Найти среднеквадратичное отклонение
Разбираем формулы среднеквадратического отклонения и дисперсии в Excel | Методы анализа
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:
Например, у нас есть временной ряд - продажи по неделям в шт.
|
Неделя |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Отгрузка, шт |
6 |
10 |
7 |
12 |
6 |
14 |
8 |
13 |
10 |
14 |
Сморите пример расчета здесь: среднеквадратическое отклонние и дисперсия
Для этого временного ряда i=1, n=10, ,
Рассмотрим формулу среднего значения:
|
Неделя |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Отгрузка, шт |
6 |
10 |
7 |
12 |
6 |
14 |
8 |
13 |
10 |
14 |
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. 2))/(n-1)
=90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Скачать файл с примером
Рассмотрим еще один показатель, который в будущем нам понадобятся - дисперсия.
Дисперсия - квадрат среднеквадратического отклонения и отражает разброс данных относительно среднего.
Рассчитаем дисперсию:
Скачать файл с примером
Итак, теперь мы умеем рассчитывать среднеквадратическое отклонение и дисперсию в Excel. Надеемся, полученные знания пригодятся вам в работе.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite - автоматический расчет прогноза в Excel.

- 4analytics - ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition - BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO - прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Добавить комментарий
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т. е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.
Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.
В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
На практике формула стандартного отклонения следующая:
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.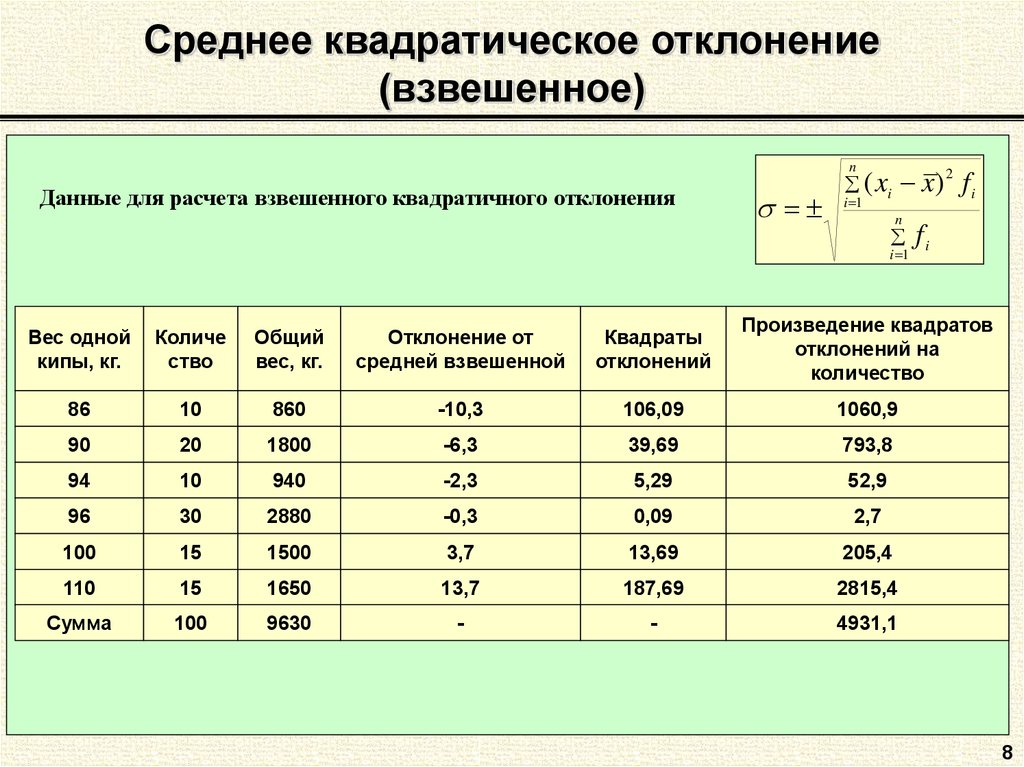 Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.
Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
Калькулятор стандартного отклонения
Использование калькулятора
Стандартное отклонение — это статистическая мера разнообразия или изменчивости в наборе данных. Низкое стандартное отклонение указывает на то, что точки данных обычно близки к среднему или среднему значению. Высокое стандартное отклонение указывает на большую изменчивость точек данных или более высокий разброс от среднего значения.
Этот калькулятор стандартного отклонения использует ваш набор данных и показывает работу, необходимую для расчетов.
Введите набор данных, разделенный пробелами, запятыми или разрывами строк. Нажмите «Рассчитать», чтобы найти стандартное отклонение, дисперсию, количество точек данных. n , среднее значение и сумма квадратов. Вы также можете увидеть работу, выполненную для расчета.
n , среднее значение и сумма квадратов. Вы также можете увидеть работу, выполненную для расчета.
Вы можете копировать и вставлять строки точек данных из таких документов, как электронные таблицы Excel или текстовые документы, с запятыми или без них в форматах, показанных в таблице ниже.
Формула стандартного отклонения
Стандартное отклонение набора данных представляет собой квадратный корень из рассчитанной дисперсии набора данных.
Формула дисперсии (s 2 ) представляет собой сумму квадратов разностей между каждой точкой данных и средним значением, деленную на количество точек данных.
При работе с данными из полной совокупности сумма квадратов разностей между каждой точкой данных и средним значением делится на размер набора данных, n . При работе с выборкой делите на размер набора данных минус 1, n - 1 . 92} \)
Дополнительные сведения о стандартном отклонении и о том, как оно связано с распределением кривой нормального распределения, см. {n}x_i \] 9{2}}{n - 1} \]
{n}x_i \] 9{2}}{n - 1} \]
Допустимые форматы данных
Столбец (новые строки)
42
54
65
47
59
40
53
42, 54, 65, 47, 59, 40, 53
Разделенные запятыми (CSV)
42,
54, г.
65,
47, г.
59, г.
40, г.
53, г.
или
42, 54, 65, 47, 59, 40, 53
42, 54, 65, 47, 59, 40, 53
Пробелы
42 54
65 47
59 40
53
или
42 54 65 47 59 40 53
42, 54, 65, 47, 59, 40, 53
Смешанные разделители
42
54 65, 47,59,
40 53
42, 54, 65, 47, 59, 40, 53
Как рассчитать стандартное отклонение (Руководство)
Опубликован в 17 сентября 2020 г. к Прита Бхандари. Отредактировано 19 декабря, 2022.
к Прита Бхандари. Отредактировано 19 декабря, 2022.
Стандартное отклонение — это средняя величина изменчивости в вашем наборе данных. Он говорит вам, в среднем, насколько далеко каждое значение находится от среднего.
Высокое стандартное отклонение означает, что значения, как правило, далеки от среднего, а низкое стандартное отклонение означает, что значения сгруппированы близко к среднему.
Содержание
- О чем говорит стандартное отклонение?
- Формулы стандартного отклонения для популяций и выборок
- Этапы расчета стандартного отклонения
- Почему стандартное отклонение является полезной мерой изменчивости?
- Часто задаваемые вопросы о стандартном отклонении
Что вам говорит стандартное отклонение?
Стандартное отклонение является полезной мерой разброса для нормальных распределений .
При нормальном распределении данные распределяются симметрично без перекоса. Большинство значений группируются вокруг центральной области, при этом значения сужаются по мере удаления от центра. Стандартное отклонение показывает, насколько в среднем разбросаны ваши данные от центра распределения.
Многие научные переменные имеют нормальное распределение, включая рост, результаты стандартизированных тестов или оценки удовлетворенности работой. Когда у вас есть стандартные отклонения различных выборок, вы можете сравнить их распределения с помощью статистических тестов, чтобы сделать выводы о более крупных популяциях, из которых они взяты.
Пример: сравнение различных стандартных отклонений. Вы собираете данные об оценках удовлетворенности работой от трех групп сотрудников, используя простую случайную выборку. Среднее ( M ) оценки одинаковы для каждой группы — это значение на оси X, когда кривая находится на пике. Однако их стандартные отклонения ( SD ) отличаются друг от друга.
Стандартное отклонение отражает дисперсию распределения. Кривая с самым низким стандартным отклонением имеет высокий пик и небольшой разброс, в то время как кривая с самым высоким стандартным отклонением более плоская и широкая.
Эмпирическое правило
Стандартное отклонение и среднее вместе могут сказать вам, где находится большинство значений в вашем частотном распределении, если они подчиняются нормальному распределению.
Эмпирическое правило , или правило 68-95-99,7 говорит вам, где находятся ваши значения:
- Около 68% оценок находятся в пределах 1 стандартного отклонения от среднего,
- Около 95% баллов находятся в пределах 2 стандартных отклонений от среднего,
- Около 99,7% результатов находятся в пределах 3 стандартных отклонений от среднего значения.

Следуя эмпирическому правилу:
- Около 68% баллов находятся в диапазоне от 40 до 60.
- Около 95% баллов находятся в диапазоне от 30 до 70.
- Около 99,7% баллов находятся в диапазоне от 20 до 80.
Эмпирическое правило — это быстрый способ получить обзор ваших данных и проверить любые выбросы или экстремальные значения, которые не соответствуют этому шаблону.
Примечание. Для ненормальных распределений стандартное отклонение является менее надежной мерой изменчивости и должно использоваться в сочетании с другими показателями, такими как диапазон или межквартильный диапазон.Формулы стандартного отклонения для совокупностей и выборок
Для расчета стандартных отклонений используются разные формулы в зависимости от того, были ли вы собраны данные по всей совокупности или по выборке.
Стандартное отклонение населения
Когда вы соберете данные о каждом члене интересующей вас совокупности, вы сможете получить точное значение стандартного отклонения совокупности.
Формула стандартного отклонения населения выглядит следующим образом:
| Формула | Пояснение |
|---|---|
|
Стандартное отклонение выборки
При сборе данных из выборки стандартное отклонение выборки используется для оценок или выводов о стандартном отклонении генеральной совокупности.
Формула стандартного отклонения выборки выглядит следующим образом:
| Формула | Пояснение |
|---|---|
|
Для образцов мы используем n – 1 в формуле, потому что при использовании n дало бы нам необъективную оценку, которая последовательно занижает изменчивость. Стандартное отклонение выборки будет иметь тенденцию быть ниже, чем реальное стандартное отклонение генеральной совокупности.
Стандартное отклонение выборки будет иметь тенденцию быть ниже, чем реальное стандартное отклонение генеральной совокупности.
Уменьшение выборки n до n – 1 делает стандартное отклонение искусственно большим, что дает вам консервативную оценку изменчивости.
Хотя это и не беспристрастная оценка, это менее предвзятая оценка стандартного отклонения: лучше переоценить, чем недооценить изменчивость выборок.
Шаги для расчета стандартного отклонения
Стандартное отклонение обычно рассчитывается автоматически любым программным обеспечением, которое вы используете для статистического анализа. Но вы также можете рассчитать его вручную, чтобы лучше понять, как работает формула.
Существует шесть основных шагов для нахождения стандартного отклонения вручную. Мы будем использовать небольшой набор данных из 6 баллов, чтобы пройти по шагам.
| Набор данных | |||||
|---|---|---|---|---|---|
| 46 | 69 | 32 | 60 | 52 | 41 |
Шаг 1 : Найдите среднее
Чтобы найти среднее значение, сложите все баллы, а затем разделите их на количество баллов.
| Среднее (x̅) |
|---|
Шаг 2 : Найдите отклонение каждой оценки от среднего
Вычтите среднее из каждой оценки, чтобы получить отклонения от среднего.
Так как x̅ = 50, здесь мы отнимаем 50 от каждого результата.
| Оценка | Отклонение от среднего |
|---|---|
| 46 | 46 – 50 = -4 |
| 69 | 69 – 50 = 19 |
| 32 | 32 – 50 = -18 |
| 60 | 60 – 50 = 10 |
| 52 | 52 – 50 = 2 |
| 41 | 41 – 50 = -9 |
Шаг 3 : Возведение в квадрат каждого отклонения от среднего
Умножить каждое отклонение от среднего само на себя. Это приведет к положительным числам.
Это приведет к положительным числам.
| Квадрат отклонения от среднего |
|---|
| (-4) 2 = 4 × 4 = 16 |
| 19 2 = 19 × 19 = 361 |
| (-18) 2 = -18 × -18 = 324 |
| 10 2 = 10 × 10 = 100 |
| 2 2 = 2 × 2 = 4 |
| (-9) 2 = -9 × -9 = 81 |
Шаг 4 : Найдите сумму квадратов
Сложите все квадраты отклонений. Это называется сумма квадратов.
| Сумма квадратов |
|---|
| 16 + 361 + 324 + 100 + 4 + 81 = 886 |
Шаг 5: Найдите дисперсию
Разделите сумму квадратов на n – 1 (для выборки) или N (для совокупности) – это дисперсия.
Поскольку мы работаем с размером выборки 6, мы будем использовать n – 1, где n = 6.
| Разница |
|---|
Шаг 6 : Найдите квадратный корень из дисперсии
Чтобы найти стандартное отклонение, мы берем квадратный корень из дисперсии.
| Стандартное отклонение |
|---|
Узнав, что SD = 13,31, мы можем сказать, что каждый результат отклоняется от среднего значения в среднем на 13,31 балла.
Почему стандартное отклонение является полезной мерой изменчивости?
Хотя существуют более простые способы расчета изменчивости, формула стандартного отклонения взвешивает неравномерно распределенные выборки больше, чем равномерно распределенные выборки. Более высокое стандартное отклонение говорит вам о том, что распределение не только более разбросано, но и более неравномерно.
Это означает, что он дает вам лучшее представление о изменчивости ваших данных, чем более простые меры, такие как среднее абсолютное отклонение (MAD).
Среднеквадратичное отклонение похоже на стандартное отклонение, но его легче вычислить. Во-первых, вы выражаете каждое отклонение от среднего в абсолютных значениях, конвертируя их в положительные числа (например, -3 становится 3). Затем вы вычисляете среднее значение этих абсолютных отклонений.
В отличие от стандартного отклонения, вам не нужно вычислять квадраты или квадратные корни чисел для MAD. Однако по этой причине он дает менее точную меру изменчивости.
Возьмем две выборки с одинаковой центральной тенденцией, но разной степенью изменчивости. Образец B более изменчив, чем образец A.
| Значения | Среднее | Среднее абсолютное отклонение | Стандартное отклонение | |
|---|---|---|---|---|
| Образец А | 66, 30, 40, 64 | 50 | 15 | 17,8 |
| Образец В | 51, 21, 79, 49 | 50 | 15 | 23,7 |
Для выборок с одинаковыми средними отклонениями от среднего MAD не может различать уровни разброса. Стандартное отклонение является более точным: оно выше для выборки с большей вариабельностью отклонений от среднего значения.
Стандартное отклонение является более точным: оно выше для выборки с большей вариабельностью отклонений от среднего значения.
При возведении в квадрат различий от среднего стандартное отклонение более точно отражает неравномерную дисперсию. На этом шаге крайние отклонения взвешиваются сильнее, чем малые.
Однако это также делает стандартное отклонение чувствительным к выбросам.
Часто задаваемые вопросы о стандартном отклонении
- Что вам говорит стандартное отклонение?
-
Стандартное отклонение — это средняя величина изменчивости в вашем наборе данных. Он говорит вам, в среднем, насколько далеко каждая оценка находится от среднего значения.
В нормальном распределении высокое стандартное отклонение означает, что значения, как правило, далеки от среднего, а низкое стандартное отклонение означает, что значения сгруппированы близко к среднему.

- Что такое нормальное распределение?
-
При нормальном распределении данные распределяются симметрично без перекоса. Большинство значений группируются вокруг центральной области, при этом значения сужаются по мере удаления от центра.
Меры центральной тенденции (среднее, мода и медиана) в нормальном распределении точно такие же.
- Что такое эмпирическое правило?
-
Эмпирическое правило, или правило 68-95-99,7, говорит вам, где большинство значений находится в нормальном распределении:
- Около 68% значений находятся в пределах 1 стандартного отклонения от среднего.

- Около 95% значений находятся в пределах 2 стандартных отклонений от среднего значения.
- Около 99,7% значений находятся в пределах 3 стандартных отклонений от среднего.
Эмпирическое правило — это быстрый способ получить обзор ваших данных и проверить любые выбросы или экстремальные значения, которые не соответствуют этому шаблону.
- Около 68% значений находятся в пределах 1 стандартного отклонения от среднего.
- В чем разница между стандартным отклонением и дисперсией?
-
Дисперсия — это среднеквадратичное отклонение от среднего значения, а стандартное отклонение — это квадратный корень из этого числа. Обе меры отражают изменчивость распределения, но их единицы различаются:
- Стандартное отклонение выражается в тех же единицах, что и исходные значения (например, минуты или метры).

- Стандартное отклонение выражается в тех же единицах, что и исходные значения (например, минуты или метры).








Видео-курс
