуры CNN с модулями самоконтроля для создания гибридного подхода, но эти методы уступили архитектурам CNN на основе ResNet.
Помимо интеграции компонентов, подобных преобразователям, в архитектуры CNN, в [1] была предложена модель классификации изображений, которая напрямую использует архитектуру преобразователя. Модель Vision Transformer (ViT) делит базовое изображение на набор участков, каждый из которых выравнивается и проецируется (линейно) на фиксированное измерение. Затем к каждому патчу изображения добавляется встраивание положения, указывающее местоположение каждого патча в изображении. Подобно любой другой архитектуре преобразователя, вход модели — это просто последовательность векторов; см. ниже.
Авторы принимают базовую и большую [7] BERT (т. е. архитектуру преобразователя только для кодировщика) для своей архитектуры, которая затем обучается путем присоединения контролируемого заголовка классификации к первому токену в выходных данных модели. Для обучения следует двухэтапная процедура предварительной подготовки и тонкой настройки. Для контролируемого предварительного обучения используется набор данных JFT-300M (очень большой), ImageNet-21K (большой) или ImageNet-1K (средний). Затем модель настраивается на некотором целевом наборе данных (например, Oxford Flowers или CIFAR-100), после чего измеряется окончательная производительность.
Без предварительного обучения на достаточном количестве данных предлагаемая модель не соответствует современным характеристикам CNN или превосходит их. Такая тенденция, вероятно, связана с тем фактом, что, хотя CNN естественным образом инвариантны к шаблонам, таким как перевод и локальность, преобразователи не имеют такого индуктивного смещения и должны изучать эти инвариантности из данных. Однако по мере того, как модель предварительно обучается на большем количестве данных, производительность резко улучшается, в конечном итоге превышая точность базовых линий на основе CNN даже при более низких затратах на предварительное обучение; см. результаты ниже.
Обучение преобразователей изображений с эффективным использованием данных и дистилляция с помощью внимания [2]
Хотя в предыдущей работе было продемонстрировано, что преобразователи зрения эффективны для классификации изображений, такие результаты основывались на интенсивном предварительном обучении на внешних наборах данных. Например, лучшие модели ViT выполняли предварительное обучение на наборе данных JFT-300M, содержащем 300 миллионов изображений, перед тонкой настройкой и оценкой модели на последующих задачах.
Хотя в предыдущей работе утверждалось, что необходимы обширные процедуры предварительной подготовки, авторы в [3] предложили альтернативное предложение, названное Data-efficient Image Transformer (DeiT), которое использует кураторскую процедуру дистилляции знаний для обучения трансформеров зрения высокой эффективности. -1 точность без каких-либо внешних данных или предварительной подготовки. Фактически весь учебный процесс можно пройти за три дня на одном компьютере.
Архитектура преобразователя зрения, используемая в этой работе, почти идентична модели ViT. Однако во входную последовательность добавляется дополнительный токен, который называется токеном дистилляции; см. рисунок ниже.
(из [2])Этот токен обрабатывается так же, как и другие. Но, после выхода из конечного слоя трансформатора, он используется для подачи на потери в сети дистилляционной составляющей. В частности, применяется жесткая перегонка (т. е. в отличие от мягкой перегонки), которая обучает преобразователь зрения воспроизводить вывод argmax некоторой учительской сети (обычно CNN).
Во время тестирования вывод токена для класса и токены дистилляции объединяются и используются для прогнозирования окончательного вывода сети. Модель DeiT превосходит несколько предыдущих вариантов ViT, предварительно обученных на больших внешних наборах данных. DeiT достигает конкурентоспособной производительности при предварительном обучении в ImageNet и точной настройке для последующих задач. Другими словами, обеспечивает убедительную производительность без использования внешних обучающих данных.
Помимо своей впечатляющей точности, модифицированная стратегия обучения в DeiT также весьма эффективна. Принимая во внимание пропускную способность (то есть количество изображений, обрабатываемых моделью в секунду) различных моделей классификации изображений, DeiT достигает баланса между пропускной способностью и точностью, который аналогичен широко используемой модели EfficientNet [4]; см. рисунок ниже.
(из [2])Изучение переносимых визуальных моделей из наблюдения за естественным языком [3]
(из [3]) Контрастная модель предварительного обучения языку-изображению (CLIP) — недавно вновь стала популярной из-за ее использования в DALLE -2 – был первым, кто показал, что большое количество зашумленных пар изображение-заголовок можно использовать для изучения высококачественных представлений изображений и текста. Предыдущая работа изо всех сил пыталась правильно использовать такие слабо контролируемые данные из-за использования плохо продуманных задач перед обучением; например, прямое предсказание каждого слова подписи с использованием языковой модели. CLIP представляет более простую задачу перед обучением — сопоставление изображений с правильной подписью в группе потенциальных подписей. Эта упрощенная задача обеспечивает лучший обучающий сигнал для модели, что позволяет изучать высококачественные изображения и текстовые представления во время предварительного обучения.
Модель, используемая в CLIP, состоит из двух основных компонентов: кодировщик изображения и кодировщик текста; см. рисунок выше. Кодер изображения реализуется либо как CNN, либо как модель преобразователя зрения. Однако авторы обнаруживают, что вариант CLIP с преобразователем зрения обеспечивает повышенную вычислительную эффективность во время предварительной подготовки. Текстовый кодировщик представляет собой простую архитектуру преобразователя, состоящую только из декодера, что означает, что в слоях преобразователя используется замаскированное внутреннее внимание. Авторы решили использовать маскированное самовнимание, чтобы в будущем текстовый компонент CLIP можно было расширить для приложений языкового моделирования.
При использовании этой модели задача предварительного обучения реализуется путем раздельного кодирования изображений и надписей, а затем применения нормализованной кросс-энтропийной потери в температурном масштабе для сопоставления представлений изображений с соответствующими представлениями надписей. Полученная в результате модель CLIP произвела революцию в производительности нулевого выстрела для классификации изображений, повысив точность теста нулевого выстрела в ImageNet с 11,5% до 76,2%. Чтобы выполнить нулевую классификацию, авторы просто:
- Закодируйте имя каждого класса с помощью текстового кодировщика
- Закодируйте изображение с помощью кодировщика изображений
- Выберите класс, который максимизирует косинусное сходство с кодированием изображения
Такая процедура изображена на рисунке выше. Для получения дополнительной информации о CLIP, пожалуйста, смотрите мой предыдущий обзор модели.
ViT работают… но практичны ли они?
Лично я поначалу весьма скептически относился к использованию преобразователей зрения, несмотря на то, что знал об их впечатляющих характеристиках. Процесс обучения казался слишком затратным в вычислительном отношении. Однако большая часть вычислительных затрат на обучение преобразователей зрения связана с предварительным обучением. В [2] авторы устранили необходимость обширного предварительного обучения и прямо продемонстрировали, что пропускная способность обучения преобразователей зрения сравнима с высокоэффективными архитектурами CNN, такими как EfficientNet. Таким образом, преобразователи зрения являются жизнеспособным и практичным инструментом глубокого обучения, поскольку их накладные расходы незначительно превосходят обычные CNN.
Хотя трансформеры широко используются в обработке естественного языка, этот обзор должен (надеюсь) показать тот факт, что они также полезны для задач компьютерного зрения. CNNS трудно превзойти, поскольку они достигают впечатляющих уровней производительности эффективным образом — как с точки зрения данных, так и с точки зрения вычислений. Однако недавние модификации архитектуры преобразователя зрения, описанные в [2], ясно показали, что преобразователи зрения лучше работают по сравнению с CNN и на самом деле довольно эффективны.
преобразователи зрения в коде. Тем, кто заинтересован во внедрении и/или экспериментировании с архитектурами преобразования зрения, я бы рекомендовал начать здесь. Это руководство позволяет (i) загружать предварительно обученные параметры ViT и (ii) точно настраивать эти параметры для последующих задач машинного зрения. Я нахожу код в этом руководстве довольно простым для понимания. Этот код можно легко распространить на другие приложения или даже реализовать некоторые из более сложных процедур обучения, описанных в [2] или другой работе.
будущих статей для чтения. Несмотря на то, что в этом посте были рассмотрены некоторые из моих любимых работ по преобразованию видений, эта тема популярна, и существуют сотни других статей. Вот некоторые из моих (других) личных фаворитов:
- Pyramid Vision Transformer: универсальная магистраль для плотного прогнозирования без сверток [бумага]
- Token-to-Token ViT: Обучение трансформеров Vision с нуля в ImageNet [бумага]
- MLP-микшер: архитектура, полностью состоящая из млп, для машинного зрения [статья]
Заключение
Большое спасибо за чтение этой статьи. Если вам понравилось, подпишитесь на мой информационный бюллетень Deep (Learning) Focus, где я выбираю одну двухнедельную тему в исследованиях глубокого обучения, предоставляю понимание соответствующей справочной информации, а затем делаю обзор нескольких популярных статей по этой теме. Я Кэмерон Р. Вульф, научный сотрудник Alegion и аспирант Университета Райса, изучающий эмпирические и теоретические основы глубокого обучения. Вы также можете ознакомиться с другими моими работами на Medium!
[1] Досовицкий Алексей и др. «Изображение стоит 16x16 слов: трансформеры для распознавания изображений в масштабе». Препринт arXiv arXiv: 2010.11929 (2020).
[2] Туврон, Хьюго и др. «Обучение преобразователям изображений и дистилляции с эффективным использованием данных с помощью внимания». Международная конференция по машинному обучению . PMLR, 2021.
[3] Radford, Alec, et al. «Изучение переносимых визуальных моделей под контролем естественного языка». Международная конференция по машинному обучению . PMLR, 2021.
[4] Vaswani, Ashish, et al. «Внимание — это все, что вам нужно». Достижения в области нейронных систем обработки информации 30 (2017).
[5] Тан, Минсин и Куок Ле. «Efficientnet: переосмысление масштабирования модели для сверточных нейронных сетей». Международная конференция по машинному обучению . PMLR, 2019.
[6] Lin, Zhouhan, et al.





Видео-курс
