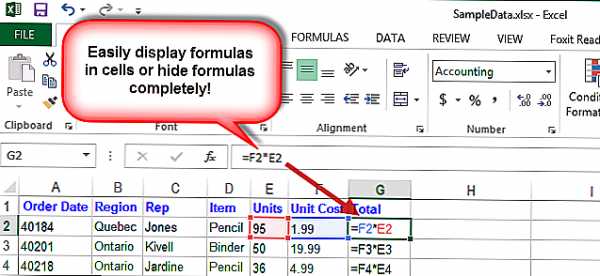
Как исключить наличие повторяющихся записей в таблице
Базы данных - тест с ответами
Информатика в настоящее время является стремительно развивающийся наукой. Многие студенты постают в технические университеты, чтобы в будущем связать свою деятельность с IT или приближенными областями. Для проверки знаний по теме Базы данных предлагаем пройти тестирование на этой странице. Обращаем ваше внимание, что в тесте правильные ответы выделены символом [+].
Фильтрация записей в таблицах выполняется с целью:
[+] а) выборки необходимых данных
[-] б) группировки данных
[-] в) сортировки данных
Формы используются для:
[-] а) вывода данных на печать
[+] б) ввода данных
[-] в) просмотра данных
Как исключить наличие повторяющихся записей в таблице:
[-] а) упорядочить строки таблицы
[-] б) проиндексировать поля таблицы
[+] в) определить ключевое поле
Какой из объектов служит для хранения данных в БД:
[+] а) таблица
[-] б) запрос
[-] в) форма
База данных – это:
[-] а) совокупность файлов на жестком диске
[-] б) пакет пользовательских программ
[+] в) совокупность сведений, характеризующих объекты, процессы или явления реального мира
Первый стандарт ассоциации по языкам обработки данных назывался:
[-] а) SQL
[+] б) CODASYL
[-] в) IMS
Какой из типов данных позволяет хранить значения величиной до 64000 символов:
[-] а) числовой
[-] б) логический
[+] в) поле МЕМО
Поле, значение которого не повторяется в различных записях, называется:
[+] а) первичным ключом
[-] б) составным ключом
[-] в) внешним ключом
Последовательность операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние, называется:
[-] а) транзитом
[-] б) циклом
[+] в) транзакцией
Как обеспечить ситуацию, при которой удаление записи в главной таблице приводит к автоматическому удалению связанных полей в подчиненных таблицах:
[-] а) установить тип объединения записей в связанных таблицах
[+] б) установить каскадное удаление связанных полей
[-] в) установить связи между таблицами
Запросы выполняются для:
[+] а) выборки данных
[-] б) хранения данных
[-] в) вывода данных на печать
СУБД – это:
[-] а) система средств администрирования банка данных
[+] б) специальный программный комплекс для обеспечения доступа к данным и управления ими
[-] в) система средств архивирования и резервного копирования банка данных
Какое поле таблицы можно считать уникальным:
[+] а) ключевое
[-] б) счетчик
[-] в) первое поле таблицы
Иерархическая база данных – это:
[-] а) БД, в которой информация организована в виде прямоугольных таблиц
[-] б) БД, в которой записи расположены в произвольном порядке
[+] в) БД, в которой элементы в записи упорядочены, т. е. один элемент считается главным, остальные подчиненными
Определите тип связи между таблицами «Преподаватели» и «Студенты», если одного студента обучают разные преподаватели:
[+] а) «многие–к–одному»
[-] б) «один–ко–многим»
[-] в) «один–к–одному»
Организованную совокупность структурированных данных в определенной предметной области называют:
[-] а) электронной таблицей
[+] б) базой данных
[-] в) маркированным списком
Столбец однотипных данных в Ассеss называется:
[-] а) отчетом
[-] б) записью
[+] в) полем
Языковая целостность БД предполагает:
[-] а) поддержку языков манипулирования данными низкого уровня
[+] б) поддержку языков манипулирования данными высокого уровня
[-] в) отсутствие поддержки языков манипулирования данными высокого уровня
Для выборки записей и обновления данных из одной или нескольких таблиц базы данных служат:
[-] а) формы
[-] б) таблицы
[+] в) запросы
Многоуровневые, региональные, отраслевые сети со свободными связями представляют собой модель организации данных следующего типа:
[-] а) обычную
[+] б) сетевую
[-] в) реляционную
Какой размер указывается по умолчанию для полей текстового типа:
[+] а) 255 символов
[-] б) 50 символов
[-] в) 100 символов
Реляционная модель данных основана на:
[-] а) иерархических списках
[+] б) таблицах
[-] в) древовидных структурах
Запись – это:
[-] а) один столбец реляционной таблицы
[-] б) строка заголовка реляционной таблицы
[+] в) одна строка реляционной таблицы
Для разработки и эксплуатации баз данных используются:
[-] а) системы управления контентом
[+] б) системы управления базами данных
[-] в) системы автоматизированного проектирования
Определите тип связи между таблицами «Преподаватели» и «Студенты», если один преподаватель обучает разных студентов:
[-] а) «один–к–одному»
[-] б) «многие–к–одному»
[+] в) «один–ко–многим»
Определить связь между таблицами «Город» и «Район», если каждому городу соответствует несколько районов:
[-] а) «многие–к–одному»
[+] б) «один–ко–многим»
[-] в) «многие-ко-многим»
Какой тип данных для поля таблицы следует выбрать для записи следующего значения (0732) 59-89-65:
[+] а) текстовый
[-] б) числовой
[-] в) счетчик
Типы данных полей таблицы MSAccess (уберите лишнее):
[-] а) Счетчик
[-] б) логический
[+] в) Общий
Предметная область – это:
[+] а) часть реального мира, представляющая интерес для данного исследования
[-] б) БД, разработанная для решения конкретной задачи
[-] в) ER-диаграмма, отражающая заданную область внешнего мира
Структура реляционной базы данных (БД) меняется при удалении:
[-] а) одной записи
[+] б) одного из полей
[-] в) нескольких записей
Запрос, который предназначен для создания новых таблиц на основе уже имеющихся в БД, называют запросом на:
[+] а) создание таблиц
[-] б) обновление
[-] в) добавление
Запрос, который необходим для поиска информации, называют запросом на:
[+] а) выборку
[-] б) обновление
[-] в) добавление
Запрос, который предназначен для автоматического обновления данных в отдельных ячейках таблицы:
[-] а) добавление
[-] б) удаление
[+] в) обновление
Запрос, который предназначен для автоматического удаления записей из таблицы:
[+] а) удаление
[-] б) обновление
[-] в) на выборку
Запись содержит значение, которое меньше 100:
[+] а)
[-] б) >100
[-] в)
Определите, с помощью команд меню чего можно создать автоформу в Microsoft access?
[-] а) правка
[-] б) вид
[+] в) создание
Форма в Microsoft access служит для этого:
[-] а) создания документа
[-] б) определения ключей записи
[+] в) ввода данных
В каком режиме происходит редактирование форм?
[+] а) конструктор
[-] б) таблица
Какое средство упрощает ввод, редактирование и отображение информации, хранящейся в таблицах базы данных?
[+] а) формы
[-] б) отчёты
[-] в) запросы
С помощью чего можно создать отчет?
[+] а) конструктора
[+] б) мастера
[-] в) таблиц
4.6 Особенности проектирования многотабличных баз
ЛЕКЦИЯ 6. ОСОБЕННОСТИ ПРОЕКТИРОВАНИЯ МНОГОТАБЛИЧНЫХ БАЗ ДАННЫХ
Как правило, базы данных Access являются многотабличными базами данных. Поэтому немаловажным и достаточно трудоемким процессом является проектирование структуры баз данных, состоящее, прежде всего, в эффективном распределении данных между таблицами.
База данных, состоящая из множества таблиц, устанавливает связи между этими таблицами с помощью совпадающих полей. Рассмотрим таблицы:
 |
Данные таблицы позволяют получить информацию о городах, в которые направляются сотрудники фирмы в командировку, а также о командировках конкретных сотрудников.
В базе данных может храниться информация о сотрудниках.
Сотрудник Информация о ком. Ком
 |
Рекомендуемые материалы
Каждая запись данных таблиц идентифицирует один объект: Сотрудника, Информацию о командировке, Информацию о предприятии-командире.
Отношения между таблицами определяются отношениями между объектами (полями).
Существуют четыре типа отношений между таблицами:
ü «один-к-одному»
ü «один-ко-многим»
ü «много-к-одному»
ü «много-ко-многим»
Отношение «один-к-одному» означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице.
Например, таблицы Физические лица и Сотрудники
 |
Обе таблицы содержат информацию о сотрудниках компании, но в таблице Физические лица содержатся данные о личности сотрудника, а в таблице Сотрудники – профессиональные сведения. Между таблицами Физические лица и Сотрудники существуют отношения «один-к-одному», поскольку для одного человека может быть только одна запись, содержащая профессиональные сведения.
Связь между этими таблицами поддерживается при помощи совпадающих полей: Код сотрудника и Код физ. лица. Эти поля имеют разные наименования. Связь между таблицами устанавливается на основании значений совпадающих полей, а не их наименований.
Отношение «один-ко-многим» предполагает, что каждой записи в одной таблице может соответствовать несколько записей в другой таблице. Так, например, один и тот же сотрудник может несколько раз ездить в командировку. Кроме того, в один и тот же город могут ездить несколько сотрудников. То есть, между таблицами Сотрудники и Информация о ком., а так же Информация о ком. и Ком. существует связь «один-ко-многим».
Отношение «много-к-одному» аналогично рассмотренному ранее типу «один-ко-многим» и зависит от точки зрения на отношение.
Отношение «много-ко-многим» возникает в том случае, если:
ü одна запись первой таблицы может быть связана с более чем одной записью другой таблицы;
ü одна запись второй таблицы связана с более чем одной записью первой таблицы.
В качестве примера обратимся к магазину оптовой торговли. Рассмотрим две группы объектов:
ü список товаров, производимых предприятиями;
ü список товаров, заказанных потребителями.
Поставки товаров Заказы потребителей
 |
Между таблицами Поставки товаров и Заказы потребителей существуют отношения «много-ко-многим», так как на каждый поставляемый товар может быть более одного заказа. Аналогично, каждый заказанный товар может производиться более чем одним предприятием. Связь между полями устанавливается на основании значения Код товара.
Проектирование нормализованной базы данных
При проектировании баз данных необходимо решить вопрос о наиболее эффективной структуре данных. Основные цели, которые при этом преследуются:
ü обеспечить быстрый доступ к данным в таблицах;
ü исключить ненужное повторение данных;
ü обеспечить целостность данных так, чтобы при изменении значений одних полей выполнялось обновление всех связанных с ними полей таблиц.
Процесс уменьшения избыточности информации в базе данных называется нормализацией.
В теории нормализации баз данных разработаны достаточно формализованные подходы к распределению данных, обладающих сложной структурой, по нескольким таблицам.
Теория нормализации оперирует понятиями нормальных форм таблиц (от 1 до 5), причем каждая последующая нормализованная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. (Мы рассмотрим три нормализованные формы).
В качестве примера рассмотрим информацию о продажах некоторых товаров.
Продажи
| Код клиента Фамилия Имя Отчество Телефон Факс Индекс Страна Город Адрес Предприятие Руководитель Кредит Код товара Дата заказа Заказано Дата продажи Продано Цена Прим. к товару Категория Наименование товара |
Данную таблицу можно рассматривать как однотабличную базу данных, но в ней есть множество недостатков:
ü во всех заказах, сделанных одним и тем же предприятием, придется вводить информацию о покупке;
ü при изменении телефона или адреса покупателя эти координаты нужно выключить во всех заказах;
ü наличие новой информации снизит скорость выключения запросов и повысит вероятность ошибок.
Выполним нормализацию данных.
Первая нормальная форма таблицы
Таблица в первой нормальной форме должна удовлетворять следующим требованиям:
ü в таблице не должно быть повторения групп таблиц;
ü таблица не должна иметь повторных записей.
Поскольку покупатель может сделать несколько заказов, каждый из которых в свою очередь может содержать несколько товаров, нам необходимо две таблицы: Клиенты и Заказы. В качестве связывающего поля определим Код клиента, а отношение «один-ко-многим»
Клиенты Заказы
 |
Данными действиями мы ликвидировали повторяющиеся группы полей.
Для исключения повторяющихся записей необходимо:
1. в таблице Клиенты определить первичный индекс с ключевым полем Код клиента.
2. Первичный ключ содержит информацию, которая однозначно идентифицирует запись (не допускает повторений значений поля).
Для этого нужно выделить название поля Код клиента в окне Конструктора таблицы Клиенты и нажать кнопку Ключевое поле и команду контекстного меню Ключевое поле.
В Таблице Заказы исключить повторяющиеся записи можно одним из следующих способов:
1. добавить в таблицу уникальное ключевое поле Код заказа;
2. создать уникальный составной индекс, состоящий из полей Код клиента, Код товара и Дата заказа.
После этого данные таблицы находятся в первой нормальной форме.
Вторая нормальная форма
О таблице говорят, что она находится во второй нормальной форме, если:
1. она удовлетворяет условиям первой нормальной формы;
2. любое не ключевое поле однозначно идентифицируется полным набором ключевых полей.
Из приведенного выше определения следует, что понятие второй нормальной нормы применимо только к таблицам, имеющим составной индекс (Заказы). Данная таблица не является таблицей во второй нормальной форме, поскольку поля Категория, Наименование товара и Цена однозначно определяются только одним из ключевых полей – Код товара.
Поэтому, для приведения таблицы Заказы ко второй нормальной форме, необходимо выделить из таблицы Заказы таблицу Товары, которая будет содержать информацию о товарах каждого типа. Для связывания таблиц Заказы и Товары используются поля Код товара.
Клиенты Заказы
 |
Третья нормальная форма таблицы
О таблице говорят, что она находится в третьей нормальной форме, если:
1. она удовлетворяет условиям второй нормальной формы;
2. ни одно из не ключевых полей таблицы не идентифицируется с помощью другого не ключевого поля.
Сведение таблицы к третьей нормальной форме предполагает разделение таблицы с целью помещения в отдельную таблицу столбцов, которые не зависят от значения индекса, а зависят от другого не ключевого поля.
Так в таблице Клиенты поле Руководитель однозначно определяется значением поля Предприятие, поэтому следует создать таблицу Предприятия:
 |
Таким образом, в таблице Клиенты будем хранить только название Предприятия.
Определение связей между таблицами
После установления структуры таблиц, необходимо определить связи между совпадающими полями другой таблицы.
Для этого следует произвести следующие действия:
- вызвать команду Сервис/Схема данных или кнопку Схема данных из панели инструментов;
- добавить в окно связей окно Добавить таблицу (п.м. Связь/Добавить таблицу или кнопка Добавить таблицу).
|
| Запросы | Табл. и заказы | |
|
Клиенты Предприятия Товары |
 Таблицы
Таблицы Заказы
Заказы- в списке таблиц, последовательно выделяя таблицы, нажимать кнопку Добавить или выделить сразу все и Добавить.
| Схема данных |
|
|

- для связи полей выбрать поле первой таблицы (Код клиента) и переместить его мышью на соответствующее поле в первой таблице (Код клиента).
Ключевые поля в списке полей обычно отображаются полужирным шрифтом. Связанные поля не обязательно должны иметь одно название, но обязательно должны иметь одинаковые имена данных (а для Числового поля – еще и одинаковое свойство Размер поля).
На экране откроется окно диалога «Связи».
| Связи |
| Таблица/Запрос Связанная Таблица/Запрос Клиенты Заказы Код клиента Код клиента ¨ Обеспечение целостности данных ¨ Каскадное обновление связей полей ¨ Каскадное удаление связей записей |
| Тип отношений: один-ко-многим |
Тип создаваемой связи зависит от полей, которые были указаны при определении связи:
- отношение «один-ко-многим» создается в том случае, когда только одно из полей является ключевым или имеет уникальный индекс;
- отношение «один-к-одному» создается в том случае, если оба связываемых поля являются уникальными или ключевыми;
- связь «много-ко-многим» фактически представляет две связи с отношением «один-ко-многим» через третью таблицу, ключ которой состоит, по крайней мере, из двух полей, которые являются полями внешнего ключа в двух других таблицах.
При переносе поля, не являющегося ключевым, на другое такое же поле, создаются неопределенные отношения.
В окне диалога «Схема данных» можно не только устанавливать связи между таблицами, но и выполнять следующие действия:
ü изменять структуру таблицы;
ü изменять существующую связь;
ü удалять связь;
ü удалять таблицу из окна диалога «Схема данных»;
ü вывести на экран все существующие связи или связи только для конкретной таблицы;
ü определить связи для запросов, не задавая условия целостности данных.
Связывание двух полей одной таблицы
На практике может возникнуть необходимость в определении поля, связанного с полем той же таблицы. Например, в таблице Сотрудники может быть поле Подчиняется, которое связано с тем же полем Сотрудник.
Для связывания одного поля таблицы с другим полем той же таблицы нужно дважды добавить эту таблицу в окно диалога «Схема данных» и создать связь, соединив ноля лишней связи.
Изменение структуры таблицы в окне «Схема данных»
Для изменения структуры таблицы нужно, находясь в окне «Схема данных», выделить модифицируемую таблицу и, щелкнув правой кнопкой мыши, вызвать команду Конструктор таблиц.
Для удаления связи нужно выделить последнюю и нажать клавишу Delete. Для удаления таблицы из схемы данных ее нужно выделить и нажать Delete (только из одного окна, а не из базы данных).
Определение условий целостности данных
Условием целостности данных называют набор правил, используемых в Access для поддержания связей меду записями в связанных таблицах. Эти правила делают невозможным случайные удаления или изменения связанных данных.
Условия целостности данных выполняются, если:
ü связанное поле главной таблицы является ключевым полем;
ü связанные поля имеют один тип данных;
ü обе таблицы принадлежат одной базе данных.
В лекции "5.3. Процессы ЖЦ ПО" также много полезной информации.
Для определения целостности данных нужно в окне диалога «Схема данных» установить флажок «Обеспечение целостности данных». При этом над линией, соединяющей связанные поля таблиц, появятся обозначения 1 и ¥.
Данное условие делает доступным следующие два режима:
ü каскадное обновление связанных полей;
ü каскадное удаление связанных полей.
Если данные режимы не установлены, то при удалении, например, записи из таблицы Клиенты будут появляться сообщения о невозможности выполнения данной операции в том случае, если в таблице Заказы есть заказы, относящиеся к данному покупателю.
azure-docs.ru-ru/remove-duplicate-rows.md at master · MicrosoftDocs/azure-docs.ru-ru · GitHub
| title | titleSuffix | description | services | ms.service | ms.subservice | ms.topic | author | ms.author | ms.date | ms.openlocfilehash | ms.sourcegitcommit | ms.translationtype | ms.contentlocale | ms.lasthandoff | ms.locfileid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Удалить дублирующиеся строки: ссылка на модуль | Azure Machine Learning | Узнайте, как использовать модуль удаления повторяющихся строк в Машинное обучение Azure, чтобы удалить потенциальные дубликаты из набора данных. | machine-learning | machine-learning | core | reference | likebupt | keli19 | 10/22/2019 | bf35d08128aa8a3e8f545ed7184866694219f2cb | 772eb9c6684dd4864e0ba507945a83e48b8c16f0 | MT | ru-RU | 03/19/2021 | 90905211 |
В этой статье описывается модуль в конструкторе Машинное обучение Azure.
Используйте этот модуль, чтобы удалить потенциальные дубликаты из набора данных.
Например, предположим, что данные выглядят следующим образом и представляют несколько записей для пациентов.
| патиентид | Инициалы | пол; | возраст; | Допуск |
|---|---|---|---|---|
| 1 | ф.м. | M | 53 | Январь |
| 2 | ф.а.м. | M | 53 | Январь |
| 3 | ф.а.м. | M | 24 | Январь |
| 3 | ф.м. | M | 24 | Февраль |
| 4 | ф.м. | M | 23 | Февраль |
| ф.м. | M | 23 | ||
| 5 | ф.а.м. | M | 53 | |
| 6 | ф.а.м. | M | не число | |
| 7 | ф.а.м. | M | не число |
Очевидно, что в этом примере есть несколько столбцов с потенциально повторяющимися данными. Действительно ли они дублируются, зависит от ваших знаний о данных.
-
Например, может быть известно, что многие пациентов имеют одинаковое имя. Вы не исключите дубликаты с помощью столбцов имени, а только столбца идентификаторов . Таким образом отфильтровываются только строки с повторяющимися значениями идентификатора независимо от того, имеют ли пациентов имена.
-
Кроме того, можно разрешить дублирование в поле ID и использовать другое сочетание файлов для поиска уникальных записей, таких как имя, фамилия, возраст и пол.
Чтобы задать критерии для того, является ли строка дубликатом, укажите один столбец или набор столбцов для использования в качестве ключей. Две строки считаются повторяющимися, только если значения во всех ключевых столбцах равны. Если в любой строке отсутствуют значения для ключей, они не будут считаться повторяющимися строками. Например, если пол и Age заданы в качестве ключей в приведенной выше таблице, строки 6 и 7 не будут содержать повторяющихся строк, в которых отсутствует значение Age.
При запуске модуля он создает набор данных-кандидат и возвращает набор строк, не имеющий дубликатов в наборе указанных столбцов.
[!IMPORTANT] Исходный набор данных не изменяется; Этот модуль создает новый набор данных, который фильтруется для исключения дубликатов на основе указанных критериев.
Использование удаления повторяющихся строк
-
Добавьте модуль в конвейер. Модуль Удаление повторяющихся строк можно найти в разделе Преобразование данных, Обработка.
-
Подключите набор данных, который необходимо проверить на наличие повторяющихся строк.
-
В области Свойства в разделе выражение фильтра выбора ключевых столбцов щелкните запустить селектор столбцов, чтобы выбрать столбцы, используемые при обнаружении дубликатов.
В этом контексте ключ не означает уникальности идентификатора. Все столбцы, выбранные с помощью селектора столбцов, назначаются в качестве ключевых столбцов. Все невыбранные столбцы считаются неключевыми столбцами. Сочетание столбцов, выбранных в качестве ключей, определяет уникальность записей. (Представьте, что это инструкция SQL, использующая несколько екуалитиес соединений.)
Примеры:
- «Я хочу убедиться, что идентификаторы уникальны: выберите только столбец ИДЕНТИФИКАТОРов.
- "Я хочу убедиться, что сочетание имени, фамилии и идентификатора уникально": выбрать все три столбца.
-
Установите флажок хранить первую строку , чтобы указать, какая строка должна возвращаться при обнаружении дубликатов:
- Если этот флажок установлен, возвращается первая строка и другие отбрасываются.
- Если снять этот флажок, последняя повторяющаяся строка будет сохранена в результатах, а другие будут удалены.
-
Отправьте конвейер.
-
Чтобы просмотреть результаты, щелкните правой кнопкой мыши модуль и выберите визуализировать.
[!TIP] Если результаты сложно понять или вы хотите исключить некоторые столбцы из рассмотрения, можно удалить столбцы с помощью модуля Выбор столбцов в наборе данных .
Дальнейшие действия
Ознакомьтесь с набором доступных модулей в службе Машинного обучения Azure.
Шпаргалка по "Информатике"
Выполнение требований нормализации обеспечивает построение реляционной БД без дублирования данных и возможность поддержания целостности при внесении изменений.
При проектировании реляционной базы данных необходимо решить
вопрос о наиболее эффективной структуре данных. Основные цели
проектирования:
обеспечить быстрый доступ к данным
исключить ненужное повторение данных, которое является причиной
ошибок при вводе и нерационального
вашего компьютера;
обеспечить целостность данных таким
одних объектов автоматически происходило соответствующее
связанных с ними объектов.
Процесс уменьшения избыточности
называется нормализацией. В теории нормализации базы данных
разработаны достаточно формализованные подходы к
обладающих сложной структурой на несколько таблиц.
Теория нормализации структуры
формами таблиц. Каждая следующая нормальная форма должна
удовлетворять требованиям предыдущей формы и некоторым
дополнительным условиям. Ограничимся рассмотрением первых трех
нормальных форм, поскольку при практическом проектировании баз данных
четвертая и пятая формы используются в редких случаях.
В качестве примера рассмотрим таблицу
Таблица 7. Структура таблицы Продажи
№ Наименование
1 Код клиента
2 Фамилия
3 Имя
4 Отчество
5 Телефон
6 Факс
10 Адрес
11 Предприятие
12 Руководитель
13 Кредит
14 Примечание
15 Код товара
16 Дата заказа
17 Заказано
18 Дата продажи
19 Продано
20 Цена
21 Примечание к заказу
22 Категория
23 Наименование товара
Таблицу Продажи можно рассматривать как однотабличную базу
данных. Основная проблема заключается в том, что в ней содержится
значительное количество повторяющейся информации. Например, сведения
о покупателе повторяются для каждого сделанного им заказа. Такая
структура данных является причиной следующих проблем, возникающих
при работе с базой данных:
значительные затраты времени на ввод
Например, для всех заказов, сделанных одним из покупателей, придется
каждый раз вводить одни и те же данные о покупателе;
при изменении адреса или телефона покупателя необходимо
корректировать все записи, содержащие сведения о заказах этого покупателя;
наличие повторяющейся информации
увеличению размера базы данных. В результате снизится скорость
выполнения запросов. Кроме того, повторяющиеся данные нерационально
используют дисковое пространство вашего компьютера;
любые внештатные ситуации потребуют значительного времени для
получения требуемой информации. Например, при больших размерах таблиц
поиск ошибок будет занимать значительное время.
2.1. Первая нормальная форма
Табл. 7 является ненормализованной
Требования к таблице в первой нормальной форме:
1. Таблица не должна иметь
2. В таблице должны
Для выполнения условия пункта 2 каждая таблица должна иметь
первичный ключ. Таблица Продажи (табл. 7) не содержит первичного
ключа, что допускает наличие в ней повторяющихся записей. Для
выполнения условия 2 добавим поле Код клиента, которое будет содержать
значение первичного ключа.
Требование 1 постулирует устранение
Поскольку каждый покупатель может сделать несколько
которых в свою очередь может содержать несколько
две таблицы. Каждая запись одной таблицы будет содержать сведения об
одном из покупателей, а второй таблицы – информацию о каждом заказе.
Поэтому надо разбить таблицу Продажи на две отдельные таблицы
Клиенты и Заказы и определить поля Код клиента в качестве ключей
связи. Структуры таблиц Клиенты и Заказы приведены на рис.1. Тип связи
между таблицами Клиенты и Заказы будет один-ко-многим.
Таким образом, для таблицы Клиенты решена проблема
повторяющихся групп полей.
Клиенты
1 ∞
Код клиента
Фамилия
Имя
Отчество
Телефон
Таблица Заказы содержит сведения о товарах, включенных в
конкретный заказ. Для исключения повторяющихся записей можно
воспользоваться одним из способов:
1) добавить в таблицу новое уникальное ключевое поле Код заказа, что
позволит однозначно идентифицировать каждый из
работе с Ms Access это далеко не лучший метод, так как при разработке
многотабличных форм и отчетов связь между таблицами осуществляется
посредством ключевых полей с совпадающими значениями;
2) использовать уникальный составной ключ, состоящий из полей Код
клиента, Код товара и Дата заказа.
После того как мы разделили
ключевые поля в каждой таблице, таблицы Клиенты и Заказы находятся в
первой нормальной форме (рис.1).
Структура связей между таблицами
2.2. Вторая нормальная форма
Таблица находится во второй
она удовлетворяет условиям первой нормальной формы;
любое неключевое поле однозначно
ключевых полей, входящих в составной ключ.
Из приведенного выше определения следует, что понятие второй
нормальной формы применимо только к таблицам, имеющим составной
ключ. В рассматриваемом примере такой таблицей является таблица Заказы,
в которой составной ключ образуют поля Код клиента, Код товара и Дата
заказа. Она является таблицей во второй нормальной форме, поскольку поля
Категория, Наименование товара и Цена однозначно определяются только
одним из ключевых полей (Код товара).
Для приведения таблицы ко второй нормальной форме выделим из
таблицы Заказы таблицу Товары, которая будет содержать информацию о
товарах каждого типа. Для связывания таблиц Заказы и Товары
используется поле Код товара.
Клиенты Заказы
1 ∞
Код клиента Код клиента ∞ Код товара
Фамилия Код товара
Имя Дата заказа Наименование товара
Отчество Заказано
Телефон Дата продажи
Факс Продано
Индекс Цена
Страна Примечание к заказу
Город
Адрес
Предприятие
Руководитель
Кредит
Примечание
2.3. Третья нормальная форма
Таблица находится в третьей
удовлетворяет условиям второй нормальной формы; ни одно из неключевых
полей таблицы не идентифицируется с помощью другого неключевого поля.
Обратимся к таблице Клиенты. Поле
содержит имена руководителей компаний, которые однозначно определяются
значением поля Предприятие. Поскольку неключевое поле Руководитель
однозначно определяется другим неключевым полем Предприятие, таблица
Клиенты не является таблицей в третьей нормальной форме.
Для приведения ее к третьей
Предприятие
Клиенты Заказы Товары
1 ∞ 1
Код клиента Код клиента Код товара
Фамилия Код товара Категория
Имя Дата заказа Наименование товара
Отчество Заказано
Телефон Дата продажи
Факс Продано
Индекс Цена
Страна Примечание к заказу
Город
Адрес
Предприятие ∞ Предприятие
Кредит 1
Постановление ЦИК России от 07.02.2018 N 138/1139-7 "О внесении изменений в Положение о Государственной системе регистрации (учета) избирателей, участников референдума в Российской Федерации и Регламент использования подсистемы "Регистр избирателей, участников референдума" Государственной автоматизированной системы Российской Федерации "Выборы"
ЦЕНТРАЛЬНАЯ ИЗБИРАТЕЛЬНАЯ КОМИССИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ПОСТАНОВЛЕНИЕ
от 7 февраля 2018 г. N 138/1139-7
О ВНЕСЕНИИ ИЗМЕНЕНИЙ
В ПОЛОЖЕНИЕ О ГОСУДАРСТВЕННОЙ СИСТЕМЕ РЕГИСТРАЦИИ (УЧЕТА)
ИЗБИРАТЕЛЕЙ, УЧАСТНИКОВ РЕФЕРЕНДУМА В РОССИЙСКОЙ ФЕДЕРАЦИИ
И РЕГЛАМЕНТ ИСПОЛЬЗОВАНИЯ ПОДСИСТЕМЫ "РЕГИСТР ИЗБИРАТЕЛЕЙ,
УЧАСТНИКОВ РЕФЕРЕНДУМА" ГОСУДАРСТВЕННОЙ АВТОМАТИЗИРОВАННОЙ
СИСТЕМЫ РОССИЙСКОЙ ФЕДЕРАЦИИ "ВЫБОРЫ"
На основании статей 16 и 21 Федерального закона "Об основных гарантиях избирательных прав и права на участие в референдуме граждан Российской Федерации" Центральная избирательная комиссия Российской Федерации постановляет:
1. Внести в Положение о Государственной системе регистрации (учета) избирателей, участников референдума в Российской Федерации, утвержденное постановлением Центральной избирательной комиссии Российской Федерации от 6 ноября 1997 года N 134/973-II (в редакции постановления Центральной избирательной комиссии Российской Федерации от 29 декабря 2005 года N 164/1084-4, с изменениями, внесенными постановлениями Центральной избирательной комиссии Российской Федерации от 19 ноября 2008 года N 138/1017-5, от 22 декабря 2010 года N 232/1517-5, от 19 февраля 2014 года N 218/1416-6 и от 19 апреля 2017 года N 80/696-7), следующие изменения:
1) дополнить пунктом 2.5.8 следующего содержания:
"2.5.8. Регистрацией по месту жительства за пределами соответствующей территории на основании сообщения, поступившего с КСА ИКСРФ ГАС "Выборы" либо КСА ЦИК России ГАС "Выборы".";
2) пункт 2.6.2 изложить в следующей редакции:
"2.6.2. Регистрацией по новому месту жительства в пределах этой территории.";
3) дополнить пунктом 3.7.11 следующего содержания:
"3.7.11. Регистрацией по месту жительства за пределами соответствующей территории на основании сообщения, поступившего с КСА ИКСРФ ГАС "Выборы" либо КСА ЦИК России ГАС "Выборы" при отсутствии сведений о снятии с регистрационного учета, предусмотренного пунктом 3.7.2.";
4) дополнить пунктом 3.7.12 следующего содержания:
"3.7.12. Регистрацией по новому месту жительства в пределах этой территории.";
5) пункт 3.9 изложить в следующей редакции:
"3.9. Контроль за полнотой и корректностью сведений о гражданах, переданных главой местной администрации и вводимых в базу данных, осуществляет избирательная комиссия субъекта Российской Федерации в соответствии с регламентом.
При выявлении некорректных сведений избирательная комиссия субъекта Российской Федерации незамедлительно направляет информацию об этом главе местной администрации (главам местных администраций) для проверки. Проверка проводится в течение 10 дней с момента получения информации.
Результаты проверки включаются главой местной администрации в очередные сведения, передаваемые в избирательную комиссию субъекта Российской Федерации в соответствии с пунктом 2.14 настоящего Положения.";
6) пункт 3.9.1 изложить в следующей редакции:
"3.9.1. В случае если при контроле базы данных на КСА ТИК ГАС "Выборы" были выявлены сведения о гражданах, срок отбывания наказания которых истек более шести месяцев назад, то избирательная комиссия субъекта Российской Федерации направляет сведения об этих гражданах главе местной администрации для проверки и уточнения их места жительства. Проверка осуществляется в порядке, установленном пунктом 3.9 настоящего Положения. При подтверждении по результатам проверки нахождения места жительства на территории данного муниципального образования гражданин включается в число избирателей, участников референдума этого муниципального образования, и избирательной комиссией субъекта Российской Федерации вносятся соответствующие изменения в территориальный фрагмент Регистра.
В случае если при контроле базы данных на КСА ИКСРФ ГАС "Выборы" были выявлены повторяющиеся записи, включенные в разные территориальные фрагменты Регистра, на КСА ТИК ГАС "Выборы", в территориальном фрагменте Регистра которого содержатся сведения о регистрации гражданина по месту жительства с более ранней датой регистрации, направляется сообщение о регистрации гражданина по месту жительства за пределами соответствующей территории.
В случае если при контроле базы данных на КСА ИКСРФ ГАС "Выборы" были получены сведения о смене места жительства гражданином, ранее признанным судом недееспособным, в пределах одного субъекта Российской Федерации, то сведения об этом направляются на КСА ТИК ГАС "Выборы" по новому месту жительства гражданина в соответствии с регламентом.";
7) пункт 3.10 изложить в следующей редакции:
"3.10. Изменения соответствующего регионального фрагмента базы данных передаются избирательной комиссией субъекта Российской Федерации на КСА ЦИК России ГАС "Выборы" в порядке и сроки, предусмотренные регламентом, но не реже чем один раз в три месяца.
При получении указанных изменений регионального фрагмента на КСА ЦИК России ГАС "Выборы" проводится контроль корректности сведений о гражданах, введенных в базу данных, в соответствии с регламентом.
Информация о выявленных некорректных сведениях незамедлительно направляется в избирательную комиссию субъекта Российской Федерации (избирательные комиссии субъектов Российской Федерации) для проверки в порядке, предусмотренном пунктом 3.9 настоящего Положения.
В случае если при контроле базы данных на КСА ЦИК России ГАС "Выборы" были выявлены повторяющиеся записи, включенные в разные территориальные фрагменты Регистра, через КСА ИКСРФ ГАС "Выборы" на КСА ТИК ГАС "Выборы", в территориальном фрагменте Регистра которого содержатся сведения о регистрации гражданина по месту жительства с более ранней датой регистрации, направляется сообщение о регистрации гражданина по месту жительства за пределами соответствующей территории.".
2. Внести в Регламент использования подсистемы "Регистр избирателей, участников референдума" Государственной автоматизированной системы Российской Федерации "Выборы", утвержденный постановлением Центральной избирательной комиссии Российской Федерации от 26 марта 2014 года N 223/1437-6, следующие изменения:
1) пункт 2.2.2 изложить в следующей редакции:
"2.2.2. КСА ИКСРФ ГАС "Выборы" в части:
сведений о событиях, произошедших с гражданами Российской Федерации, зарегистрированными по месту жительства на территории (части территории) соответствующего муниципального образования, находившимися во время совершения события вне этой территории;
сообщений о регистрации гражданина по месту жительства за пределами соответствующей территории;
сведений о смене места жительства гражданином, ранее признанным судом недееспособным;
ведущихся на уровне КСА ИКСРФ ГАС "Выборы" и КСА ЦИК России ГАС "Выборы" классификаторов, справочников и словарей Подсистемы.";
2) в пункте 2.7 слова ", а также на основании повторяющихся записей, поступивших с КСА ИКСРФ ГАС "Выборы"," исключить;
3) дополнить пунктом 2.16 следующего содержания:
"2.16. При получении с КСА ИКСРФ ГАС "Выборы" либо с КСА ЦИК России ГАС "Выборы" сообщения о регистрации гражданина, включенного в территориальный фрагмент Регистра, по месту жительства за пределами соответствующей территории системный администратор КСА ТИК ГАС "Выборы" вносит соответствующие изменения в территориальный фрагмент базы данных.";
4) пункт 3.6 изложить в следующей редакции:
"3.6. Не реже чем один раз в три месяца на КСА ИКСРФ ГАС "Выборы" производится автоматизированный контроль данных на наличие повторяющихся записей.
В случае если при контроле базы данных на КСА ИКСРФ ГАС "Выборы" были выявлены повторяющиеся записи, включенные в разные территориальные фрагменты Регистра, на КСА ТИК ГАС "Выборы", в территориальном фрагменте Регистра которого содержатся сведения о регистрации гражданина по месту жительства с более ранней датой регистрации, направляется сообщение о регистрации гражданина по месту жительства за пределами соответствующей территории.";
5) пункт 4.5 изложить в следующей редакции:
"4.5. Не реже чем один раз в три месяца после обработки изменений региональных фрагментов базы данных в части сведений об избирателях, участниках референдума на КСА ЦИК России ГАС "Выборы" производится автоматизированный контроль данных на наличие повторяющихся записей.
В случае если при контроле базы данных на КСА ЦИК России ГАС "Выборы" были выявлены повторяющиеся записи, включенные в разные территориальные фрагменты Регистра, через КСА ИКСРФ ГАС "Выборы" на КСА ТИК ГАС "Выборы", в территориальном фрагменте Регистра которого содержатся сведения о регистрации гражданина по месту жительства с более ранней датой регистрации, направляется сообщение о регистрации гражданина по месту жительства за пределами соответствующей территории.".
3. Опубликовать настоящее постановление в официальном печатном органе Центральной избирательной комиссии Российской Федерации - журнале "Вестник Центральной избирательной комиссии Российской Федерации" и официальном сетевом издании "Вестник Центральной избирательной комиссии Российской Федерации".
Председатель
Центральной избирательной комиссии
Российской Федерации
Э.А.ПАМФИЛОВА
Секретарь
Центральной избирательной комиссии
Российской Федерации
М.В.ГРИШИНА
Поиск и удаление дубликатов
Иногда повторяющиеся данные полезны, иногда они просто делают данные менее читаемыми. Используйте условное форматирование, чтобы найти и выделить повторяющиеся данные. Это позволяет вам просмотреть дубликаты и решить, хотите ли вы их удалить.
-
Выберите ячейки, которые вы хотите проверить на наличие дубликатов.
Примечание. Excel не может выделить дубликаты в области значений отчета сводной таблицы.
-
Нажмите Главная > Условное форматирование > Правила выделения ячеек > Повторяющиеся значения .
-
В поле рядом с Значения с использованием выберите форматирование, которое вы хотите применить к повторяющимся значениям, а затем нажмите OK .
Удалить повторяющиеся значения
При использовании функции Удалить дубликаты повторяющиеся данные будут безвозвратно удалены. Перед удалением дубликатов рекомендуется создать копию исходных данных на другом листе, чтобы предотвратить случайную потерю данных.
-
Выберите диапазон ячеек, содержащий повторяющиеся значения, которые вы хотите удалить.
-
Щелкните Данные > Удалить дубликаты , а затем в разделе Столбцы установите или снимите флажки для столбцов, дубликаты которых вы хотите удалить.
Например, на этом листе столбец января содержит информацию о ценах, которую я хочу сохранить.
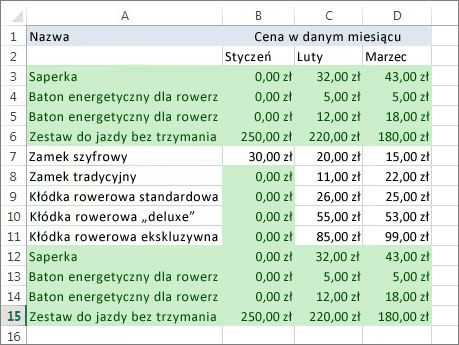
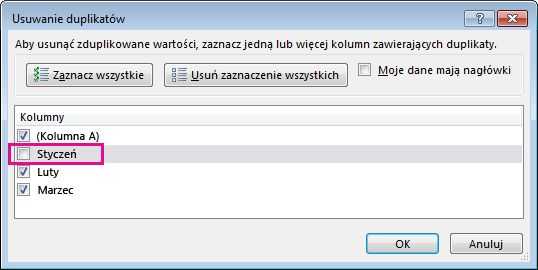
Поэтому поле Январь в окне Удалить Дубликаты оставлено неотмеченным.
-
Нажмите кнопку OK .
Фильтр для поиска повторяющихся значений и их удаления
Удаление повторяющихся значений влияет только на значения в выбранном диапазоне ячеек или таблицы. Любые значения вне диапазона ячеек или таблицы не изменяются и не перемещаются. Поскольку данные удаляются навсегда, имеет смысл скопировать исходный диапазон ячеек или таблицу на другой лист или книгу, прежде чем удалять повторяющиеся значения.
Примечание: Повторяющиеся значения не могут быть удалены из данных, которые зачеркнуты или имеют частичные значения.Чтобы удалить дубликаты, вы должны сначала удалить как схему, так и промежуточный итог.
-
Выберите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
-
На вкладке Данные в группе Данные нажмите Удалить дубликаты .
-
Установите один или несколько флажков, относящихся к столбцам в таблице, а затем щелкните Удалить дубликаты .
Совет: Если диапазон ячеек или таблица содержит несколько столбцов и вы хотите выбрать только несколько столбцов, снимите флажок Выбрать все и выберите только нужные столбцы.
DEV.CDur - Удаление дубликатов из таблицы без ключа
Я много раз сталкивался с таблицами, содержащими несколько записей. Бывает, что это запланированное и желательное явление. Но что, если мы не хотим, чтобы это произошло? Самый простой способ настроить уникальный ключ.
Легко сказать, сложнее сделать. Невозможно настроить ключ, если мы сначала не удалим дубликаты. Я представлю некоторые методы, которые можно использовать. Это оба простых решения, обычно самые медленные, более или менее сложные, но более эффективные, некоторые требуют больше усилий и требуют определенных допущений.Но давайте к делу.
Пример испытаний
Тестовая таблица будет простой. Однако показанные решения можно расширить для работы с более сложными таблицами. Ниже приведен скрипт создания нашего полигона:
CREATE TABLE Duplicates(
ID int,
Name varchar (10)
)
INSERT INTO Duplicates
VALUES (1, 'A'), (2, 'B'), (2, 'B'),
(3 , 'В'), (3, 'В'), (3, 'В'), (4, 'Г'), (1, 'Е')
Простая таблица с двумя столбцами и повторяющимися значениями.Дважды встречается пара 2-B и трижды пара 3-C. Именно от этих значений мы и будем избавляться. Посмотрим внимательнее на таблицу:
Промежуточная таблица и двукратное копирование данных
Первое решение очень простое. Сначала мы создаем временную таблицу с той же схемой и копируем в нее данные из исходной таблицы с помощью оператора DISTINCT. Второй шаг — очистить повторяющуюся таблицу, а третий шаг — скопировать данные обратно в исходную таблицу.Наконец, просто уберите за собой и удалите временную таблицу. Полный скрипт представлен ниже:
--Временная таблица и завершение данных с начала
SELECT DISTINCT * INTO #temp FROM Duplicates
TRUNCATE TABLE Duplicates
INSERT INTO Duplicates SELECT * FROM #temp
DROP TABLE #temp
Простое, но неэффективное решение. Допустим, в таблице с миллионом записей есть дубликаты, а дубликатов несколько или несколько десятков.В чем дело? Один миллион записей копируется дважды (почти миллион во второй раз). К счастью, это не единственное решение.
Переименовать таблицу и скопировать DISTINCT
Одной копии можно избежать. Так как? Название, наверное, уже все объяснило. На этот раз процедура состоит из трех шагов. Первый — переименовать исходную таблицу. Второй — скопировать в целевую таблицу, которая — правильно — примет имя старой исходной таблицы. Третий этап – очистка.Сценарий показан в следующем листинге:
--Изменение имени вместо создания новой таблицы
- Вместо двух операций копирования выполнить одну
EXEC sp_rename 'Duplicates', 'Duplicates_Temp';
SELECT DISTINCT * INTO Duplicates FROM Duplicates_Temp
DROP TABLE Duplicates_Temp
Однако по-прежнему существует проблема копирования всего содержимого и очистки всего лишнего. Можно ли это сделать по-другому?
Адрес записи и ее уникальное местоположение
Мы знаем это, потому что изначально предполагалось, что записи не имеют уникального ключа.Так как же однозначно указать, что мы хотим удалить первую пару 2-В, не трогая вторую, или вторую, не трогая первую? Традиционный дисплей для этого не подходит, потому что 2-B это 2-B. Это не то, как мы можем это отличить. Однако нужно знать, что каждая из этих записей лежит где-то на диске, в каком-то файле, в каком-то месте хранения. Эту информацию можно извлечь, используя скрытый столбец %%physloc %%. Теперь осталось только решить, какие из одинаковых записей оставить. В представленном ниже сценарии я оставляю тот, у которого самый низкий адрес.В решении я использовал инструкцию GROUP BY и агрегатную функцию MIN. Я включил весь сценарий в следующий список:
--Использование идентификатора строки (RID)
--Каждая запись имеет собственный уникальный адрес
УДАЛИТЬ D
ИЗ Дубликаты D
ЛЕВОЕ СОЕДИНЕНИЕ
(
SELECT ID, Name, MIN (%% physloc %%) AS [RID]
FROM Дубликаты
СГРУППИРОВАТЬ ПО ID, Имя
) T
ON T.RID = D.%%physloc%%
ГДЕ T.RID IS NULL
Если GROUP BY находит больше записей, остается та, у которой наименьший (минимальный, самый низкий) адрес.LEFT JOIN, выполняемый после того, как адреса вернут NULL, где адрес не является минимальным (когда запись одна, ее адрес минимален, когда их больше - только один может быть минимальным). Этот ничтожный NULL решает все.
Каждый раз, когда я вижу ЛЕВОЕ СОЕДИНЕНИЕ или ПРАВОЕ СОЕДИНЕНИЕ, я задаюсь вопросом, можно ли его превратить в обычное соединение. LEFT/RIGHT JOIN пытается сопоставить все записи и возвращает NULL, если совпадений нет. Это делает обрабатываемые коллекции больше.Можно ли здесь исключить LEFT JOIN?
Ликвидация ЛЕВОГО СОЕДИНЕНИЯ
Конечно. Вы можете напрямую удалить те записи, у которых все поля совпадают, но которые отличаются именно этим минимальным адресом. Модифицированный скрипт показан ниже:
--Использование идентификатора строки (RID)
— Обратное соединение, СОЕДИНЕНИЕ гораздо эффективнее
— эффективнее, чем СОЕДИНЕНИЕ ВЛЕВО, требует столбцов соединения
УДАЛИТЬ D
ИЗ Дубликатов D
СОЕДИНИТЬ
(
SELECT ID, Name, MIN (% % physloc % %) AS [RID]
FROM Duplicates
GROUP BY ID, Name
) T
ON T.ID = D.ID AND T.Name = D.Name AND T.RID!= D.%%physloc%%
Оценка плана выполнения показывает, что JOIN может ускорить операцию в два раза. Однако точная оценка более сложна, поскольку она зависит от количества данных и количества повторяющихся записей. Я предоставляю читателям исследовать эту проблему.
Скрытый столбец %%physloc %% настолько скрыт, что даже не фигурирует в документации. Во-вторых, этот метод можно использовать только с SQL Server 2008.Это заставляет быть осторожным и, несмотря на несомненную полезность %%physloc%%, использовать его экономно. Вы никогда не знаете, не будет ли этот столбец потерян в будущих версиях или заменен каким-либо задокументированным эквивалентом.
Дублирующий и динамический TOP N
Заголовок может показаться некоторым загадкой, но скоро он прояснится. Метод очень эффективен, когда дубликатов немного. Во-вторых, нужен точный скрипт, потому что нужно динамически прилепить условие по всем столбцам.Прежде чем я перейду к правильному методу, следует дать несколько пояснений. Подавляющее большинство TOP N используется вместе с оператором SELECT. Мало кто знает, что вы можете использовать TOP N в операторах DELETE и UPDATE. Если мы хотим удалить записи, соответствующие заданным критериям, но только первые две, мы набираем:
УДАЛИТЬ TOP (2) ИЗ таблицы
При наличии большего количества записей, удовлетворяющих заданным условиям (в примере условий нет), остальные не будут удалены.
Аналогичные эффекты можно получить с помощью оператора SET ROWCOUNT N.
В отличие от %%physloc %%, представленное ниже решение использует только задокументированные функции.
--Динамическое удаление записей с использованием TOP (COUNT (*) - 1)
DECLARE @sql nvarchar (MAX) = ''
SELECT @ sql = @ sql + 'DELETE TOP (' + CAST (COUNT (*) - 1 as nvarchar(8))
+ ') FROM Duplicates WHERE AND Name =' '' + Name + '' '' + CHAR (10)
FROM Duplicates
GROUP BY ID, Name
HAVING COUNT (*) > 1
EXEC ( @sql)
Недостатком этого решения является достаточно сложный процесс написания скриптов и низкая читабельность, особенно при большом количестве столбцов в таблице.Это также неэффективно, когда в таблице много дубликатов.
CTE для нумерации дубликатов.
Это, пожалуй, самый лучший и универсальный способ удаления дубликатов, поэтому я оставил его напоследок. Выражения CTE обычно приравниваются к рекурсии. Это немного несправедливо, потому что по определению они предназначены для выражения общих выражений в таблице. Хитрость заключается в том, что выражение неявно передает записи оператору SELECT, используя это выражение.Это похоже на передачу ссылки за пределы того, что было перечислено в CTE. Какое это имеет отношение к удалению?
К каждой записи мы добавим по одному столбцу, который будет следующим номером той же записи (одинаковым в смысле значений в столбцах). Для нумерации будем использовать функцию ROW_NUMBER() split (PARTITION) на основе всех столбцов. Каждая такая группа будет иметь свою нумерацию. Логично, что мы будем удалять те записи, у которых число больше 1. Давайте рассмотрим пример скрипта с использованием выражения CTE:
WITH RD AS
(SELECT ROW_NUMBER () OVER (РАЗДЕЛЕНИЕ ПО ИМЕНИ, ID ORDER BY (SELECT 1)) Row,
ID, Name FROM Duplicates)
DELETE FROM RD
WHERE RD.Строка> 1
Может показаться странным, что в скрипте есть фрагмент: ORDER BY (SELECT 1). Синтаксис ROW_NUMBER() требует метода сортировки для определения порядка нумерации. Нас не волнует такой порядок внутри одной группы одинаковых записей. Более того, сортировка — это всегда усилия для базы и пустая трата времени. Чтобы немного обмануть синтаксис, который не допускает здесь константы, вы можете поместить туда вот такое простое выражение.
Как я уже говорил, CTE передает что-то вроде ссылки, известной из других языков программирования.Предполагается, что объект тот же (значения), но другой (ссылка на другой адрес). Никаких объединений, временных таблиц и очистки после себя.
Резюме
Следует сделать некоторые выводы. Единственное, о чем я могу думать, так это о том, что одну проблему можно решить разными способами. Я призываю вас искать. Не всегда то, что кажется очевидным (временная таблица), является лучшим решением. Это работает, но именно потому, что это работает, это мешает нам найти другие решения.Каждый из них имеет свои преимущества и недостатки, и каждый может лучше подходить для конкретных случаев. Я подозреваю, что не рассмотрел все методы удаления дубликатов. Не стесняйтесь делиться своими методами и идеями в комментариях.
Категория: SQL Server
.Excel - как удалить дубликаты?
Одной из наиболее распространенных проблем, с которыми сталкиваются пользователи Excel, являются повторяющиеся, повторяющиеся значения. Если наличие дубликатов на данном листе нежелательно, это может быть связано либо с чисто человеческим фактором, либо с некачественным импортом данных из внешнего источника.
Такие дубликаты могут исказить полученные результаты и затруднить работу с такой таблицей.К счастью, Microsoft предусмотрела эту ситуацию, и в Excel у нас есть несколько инструментов, которые могут помочь нам избавиться от ненужных повторений. Они здесь:
Инструмент удаления дубликатов
Первый способ удаления дубликатов — использование специального инструмента, созданного именно для этой цели. Находим их на вкладке Данные — Инструменты данных — Удалить дубликаты . Для этого сначала выбираем столбец, в котором мы хотим искать и удалять дубликаты.
Условное форматирование
Удаление всех повторов одним щелчком мыши — не всегда самое разумное решение.Другой, более трудоемкий, но более безопасный способ обнаружения дубликатов — применение условного форматирования. Таким образом, мы сможем подсвечивать дубликаты в листе, чтобы легче было определить, нужны они или нет.
Для этого выберите область, которую вы хотите найти, перейдите на вкладку Главная - Условное форматирование - Правила выделения ячеек и выберите опцию Дублировать значения .Затем выберите цвет для форматирования и подтвердите. Как видите, все повторы отмечены и можно переходить к их дальнейшему анализу.
Фильтрация
Третье решение — одна из основных функций Excel — фильтрация данных. Как и условное форматирование, этот метод не удаляет дубликаты. В то время как форматирование показало нам дубликаты, фильтрация их скроет, оставив только уникальные записи.
Чтобы использовать фильтрацию, нам нужно убедиться, что у наших столбцов есть заголовки, иначе фильтрация не будет работать.Затем мы помещаем курсор в любое место в области данных. Чтобы включить фильтр, мы должны перейти в категорию Данные и выбрать Дополнительно в группе Сортировка и фильтрация.
В появившемся окне нам нужно выбрать опцию Только уникальные записи . Когда мы нажмем OK , наш лист будет отфильтрован. Это видно по тому, что нумерация строк данных выделена синим цветом, а строки, содержащие повторяющиеся данные, скрыты.
Вот три чрезвычайно простых способа удалить, найти или скрыть дубликаты в нашей таблице данных. Каждый из этих методов будет применяться к разным сценариям, поэтому их можно использовать взаимозаменяемо.
Вам нравится эта статья? Поделись с другими!
.Как удалить повторяющиеся записи?
Удаление В этом посте я разберу проблему удаления повторяющихся записей.
Есть много решений этой проблемы. Я решил представить три разных решения и сравнить их в разных сценариях. Я проверил эти три метода в двух разных случаях.
В первом случае у нас есть неиндексированная таблица с двумя столбцами. Первый столбец — это идентификатор, а второй — случайное числовое значение.Эта таблица содержит 100 000 записей, которые повторяются. Из-за случайности я точно не знаю, сколько существует повторяющихся записей? Наша задача их убрать.
Во втором случае у нас есть временная таблица с 4 столбцами. Идентификатор, Имя, Фамилия и Номер. Записей в таблице всего 11. Они генерируются не случайным образом, поэтому результат операции всегда будет одинаковым, независимо от того, какой метод мы используем. Мы также четко знаем, сколько записей повторяется, в этом случае мы хотим удалить записи с одинаковым именем, фамилией и номером.
Оба случая содержат столбцы NOT NULL и имеют автоматически увеличивающийся идентификатор.
Первый случай — случайная неиндексированная таблица
Вот простой SQL-запрос, который создаст временную таблицу со случайным значением в одном столбце. После каждой попытки тестового удаления таблицу необходимо удалять и создавать заново.
CREATE TABLE RandomRowsTable (ID INT IDENTITY, значение INT) ЕМУ ОБЪЯВИТЬ @a INT УСТАНОВИТЬ @a = 1 ПОКА @a <100000 НАЧАЛО ВСТАВИТЬ В RandomRowsTable (Значение) ЗНАЧЕНИЯ (ПРЕОБРАЗОВАТЬ (INT, RAND () * 1000)) НАБОР @а = @а + 1 КОНЕЦ GO Чтобы подтвердить наличие повторяющихся записей, я сделал простой запрос, содержащий предложение Group by.
SELECT count(Value), Value FROM dbo.[RandomRowsTable] GROUP BY Value
Как видите, повторяющихся записей довольно много, их количество больше 100. Неудивительно, ведь мы создали 100 000 записей , который должен содержать числа от 0 до 1000.
Самый простой способ удаления не требует знания SQL.
УДАЛИТЬ t1 ИЗ dbo.RandomRowsTable AS t1, dbo.RandomRowsTable AS t2 ГДЕ t1.value = t2.value И т1.идентификатор> t2.id SELECT count (Value), Value FROM dbo.[RandomRowsTable] GROUP BY Value Мы даем нашей одной таблице два разных псевдонима, чтобы мы могли ссылаться на нее дважды в этом запросе. Проверяем, равно ли числовое значение значению той же таблицы. Во время этого запроса он будет просканирован дважды. Нам также нужно добавить условие, связанное с идентификатором таблицы, чтобы удалять только записи выше этой записи, которую мы не хотим удалять.
Как я и предполагал, план запроса показал два сканирования одной и той же таблицы, а затем сравнение результатов..
Это самый простой метод, и, как вы могли ожидать, он не так эффективен.
Второй метод требует использования ключевых слов " Over and Partition by ". Они доступны не во всех системах баз данных.
;С Цез ТАК КАК ( SELECT ROW_NUMBER () OVER (PARTITION BY Value ЗАКАЗАТЬ ПО (ВЫБРАТЬ 0)) RN / * Сообщение 4112, уровень 15, состояние 1, строка 2 Функция ROW_NUMBER должна иметь предложение OVER с ORDER BY.* / ИЗ dbo.RandomRowsTable ) УДАЛИТЬ ИЗ Ces ГДЕ РН>1 SELECT count (Value), Value FROM dbo.[RandomRowsTable] GROUP BY Value Этот запрос намного сложнее предыдущего. Используя слово «С», он сохраняет содержимое запроса, который группирует повторяющиеся значения.
Запись с row_number больше 1 является повторяющейся записью. Так что удаляем записи, где это значение больше.
Этот запрос должен быть оптимальным, так как выполняется только одно сканирование таблицы.Большая часть работы над запросом была потрачена на сортировку (85%). У таблицы нет индекса, поэтому, естественно, процесс сортировки 100 000 записей в данном случае довольно болезненный.
Статистика показывает, что этот запрос хуже предыдущего, но я убежден, что размещение индекса для столбца «Значение» ускорило бы этот запрос в несколько раз. Делая это решение победителем. Это также требует наименьшего объема памяти, чем другие решения.
Третий запрос использует механизм LEFT OUTER JOIN.
УДАЛИТЬ dbo.RandomRowsTable ИЗ dbo.RandomRowsTable ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ MIN (Id) как идентификатор, значение ИЗ dbo.RandomRowsTable СГРУППИРОВАТЬ ПО значению ) как KeepRows ON dbo.RandomRowsTable.Id = KeepRows.Id КУДА KeepRows.Id имеет значение NULL SELECT count (Value), Value FROM dbo.[RandomRowsTable] GROUP BY Value Это решение снова требует двойного сканирования таблицы. Это решение должно быть самым неэффективным.
Это решение потребляет больше всего памяти и времени. Однако меня беспокоит «Расчетная стоимость оператора», которая является самой низкой из всех других запросов.
Мне также было интересно, влияет ли количество повторяющихся записей на скорость запроса, но разницы почти нет.
Решил провести еще один кейс, так как индекс , случайность записей и количество повторяющихся столбцов могут повлиять на результат этого теста.
Второй кейс - временная таблица
Второй кейс работает на временной таблице с небольшим количеством записей, они постоянны при каждой попытке проверки моих запросов, так что тут не должно быть проблем с поиском победителя.
СОЗДАТЬ ТАБЛИЦУ #RandomTable ( ID INT не нулевой идентификатор (1,1) первичный ключ, Имя VARCHAR (2048) НЕ NULL, Фамилия VARCHAR (4096) НЕ NULL, Число INT НЕ NULL ) ВСТАВИТЬ В #RandomTable (Имя, Фамилия, Номер) ВЫБЕРИТЕ 'Адам', 'Павлоц', 10 ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'Адам', 'Павлоц', 10 ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'Адам', 'Павлоц', 10 ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'Адам', 'Павлоц', 10 ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'Франко', 'Миконер', 15 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Франко', 'Миконер', 15 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Франко', 'Миконер', 15 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Доман', 'Психомировски', 20 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Доман', 'Психомировски', 20 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Доман', 'Психомировски', 20 СОЮЗ ВСЕХ ВЫБЕРИТЕ 'Здзислав', 'БохатерГалактики', 30 УДАЛИТЬ t1 ИЗ #RandomTable AS t1, #RandomTable AS t2 ГДЕ t1.Имя = t2.Имя И t1.Фамилия = t2.Фамилия И t1.Номер = t2.Номер И t1.id> t2.id ВЫБРАТЬ * ИЗ #RandomTable DROP TABLE #RandomTable В плане запроса у нас есть « Clustered Index Scan », что означает, что временные таблицы индексируются по умолчанию, что также повлияет на результаты наших запросов.
Тем не менее, таблица сканируется дважды, что негативно сказывается на этом запросе, но это тоже не самый плохой результат.
Время для решения OUTER LEFT JOIN.
УДАЛИТЬ #RandomTable ИЗ #RandomTable ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ MIN (Id) как Id, Имя, Фамилия, Номер ИЗ #RandomTable СГРУППИРОВАТЬ ПО Имени, Фамилии, Номеру ) как KeepRows ON # RandomTable.Id = KeepRows.Id КУДА KeepRows.Id IS NULL Здесь вы можете ясно увидеть серьезное падение производительности, а также невероятно длинный план запроса.
Количество столбцов для проверки повторяемости оказывает разрушительное влияние на результат этого запроса. В данном случае это худшее решение.
Наконец, у нас есть решение от OVER PARTITION.
С КТЭ AS (SELECT ROW_NUMBER () OVER (РАЗДЕЛЕНИЕ ПО Имени, Фамилии, Номеру ЗАКАЗАТЬ ПО (ВЫБРАТЬ 0)) RN ИЗ #RandomTable) УДАЛИТЬ ИЗ КТЭ WHERE RN>1 Сортировка значительно ускорена за счет того, что временная таблица индексируется.
В конечном итоге этот запрос является победителем, поскольку он имеет наименьшее значение в « Оценочная стоимость поддерева ».
Кроме того, этот запрос никак не зависит от первичного ключа таблицы. В данном случае его может и не быть.
Количество проверяемых столбцов почти не влияет на этот запрос.
Я не специалист по базам данных, но я хотел хоть раз поиграть в профи, который сможет определить, какой запрос эффективнее, а какой менее. Как видите, это непростая задача. Поэтому я надеюсь, что вам понравился этот пост, и вы с радостью примете несколько хороших предложений по оптимизации этих запросов.
.Найти повторяющиеся значения в таблице SQL
Попробуйте это:
объявить таблицу @YourTable (id int, имя varchar (10), электронная почта varchar (50)) ВСТАВЬТЕ @YourTable ЗНАЧЕНИЯ (1, 'Джон', 'Джон-электронная почта') ВСТАВЬТЕ @YourTable ЗНАЧЕНИЯ (2, 'Джон', 'Джон-электронная почта') ВСТАВЬТЕ @YourTable VALUES (3, 'fred', 'John-email') ВСТАВЬТЕ @YourTable ЗНАЧЕНИЯ (4, 'fred', 'fred-email') ВСТАВЬТЕ @YourTable ЗНАЧЕНИЯ (5, 'sam', 'sam-email') ВСТАВЬТЕ @YourTable ЗНАЧЕНИЯ (6, 'sam', 'sam-email') ВЫБРАТЬ имя, электронная почта, COUNT (*) AS CountOf ОТ @YourTable СГРУППИРОВАТЬ ПО имени, электронной почте СЧЕТЧИК (*) > 1 Выход:
имя электронная почта CountOf ---------- ----------- ----------- Джон Джон-электронная почта 2 электронная почта 2 (затронуты 2 строки) Если вы хотите дублировать идентификаторы, используйте это:
ВЫБОР у.id, y.name, y.email ОТ @YourTable y ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ имя, электронная почта, COUNT (*) AS CountOf ОТ @YourTable СГРУППИРОВАТЬ ПО имени, электронной почте СЧЕТЧИК (*) > 1 ) dt ON y.name = dt.name AND y.email = dt.email Выход:
идентификатор имя электронная почта ----------- ---------- ------------ 1 Джон Джон-электронная почта 2 Джон Джон-электронная почта 5 одно и то же письмо 6 тот же адрес электронной почты (затронуты 4 строки) Чтобы удалить дубликаты, попробуйте:
УДАЛИТЬ д ОТ @YourTable d ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ у.id, y.name, y.email, ROW_NUMBER () OVER (PARTITION BY y.name, y.email ORDER BY y.name, y.email, y.id) AS RowRank ОТ @YourTable y ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ имя, электронная почта, COUNT (*) AS CountOf ОТ @YourTable СГРУППИРОВАТЬ ПО имени, электронной почте СЧЕТЧИК (*) > 1 ) дт НА у.имя = dt.name И y.email = dt.email ) dt2 ON d.id = dt2.id ГДЕ dt2.RowRank!=1 ВЫБЕРИТЕ * ИЗ @YourTable Выход:
идентификатор имя электронная почта ----------- ---------- -------------- 1 Джон Джон-электронная почта 3 Фред Джон-электронная почта 4 Фред Фред-Эмейл 5 одно и то же письмо (затронуты 4 строки) .MS Access - удаление дубликатов из баз
Господин Кароль, я бы сделал так:
У нас есть таблица данных:
Строим первый запрос
Группа:
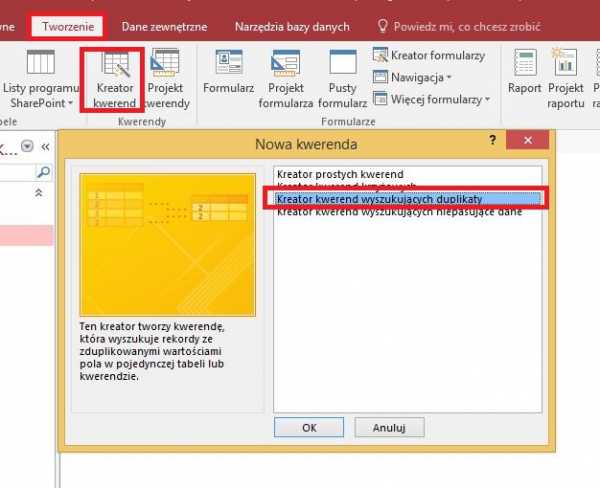
Мы выбираем таблицу, на которой мы удаляем дубликаты, а затем:
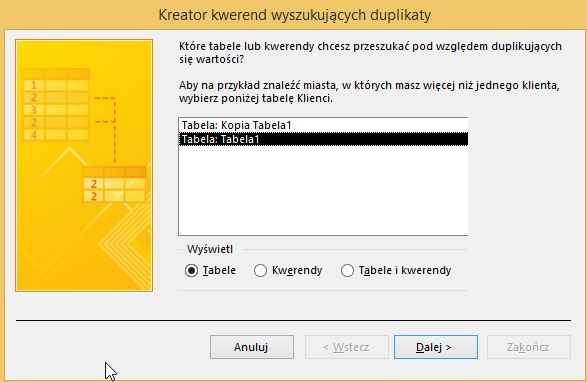
Выбираем поля таблицы где ищем дубликаты и далее:
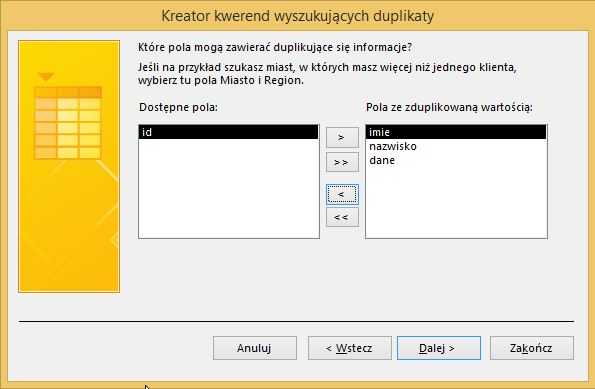
Добавляем столбец, где у нас есть уникальные значения и далее:
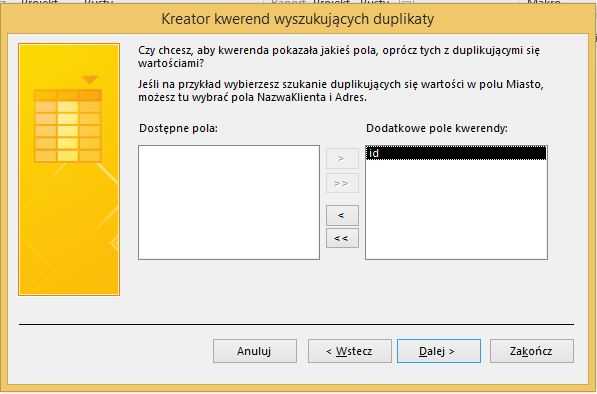
Назовем запрос как-нибудь разумно:
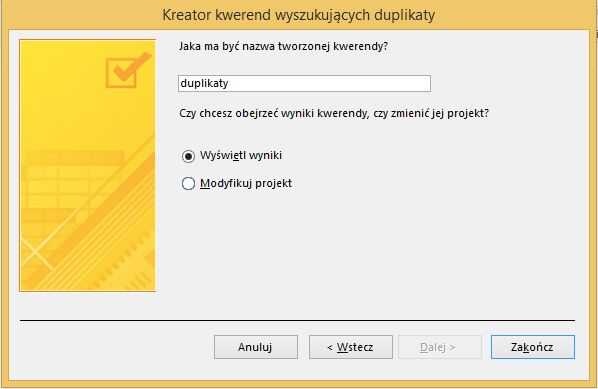
Запрос отображает ВСЕ записи, в которых интересующие данные дублируются
Здесь мы могли бы закончить и заменить этот запрос на удаление, но он удалит для нас ВСЕ найденные записи.
Предполагаю, что мы хотим удалить только последующие вхождения и оставить одну уникальную запись из найденных.
Мы продолжаем это делать.
Следующий запрос.
Мы создаем новый запрос, источником которого являются дубликаты нашего предыдущего запроса здесь:
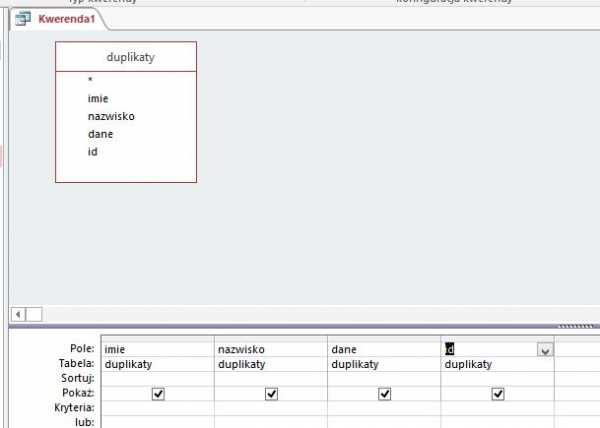
Мы делаем это итоговым запросом.
Веб-дизайн Сумма:
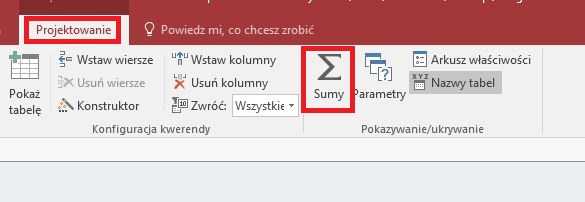
Мы меняем запись в столбце id на First:
Сохраните под каким-нибудь разумным именем, здесь будет duplicats_first.
Переоткрываем и переходим к просмотру SQL:
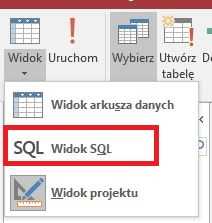
Имена суммирующих столбцов автоматически переименовываются (звучат немного странно), в косметических целях и в то же время для облегчения вашей работы меняем название на более простое
До модификации:
После изменения (в данном случае я оставил имя id):
Закрываем и сохраняем изменения.
У нас есть запрос, отображающий первое вхождение повторяющихся записей, мы хотим удалить оставшиеся вхождения.
Мы создаем еще один запрос.
Его источником являются два предыдущих запроса:
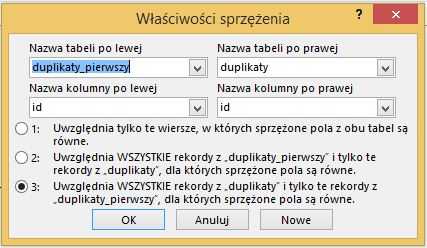
Соединяем эти запросы после поля id и переходим к свойству соединения:
90 140
Установите свойства как на картинке ниже:
В запросе выбираем столбцы как показано на фото ниже:
Результат запроса:
Нас интересуют только те идентификаторы, которых нет в запросе Duplicats_prim.
Итак, в режиме проектирования мы добавляем критерий null:
Результат запроса:
Просто для того, чтобы столбец id в запросе duplicas_prim не отображался:
Закрываем, сохраняем, здесь будет until_removed.
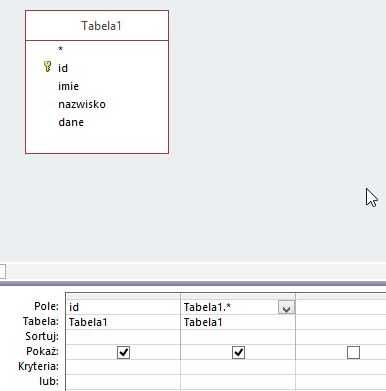
Мы создаем еще один запрос.
Источником для него будет таблица, из которой мы хотим удалить дубликаты.
Столбцы как на картинке ниже:
Меняем запрос на удаление - Лента Дизайн - Удалить:
Внешний вид запроса:
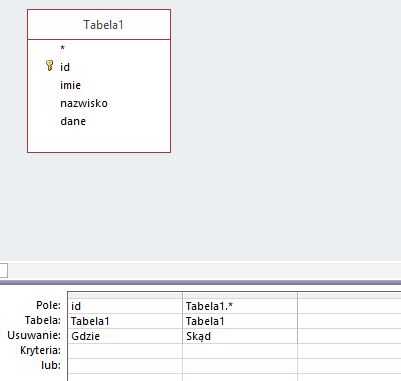
Введите критерии в столбце идентификатора и введите его (вы можете использовать конструктор).
DLookUp("id"; "do_delete"; "id =" & [Table1]! [Id])
Вот ссылка, показывающая, как работает dlookup:
https://support.office.com/pl-pl/article/Funkcja-DLookup-8896cb03-e31f-45d1-86db-bed10dca5937
Сохраняем запрос (здесь имя удалить).
В базе данных есть копия таблицы для тестирования.
См. прикрепленный файл.
шт. Можно, наверное, и в самом sql написать, к сожалению я его слишком мало знаю... все же. :)
Приложения
-
аккдб
Удаление дубликатов accdb (576K)




Видео-курс
