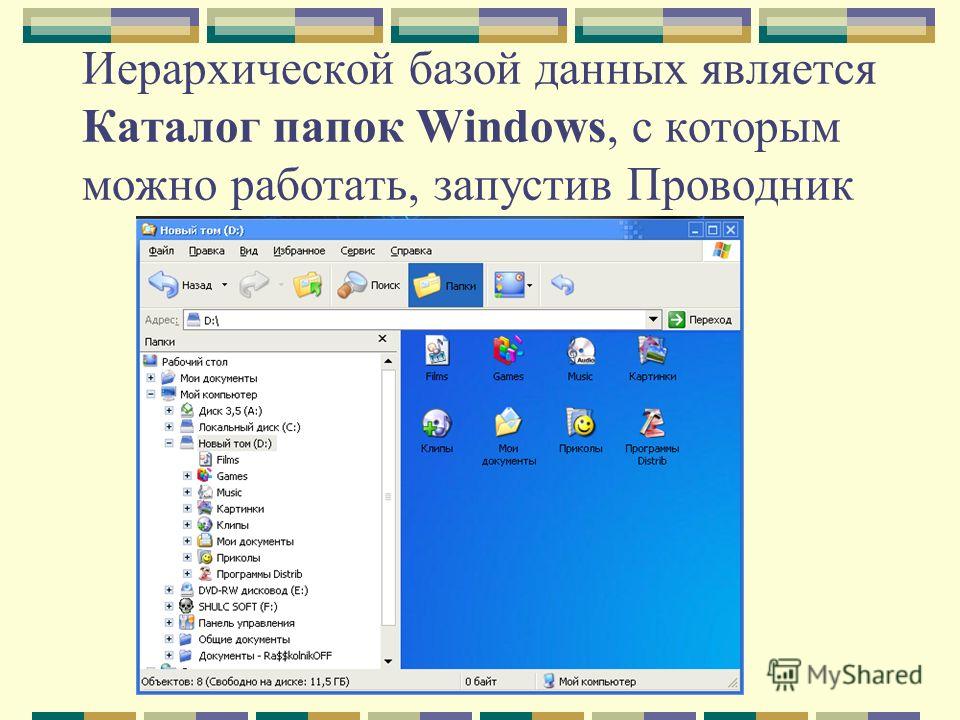
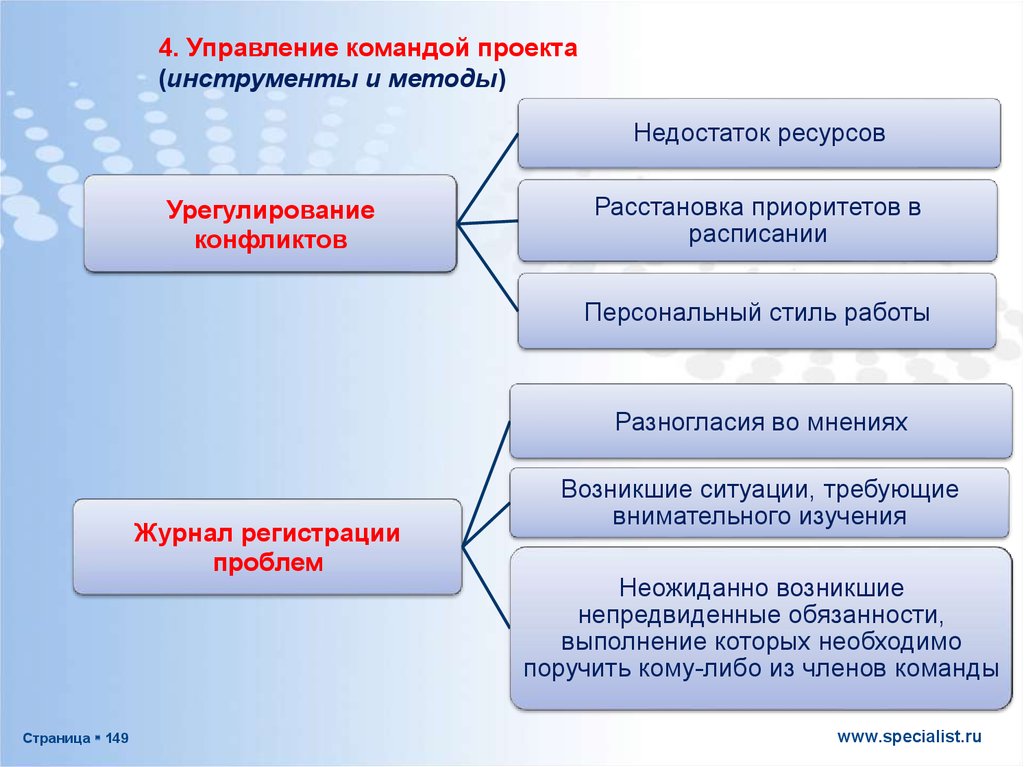
К командам управления данными относятся
НОУ ИНТУИТ | Лекция | Введение в структурированный язык запросов SQL
< Лекция 18 || Лекция 1: 12345
Аннотация: Дается определение структурированного языка запросов SQL. Вводится понятие базы данных, реляционной базы данных, СУБД. Определяется место языка SQL в разработке информационных систем, организованных на основе технологии клиент-сервер. Приводится классификация команд SQL: определение структуры базы данных, манипулирование данными, выборка данных, управление данными, команды администрирования данных и управления транзакциями. Дается описание учебной базы данных.
Ключевые слова: деятельность, база данных, СУБД, Internet, реляционная БД, технология клиент-сервер, запрос, таблица, строка, столбец, первичный ключ, реляционная связь, отношение подчиненности, стандарт языка, SQL, реализация языка, ANSI, сервер, операции, доступ, серверный процесс, клиент, рабочая станция, синтаксис, архитектура, intranet, представление данных, тип команды, управление доступом, администрирование, DCL, data manipulation language, запись, диск, чтение данных, Локальные БД, интерактивный запрос, ПО, внедрение операторов SQL, процедурный язык, информация, remote, Data, RDA, специализированная реализация, transaction, processing, OLTP-технология, принятия решений, OLAP-технология, мультимедиа, конструкция языка, зарезервированное слово, значение, идентификатор, операторы, метаязык, формулы Бэкуса-Науэра, предметной области, покупатель, товар, модель данных, отношение, один-ко-многим, фирма, тип сущности, определение, экземпляр сущности, артикул товара, атрибут, поле
Основные понятия
Всякая профессиональная деятельность так или иначе связана с информацией, с организацией ее сбора, хранения, выборки. Можно сказать, что неотъемлемой частью повседневной жизни стали базы данных, для поддержки которых требуется некоторый организационный метод, или механизм. Такой механизм называется системой управления базами данных ( СУБД ). Итак, введем основные понятия.
База данных (БД) – совместно используемый набор логически связанных данных (и их описание), предназначенный для удовлетворения информационных потребностей организации.
СУБД (система управления базами данных ) – программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать базу данных, а также получать к ней контролируемый доступ.
Системы управления базами данных существуют уже много лет, многие из них обязаны своим происхождением системам с неструктурированными файлами на больших ЭВМ. Наряду с общепринятыми современными технологиями в области систем управления базами данных начинают появляться новые направления, что обусловлено требованиями растущего бизнеса, все увеличивающимися объемами корпоративных данных и, конечно же, влиянием технологий Internet.
Наряду с общепринятыми современными технологиями в области систем управления базами данных начинают появляться новые направления, что обусловлено требованиями растущего бизнеса, все увеличивающимися объемами корпоративных данных и, конечно же, влиянием технологий Internet.
Реляционные базы данных
Управление основными потоками информации осуществляется с помощью так называемых систем управления реляционными базами данных, которые берут свое начало в традиционных системах управления базами данных. Именно объединение реляционных баз данных и клиент-серверных технологий позволяет современному предприятию успешно управлять собственными данными, оставаясь конкурентоспособным на рынке товаров и услуг.
Реляционные БД имеют мощный теоретический фундамент, основанный на математической теории отношений. Появление теории реляционных баз данных дало толчок к разработке ряда языков запросов, которые можно отнести к двум классам:
- алгебраические языки, позволяющие выражать запросы средствами специализированных операторов, применяемых к отношениям;
- языки исчисления предикатов, представляющие собой набор правил для записи выражения, определяющего новое отношение из заданной совокупности существующих отношений. Следовательно, исчисление предикатов есть метод определения того отношения, которое желательно получить как ответ на запрос из отношений, уже имеющихся в базе данных.
В реляционной модели объекты реального мира и взаимосвязи между ними представляются с помощью совокупности связанных между собой таблиц (отношений).
Даже в том случае, когда функции СУБД используются для выбора информации из одной или нескольких таблиц (т.е. выполняется запрос ), результат также представляется в табличном виде. Более того, можно выполнить запрос с применением результатов другого запроса.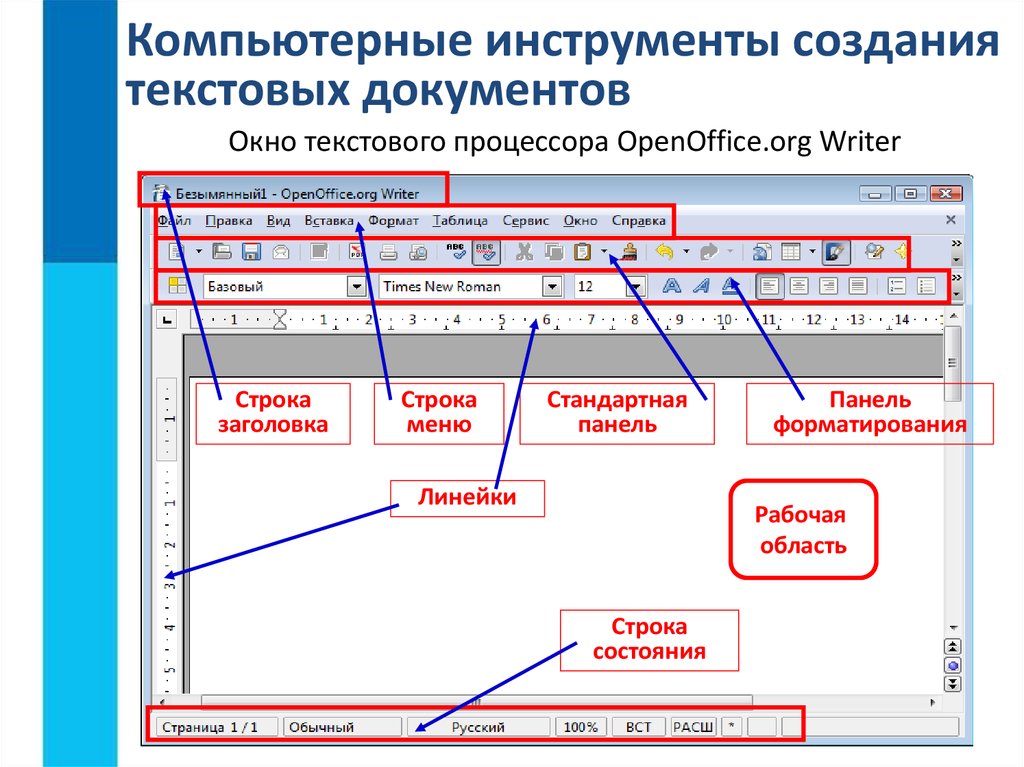
Каждая таблица БД представляется как совокупность строк и столбцов, где строки (записи) соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы (поля) – атрибутам (признакам, характеристикам, параметрам) объекта, события, явления.
В каждой таблице БД необходимо наличие первичного ключа – так именуют поле или набор полей, однозначно идентифицирующий каждый экземпляр объекта или запись. Значение первичного ключа в таблице БД должно быть уникальным, т.е. в таблице не допускается наличие двух и более записей с одинаковыми значениями первичного ключа. Он должен быть минимально достаточным, а значит, не содержать полей, удаление которых не отразится на его уникальности.
Реляционные связи между таблицами баз данных
Связи между объектами реального мира могут находить свое отражение в структуре данных, а могут и подразумеваться, т. е. присутствовать на неформальном уровне.
е. присутствовать на неформальном уровне.
Между двумя или более таблицами базы данных могут существовать отношения подчиненности, которые определяют, что для каждой записи главной таблицы (называемой еще родительской) возможно наличие одной или нескольких записей в подчиненной таблице (называемой еще дочерней).
Выделяют три разновидности связи между таблицами базы данных:
- "один–ко–многим";
- "один–к–одному";
- "многие–ко–многим".
Отношение "один–ко–многим"
Отношение "один–ко–многим" имеет место, когда одной записи родительской таблицы может соответствовать несколько записей дочерней. Связь "один–ко–многим" иногда называют связью "многие–к–одному". И в том, и в другом случае сущность связи между таблицами остается неизменной. Связь "один–ко–многим" является самой распространенной для реляционных баз данных. Она позволяет моделировать также иерархические структуры данных.
Связь "один–ко–многим" является самой распространенной для реляционных баз данных. Она позволяет моделировать также иерархические структуры данных.
Отношение "один–к–одному"
Отношение "один–к–одному" имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней. Это отношение встречается намного реже, чем отношение "один–ко–многим". Его используют, если не хотят, чтобы таблица БД "распухала" от второстепенной информации, однако для чтения связанной информации в нескольких таблицах приходится производить ряд операций чтения вместо одной, когда данные хранятся в одной таблице.
Отношение "многие–ко–многим"
Отношение "многие–ко–многим" применяется в следующих случаях:
- одной записи в родительской таблице соответствует более одной записи в дочерней;
- одной записи в дочерней таблице соответствует более одной записи в родительской.

Всякую связь "многие–ко–многим" в реляционной базе данных необходимо заменить на связь "один–ко–многим" (одну или более) с помощью введения дополнительных таблиц.
Дальше >>
< Лекция 18 || Лекция 1: 12345
SQL команды - Команды языка определения данных DDL, Команды языка управления данными DCL, Команды языка управления транзакциями TCL, Команды языка манипулирования данными DML
Выделяют следующие группы команд SQL:
Команды языка определения данных
Команды языка определения данных DDL (Data Definition Language, язык определения данных) - это подмножество SQL, используемое для определения и модификации различных структур данных.
К данной группе относятся команды предназначенные для создания, изменения и удаления различных объектов базы данных. Команды CREATE (создание), ALTER (модификация) и DROP (удаление) имеют большинство типов объектов баз данных (таблиц, представлений, процедур, триггеров, табличных областей, пользователей и др.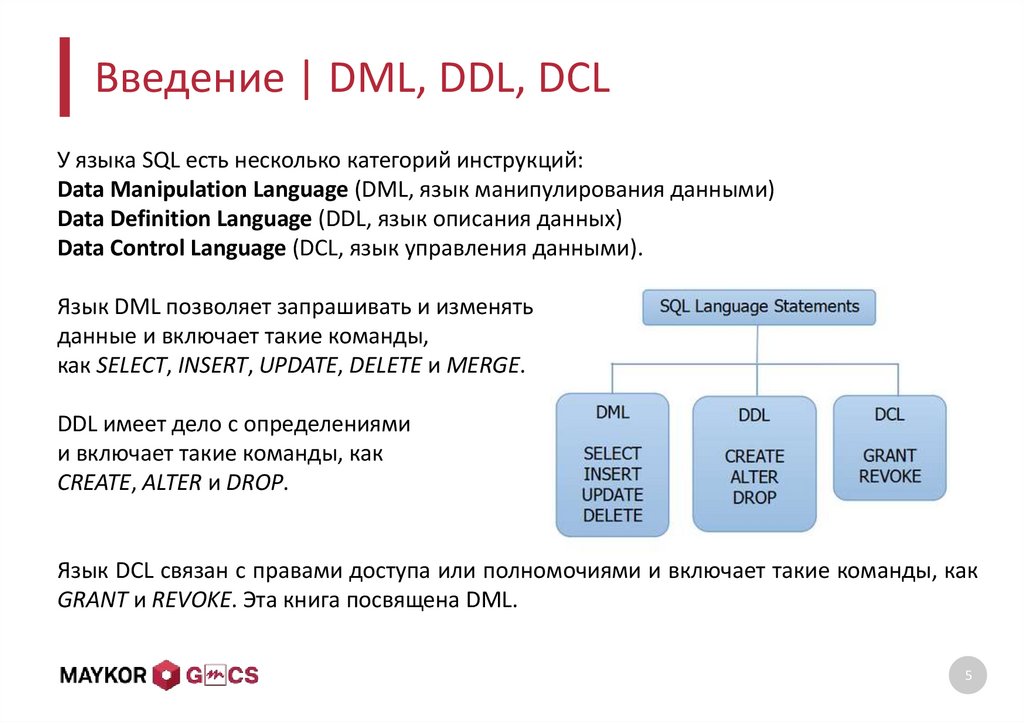 ). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
Некоторым кажется, что применение DDL является прерогативой администраторов базы данных, а операторы DML должны писать разработчики, но эти два языка не так-то просто разделить. Сложно организовать аффективный доступ к данным и их обработку, не понимая, какие структуры доступны и как они связаны. Также сложно проектировать соответствующие структуры, не зная, как они будут обрабатываться.
Команды языка управления данными
С помощью команд языка управления данными ( DCL (Data Control Language) ) можно управлять доступом пользователей к базе данных. Операторы управления данными включают в себя применяемые для предоставления и отмены полномочий команды GRANT и REVOKE, а также команду SET ROLE, которая разрешает или запрещает роли для текущего сеанса.
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции.
Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.
Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.
COMMIT - заканчивает ("подтверждает") текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.
ROLLBACK - выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией.
Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных.
В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т. е. в целостном состоянии.
е. в целостном состоянии.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Команды языка манипулирования данными
Команды языка манипулирования данными DML (Data Manipulation Language) позволяют пользователю перемещать данные в базу данных и из нее:
- INSERT — осуществляет вставку строк в таблицу.
- DELETE — осуществляет удаление строк из таблицы.
- UPDATE — осуществляет модификацию данных в таблице.
- SELECT — осуществляет выборку данных из таблиц по запросу.
Каждый, кто работает с SQL в среде Oracle, должен вооружиться книгами: справочником по языку SQL, таким как «Oracle SQL: The Essential Reference? (O'Reilly), руководством по оптимизации производительности, например «Oracle SQL Tuning Pocket Reference» (O'Reilly).
Управление командами — Azure Data Explorer
- Статья
- 3 минуты на чтение
команды .show
команды .show возвращает таблицу с командами администратора, которые достигли конечного состояния. Эти команды доступны для запроса в течение 30 дней.
В таблице команд есть два столбца с данными о потреблении ресурсов для каждой выполненной команды.
- TotalCpu — общее тактовое время ЦП (пользовательский режим + режим ядра), потребляемое этой командой.
- ResourceUtilization — содержит всю информацию об использовании ресурсов, связанную с этой командой, включая TotalCpu.
Отслеживаемое потребление ресурсов включает обновления данных и любой запрос, связанный с текущей командой администратора. В настоящее время только некоторые из команд администратора охвачены таблицей команд (
В настоящее время только некоторые из команд администратора охвачены таблицей команд ( .ingest , .set , .append , .set-or-replace , .set-or-append ). Постепенно в таблицу команд будет добавлено больше команд.
- Администратор базы данных или монитор базы данных могут видеть любую команду, которая была вызвана в их базе данных.
- Другие пользователи могут видеть только те команды, которые были вызваны ими.
Синтаксис
.show команды
Пример
| Идентификатор активности клиента | Тип команды | Текст | База данных | Начато | Последнее обновление: | Продолжительность | Состояние | Идентификатор корневой активности | Пользователь | Причина отказа | Приложение | Директор | Всего ЦП | Использование ресурсов | Группа рабочей нагрузки |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KD2RunCommand;a069f9e3-6062-4a0e-aa82-75a1b5e16fb4 | Объединение экстентов | . merge асинхронные операции ... merge асинхронные операции ... | ДБ1 | 2017-09-05 11:08:07.5738569 | 2017-09-05 11:08:09.1051161 | 00:00:01.5312592 | Завершено | b965d809-3f3e-4f44-bd2b-5e1f49ac46c5 | Идентификатор приложения AAD = 5ba8cec2-9a70-e92c98cad651 | Кусто.Azure.DM.Svc | аадапп = 5ba8cec2-9a70-e92c98cad651 | 00:00:03.5781250 | { "ScannedExtentsStatistics": { "MinDataScannedTime": null, "MaxDataScannedTime": null }, "CacheStatistics": { Память: { "Промахи": 2, "Попадания": 20}, "Диск": { "Промахи" : 2, «Попадания»: 0 } }, «Пик памяти»: 159620640, "Всего ЦП": "00:00:03.5781250" } | внутренний | |
| KE.RunCommand; 710e08ca-2cd3-4d2d-b7bd-2738d335aa50 | DataIngestPull | .ingest в MyTableName ... | ТестБД | 2017-09-04 16:00:37.0915452 | 2017-09-04 16:04:37.2834555 | 00:04:00.1919103 | Ошибка | а8986е9е-943ф-81б0270д6фае4 | cooper@fabrikam. com com | Соединение сокета удалено. | Кусто.Исследователь | aaduser=... | 00:00:00 | { "ScannedExtentsStatistics": { "MinDataScannedTime": null, "MaxDataScannedTime": null }, "CacheStatistics": { "Память": { "Промахи": 0, Попадания: 0}, "Диск": { "Промахи" : 0, "Hits": 0 } }, "MemoryPeak": 0, "TotalCpu": "00:00:00"} | по умолчанию |
| KD2RunCommand;97db47e6-93e2-4306-8b7d-670f2c3307ff | ExtentsRebuild | .merge асинхронные операции... | ДБ2 | 2017-09-18 13:29:38.5945531 | 2017-09-18 13:29:39.9451163 | 00:00:01.3505632 | Завершено | d5ebb755-d5df-4e94-b240-9accdf06c2d1 | Идентификатор приложения AAD = 5ba8cec2-9a70-e92c98cad651 | Кусто.Azure.DM.Svc | аадапп = 5ba8cec2-9a70-e92c98cad651 | 00:00:00.80 | { "ScannedExtentsStatistics": { "MinDataScannedTime": null, "MaxDataScannedTime": null }, "CacheStatistics": { Память: { "Промахи": 0, "Попадания": 1}, "Диск": { "Промахи" : 0, "Попадания": 0 } }, "MemoryPeak": 88828560, "TotalCpu": "00:00:00. 80"} 80"} | внутренний |
Пример. Извлечение определенных данных из столбца ResourceUtilization
Доступ к одному из свойств в столбце ResourceUtilization осуществляется путем вызова ResourcesUtilization.xxx (где xxx — имя свойства).
Примечание
ResourceUtilization — это динамический столбец. Чтобы работать с его значениями, вы должны сначала преобразовать его в определенный тип данных. Используйте функцию преобразования, такую как tolong , toint , totimespan .
Например,
.show commands | где CommandType == "TableAppend" | где Начал > назад (1 ч) | расширить MemoryPeak = tolong(ResourcesUtilization.MemoryPeak) | топ 3 по версии MemoryPeak по убыванию | проект StartedOn, MemoryPeak, TotalCpu, Text
| Начало работы | ПамятьПик | Всего ЦП | Текст |
|---|---|---|---|
2017-09-28 12:11:27. 8155381 8155381 | 800396032 | 00:00:04.5312500 | .append Server_Boots <| пусть bootStartsSourceTable = SessionStarts; ... |
| 2017-09-28 11:21:26.7304547 | 750063056 | 00:00:03.8218750 | .set-or-append WebUsage <| база данных('CuratedDB').WebUsage_v2 | резюмировать ... | проект... |
| 2017-09-28 12:16:17.4762522 | 676289120 | 00:00:00.0625000 | .set-or-append AtlasClusterEventStats с (...) <| Atlas_Temp (дата-время (2017-09)-28 12:13:28.7621737), дата и время(2017-09-28 12:14:28.8168492)) |
Исследование проблем с производительностью
Команды .show можно использовать для исследования проблем с производительностью, поскольку они показывают ресурсы, потребляемые каждой командой управления.
Следующие примеры представляют собой простые и полезные запросы для таких исследований.
Запрос к столбцу TotalCpu
10 запросов с наибольшим потреблением ЦП за последний день.
команды .show | где StartedOn > назад (1 дн.) | топ-10 по TotalCpu | проект StartedOn, CommandType, ClientActivityId, TotalCpu
Все запросы за последние 10 часов, для которых TotalCpu превысил 3 минуты.
команды .show | где StartedOn > назад (10 ч) и TotalCpu > 3 м | проект StartedOn, CommandType, ClientActivityId, TotalCpu | заказ по TotalCpu
Все запросы за последние 24 часа, для которых TotalCpu превысил 5 минут, сгруппированные по Пользователю и Принципалу.
команды .show | где StartedOn> назад (24 часа) | суммировать TotalCount=count(), CountAboveThreshold=countif(TotalCpu > 2m), AverageCpu = avg(TotalCpu), MaxTotalCpu=max(TotalCpu), (50th_Percentile_TotalCpu, 95th_Percentile_TotalCpu) = процентили (TotalCpu, 50, 95) по пользователю, основному | расширить PercentageAboveThreshold = strcat (подстрока (CountAboveThreshold * 100 / TotalCount, 0, 5), «%») | порядок по CountAboveThreshold desc | Пользователь проекта, Принципал, CountAboveThreshold, TotalCount, PercentageAboveThreshold, MaxTotalCpu, AverageCpu, 50th_Percentile_TotalCpu, 95th_Percentile_TotalCpu
Временная диаграмма: среднее значение ЦП, 95-й процентиль и максимальное значение ЦП.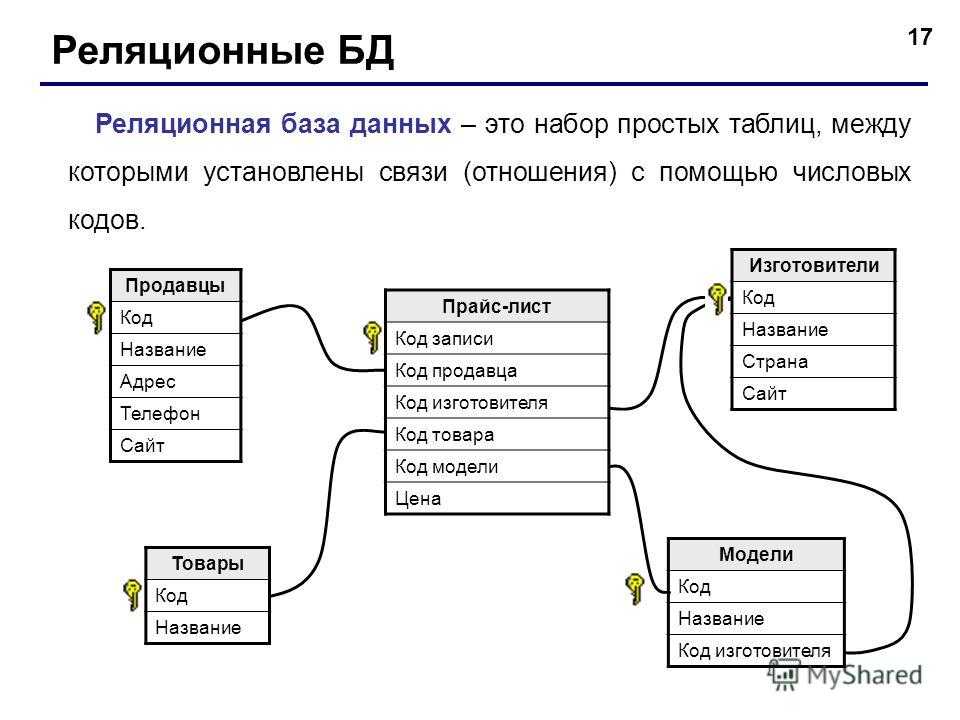
команды .show | где StartedOn > назад (1 дн.) | суммировать MaxCpu_Minutes=max(TotalCpu)/1m, 95th_Percentile_TotalCpu_Minutes=процентиль(TotalCpu, 95)/1м, AverageCpu_Minutes=avg(TotalCpu)/1м по ячейке(StartedOn, 1м) | визуализировать временную диаграмму
Запрос к MemoryPeak
10 самых популярных запросов за последний день с самыми высокими значениями MemoryPeak.
команды .show | где StartedOn > назад (1 дн.) | расширить MemoryPeak = tolong (ResourcesUtilization.MemoryPeak) | проект StartedOn, CommandType, ClientActivityId, TotalCpu, MemoryPeak | 10 лучших по версии MemoryPeak
Временная диаграмма среднего пика памяти по сравнению с 95-й процентиль против Max MemoryPeak.
команды .show | где StartedOn > назад (1 дн.) | проект MemoryPeak = tolong (ResourcesUtilization.MemoryPeak), StartedOn | суммировать Max_MemoryPeak=max(MemoryPeak), 95th_Percentile_MemoryPeak=процентиль(MemoryPeak, 95), Average_MemoryPeak=avg(MemoryPeak) по bin(StartedOn, 1m) | визуализировать временную диаграмму
Управление данными
Управление даннымиУправление данными
| В этом разделе:
|
 данные, вам может потребоваться изменить ваш сервер и файлы конфигурации связи. Первый шаг понимание того, как и где описываются данные, а также роли сервер и адаптеры в управлении потоком обработки.
данные, вам может потребоваться изменить ваш сервер и файлы конфигурации связи. Первый шаг понимание того, как и где описываются данные, а также роли сервер и адаптеры в управлении потоком обработки.  В этих разделах термин «таблица» относится как к базовым таблицы и представления в источниках данных. Мастер-файл описывает столбцы таблицы источника данных с использованием ключевых слов, разделенных запятыми формат. Файл доступа включает дополнительные параметры, которые завершают определение таблицы источника данных. Для некоторых адаптеров требуются оба файлов для выполнения запросов и создания DML для доступа к не-SQL источники данных.
В этих разделах термин «таблица» относится как к базовым таблицы и представления в источниках данных. Мастер-файл описывает столбцы таблицы источника данных с использованием ключевых слов, разделенных запятыми формат. Файл доступа включает дополнительные параметры, которые завершают определение таблицы источника данных. Для некоторых адаптеров требуются оба файлов для выполнения запросов и создания DML для доступа к не-SQL источники данных. 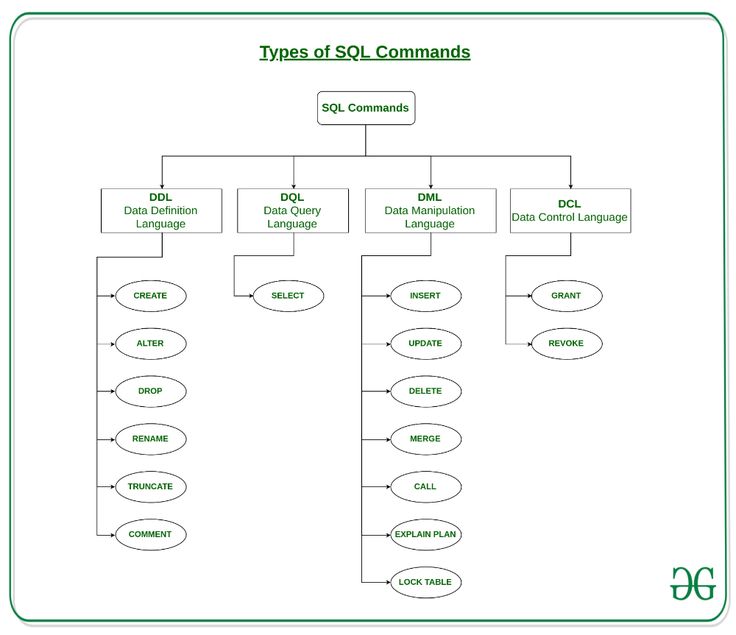

 Указание зарезервированного слова генерирует синтаксис ошибки.
Указание зарезервированного слова генерирует синтаксис ошибки. 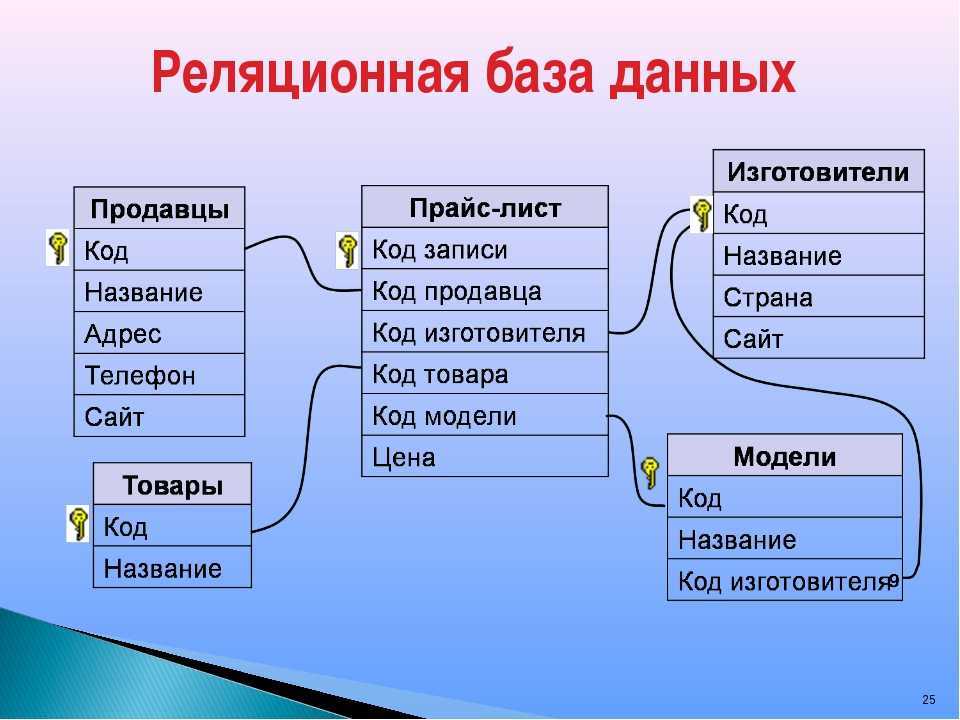 Имя файла должно начинаться с буквы и представлять содержимое таблицы или просмотра. Фактический файл должен иметь расширение .mas, но значение для этого атрибут не должен включать расширение. Имя файла без расширение .mas может состоять максимум из восьми буквенно-цифровых символов.
Имя файла должно начинаться с буквы и представлять содержимое таблицы или просмотра. Фактический файл должен иметь расширение .mas, но значение для этого атрибут не должен включать расширение. Имя файла без расширение .mas может состоять максимум из восьми буквенно-цифровых символов. 
 Он всегда имеет значение S0 (S ноль).
Он всегда имеет значение S0 (S ноль). 
 Имя должно начинаться с буквы. Специальные символы и встроенные пробелы не рекомендуются. Порядок объявлений полей в мастер-файле важно в отношении спецификации ключевых столбцов. Дополнительные сведения см. в разделе Первичный ключ.
Имя должно начинаться с буквы. Специальные символы и встроенные пробелы не рекомендуются. Порядок объявлений полей в мастер-файле важно в отношении спецификации ключевых столбцов. Дополнительные сведения см. в разделе Первичный ключ. 
 2, чтобы разрешить десятичная точка и возможный отрицательный знак.
2, чтобы разрешить десятичная точка и возможный отрицательный знак.  Например, столбец Спецификация, допускающая нулевые значения, используется там, где требуется столбец. не иметь значения в каждой строке (например, сумма повышения в таблице, содержащей данные о заработной плате).
Например, столбец Спецификация, допускающая нулевые значения, используется там, где требуется столбец. не иметь значения в каждой строке (например, сумма повышения в таблице, содержащей данные о заработной плате).  9
9 
 Остальные поля можно указать в любом заказ. В файле доступа атрибут KEYS завершает процесс. определения первичного ключа.
Остальные поля можно указать в любом заказ. В файле доступа атрибут KEYS завершает процесс. определения первичного ключа.  Он может состоять из от 1 до 48 символов. Вы не должны уточнять имя поля.
Он может состоять из от 1 до 48 символов. Вы не должны уточнять имя поля.  Выражение должен заканчиваться точкой с запятой, за которой следует знак доллара (;$).
Выражение должен заканчиваться точкой с запятой, за которой следует знак доллара (;$).  ВЫГОДА рассматривается как поле со значением, равным значению RETAIL_COST минус DEALER_COST.
ВЫГОДА рассматривается как поле со значением, равным значению RETAIL_COST минус DEALER_COST.  Это повлияет почти на все типы приложений, в том числе те, которые оформляют ипотечные кредиты, страховые полисы, юбилеи, облигации, пополнение запасов, договоры, аренда, пенсии, дебиторская задолженность, и записи клиентов.
Это повлияет почти на все типы приложений, в том числе те, которые оформляют ипотечные кредиты, страховые полисы, юбилеи, облигации, пополнение запасов, договоры, аренда, пенсии, дебиторская задолженность, и записи клиентов.  интерпретации века, если первые две цифры года не предоставляются:
интерпретации века, если первые две цифры года не предоставляются:  Предполагается, что любой двузначный год попадает в этот окно, и первые две цифры устанавливаются соответственно. Годы снаружи объявленное окно должно обрабатываться кодированием пользователя.
Предполагается, что любой двузначный год попадает в этот окно, и первые две цифры устанавливаются соответственно. Годы снаружи объявленное окно должно обрабатываться кодированием пользователя.  0004
0004 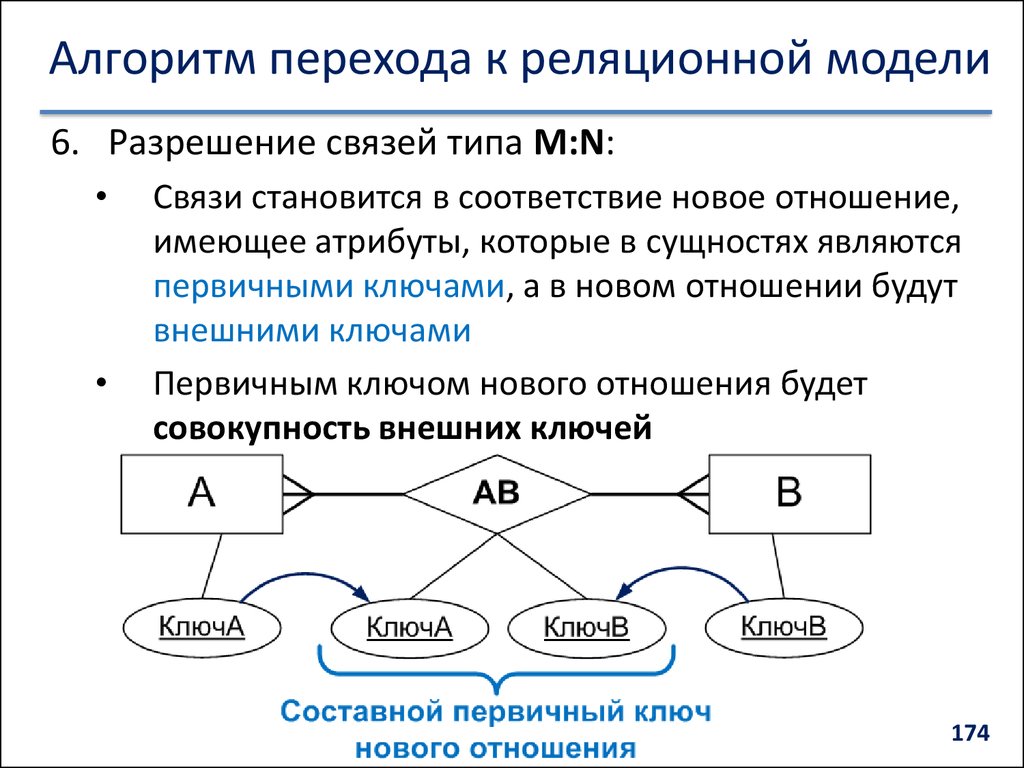 ДЕФЦЕНТ синтаксис
ДЕФЦЕНТ синтаксис