Pdf какой формат
Обзор формата Adobe PDF
Сведения о файловом формате Adobe PDF
Формат переносимых документов (PDF) представляет собой универсальный файловый формат, который позволяет сохранить шрифты, изображения и сам макет исходного документа независимо от того, на какой из множества платформ и в каком из множества приложений такой документ создавался. Формат Adobe PDF считается признанным общемировым стандартом в области тиражирования и обмена надежно защищенными электронными документами и бланками. Файлы Adobe PDF имеют небольшой размер, и они самодостаточны; они допускают совместную работу, просмотр и печать с помощью бесплатной программы Adobe Reader®.
Отлично себя оправдывает использование формата Adobe PDF в издательском и печатном деле. Благодаря способности Adobe PDF сохранять совмещенный (композитный) макет, можно создавать компактные и надежные файлы, которые сотрудники типографии могут просматривать, редактировать, сортировать и получать с них пробные оттиски.
Также в предусмотренный техпроцессом момент в типографии могут как непосредственно отправить файл на фотонаборное устройство, так и продолжить его завершающую обработку: осуществить предпечатные проверки, провести треппинг, спустить полосы или выполнить цветоделение.
Сохраняя документ в формате PDF, можно создать файл, соответствующий стандарту PDF/X. Формат PDF/X (формат обмена переносимыми документами) является разновидностью Adobe PDF, которая не допускает использования многих вариантов и сочетаний данных о цветности, шрифтов и треппинга, которые могут вызвать осложнения при печати. Документ PDF/X следует создавать в случае, когда PDF-файлы используются как цифровые оригиналы при допечатной подготовке изданий - как на этапе создания макета, так и для целей фотовывода (если программное обеспечение и выводящие устройства способны работать с форматом PDF/X).
Формат PDF может помочь при следующих затруднениях, обычно возникающих в работе с электронными документами.
| Обычное затруднение | Чем полезен Adobe PDF |
| Присланный файл невозможно открыть, поскольку у получателя отсутствует приложение, в котором он был создан. | Где бы пользователь ни находился, он всегда сможет открыть документ PDF. Для этого достаточно иметь бесплатную программу Adobe Reader. |
| В архиве, который содержит электронные и бумажные документы, сложно найти нужный документ, а сам архив занимает немало места и требует наличия приложения, в котором документ был создан. | Документы PDF компактны и удобны для поиска; для их чтения достаточно иметь приложение Reader. Наличие ссылок облегчает навигацию внутри документа PDF. |
| Документы отображаются в карманных устройствах с искажениями. | Расстановка тегов позволяет перекомпоновать текст документа PDF специально для возможности открывать такие файлы на мобильных платформах, таких, как Palm OS®, Symbian™ или Pocket PC®. |
| Документы со сложным форматированием недоступны людям с плохим зрением. | Документы PDF с гипертекстовой разметкой содержат сведения о информационном наполнении и структуре, благодаря чему они отлично обрабатываются программами и устройствами для чтения с экрана. |


Встраивание и подстановка шрифтов
InCopy встраивает шрифт только в том случае, если он содержит заданный поставщиком параметр, разрешающий встраивание. Встраивание предотвращает подстановку шрифта при просмотре или печати файла, благодаря чему читатель видит текст, набранный исходной гарнитурой. Увеличение файла вследствие встраивания шрифтов незначительно, если в документе не используются CID-шрифты (с многобайтовыми идентификаторами символов), обычно применяемые для азиатских языков, в которых один глиф создается на основе нескольких символов.
Встраивание предотвращает подстановку шрифта при просмотре или печати файла, благодаря чему читатель видит текст, набранный исходной гарнитурой. Увеличение файла вследствие встраивания шрифтов незначительно, если в документе не используются CID-шрифты (с многобайтовыми идентификаторами символов), обычно применяемые для азиатских языков, в которых один глиф создается на основе нескольких символов.
Для каждого шрифта InCopy может встроить шрифт целиком или только его подмножество — конкретные символы, называемые глифами, которые использованы в этом файле. Сокращение знакового состава, при котором формируется уникальное имя шрифта, позволяет при печати использовать первоначальный шрифт и его метрику. Встраивание подмножества шрифта влияет на размер файла и на возможность последующего редактирования файла.
Если InCopy не может встроить шрифт, вместо него временно подставляется одна из гарнитур Multiple Master — AdobeSerMM для отсутствующего шрифта с засечками либо AdobeSanMM для шрифта без засечек.
Эти гарнитуры шрифта допускают растяжение или сжатие, что позволяет сохранить разбиение на строки и разрыв страницы исходного документа. При подстановке не всегда удается воспроизвести форму с исходными буквами, особенно если программа сталкивается с нестандартной, например рукописной, гарнитурой шрифта.
Если использована нестандартная гарнитура (слева), символы шрифта, использованного для подстановки, не всегда похожи (справа).Сведения о сжатии
При экспорте в формат Adobe PDF приложение InCopy автоматически снижает разрешение изображений, обрезает изображения по их рамке и сжимает текст и векторную графику при помощи алгоритма сжатия без потерь ZIP. Этот алгоритм хорошо подходит для изображений с большими одноцветными областями или повторяющимся узором, а также для черно-белых изображений с повторяющимся узором. Поскольку InCopy использует алгоритм сжатия без потерь ZIP, при уменьшении размера файла данные не удаляются, поэтому качество изображения не затрагивается.
Связанные материалы
- Экспорт в формат Adobe PDF
Вход в учетную запись
Войти
Управление учетной записью
чем он отличается от PDF/A, какой формат выбрать для хранения электронных документов
Ришат Мухаметшин 12 мая 2020
Делопроизводителю
Время чтения: 9 минут
Ответ для самых торопливых: PDF/A — это версия формата PDF, стандартизированная ISO и предназначенная для использования при архивировании и долгосрочном хранении электронных документов. Если вы хотите возвращаться к скан-копии печатного оригинала или электронному документу спустя много лет, то лучше использовать именно его. А теперь разберём вопрос подробнее.
Если вы хотите возвращаться к скан-копии печатного оригинала или электронному документу спустя много лет, то лучше использовать именно его. А теперь разберём вопрос подробнее.
Ответ для самых торопливых: PDF/A — это версия формата PDF, стандартизированная ISO и предназначенная для использования при архивировании и долгосрочном хранении электронных документов. Если вы хотите возвращаться к скан-копии печатного оригинала или электронному документу спустя много лет, то лучше использовать именно его. А теперь разберём вопрос подробнее.
Электронный документ PDF: особенности и история формата
PDF (Portable document format) — это универсальный формат электронных документов. Он создан по инициативе компании Adobe в 1993 году, и его исходное предназначение — электронное представление печатных материалов.
Задачи формата PDF:
- хранение данных о цветовой схеме и расположении элементов;
- обеспечение идентичного представления информации на разных мониторах и принтерах.

За время своего существования PDF значительно прибавил в возможностях. Ещё в первой редакции формата появилась возможность вставлять ссылки в текст, шифровать документ с паролем и тем самым защищать его от модификации. Функциональность дополнялась год за годом:
| Версия | Возможности |
| PDF 1-1.1 (1993-1994) | Работа с потоками данных, защита паролем и цветопередача, независимая от устройства |
| PDF 1.2 (1996) | Интерактивные элементы и возможность обрабатывать действия мыши |
| PDF 1.3 (1999) | Электронная подпись (ЭП), javaSAFEscript |
| PDF 1.4 (2001) | Прозрачность, текстовый слой поверх картинки, метаданные «ключ-значение» |
| PDF 1.5 (2003) | Мультимедиа, объектные и перекрестные потоки, слои |
| PDF 1.6 (2005) | XML-формы, AES-шифрование |
| PDF 1.7-2.0 (2005-2020) | AES-шифрование 256-битным ключом, архитектура XML-форм XFA 3. 0 0 |
Начиная с версии PDF 1.4, которая вышла в 2001 году, пользователи могут наносить текстовый слой поверх изображения. Причём он может быть невидимым. То есть пользователь, видя «картинку», тем не менее может копировать с неё текст. Кроме того, в этой же версии появилась возможность вставлять метаданные в виде пар «ключ-значение», каждая из которых может быть связана с какой-то частью документа (например, отдельным изображением) или со всем документом. Это важные нововведения, с точки зрения архивного хранения, и они поддерживаются форматом по сей день.
С 2008 года PDF — открытый стандарт ISO 32000 (последняя редакция международного стандарта качества — 32000-2 — опубликована в декабре 2020 года). Это значит, что сегодня PDF рекомендуется к использованию во всём мире.
Сохранение документа в PDF/A. Когда нужен этот формат?
Создание электронного архива документов В начале статьи мы уже дали ответ на этот вопрос: PDF/A — это версия PDF, которая рекомендована всё тем же ISO для долговременного архивирования электронных документов.
Длительный срок хранения становится возможным, потому что в содержимое электронного документа в формате PDF/A внедряется вся информация, необходимая для его отображения. В частности, к ней относятся шрифты — те из них, которые использованы в документе, включены в него. К слову, это влияет на его размер: документ в формате PDF/A часто больше по размеру, чем документ с аналогичным содержимым, сохранённый в PDF.
Считается, что документ, хранимый в формате PDF/A, из-за полного отсутствия связи с такими изменчивыми вещами как гиперссылки и мультимедийный контент можно будет открыть в любой операционной системе через какое угодно время с помощью приложения, поддерживающего соответствующий формат.
Есть ещё один аргумент в его пользу. Поскольку PDF/A обеспечен статусом международного стандарта, его поддержка разработчиками в долгосрочной перспективе оправдана, а использование целесообразно. Чего не скажешь о других доступных форматах хранения электронных документов, которые могут измениться в любой момент времени.
При этом целостность и неизменность неподписанного документа в формате PDF/A не может быть гарантирована и не заявляется как особенность формата. Другими словами, несмотря на то, что данный формат позиционируется как обеспечивающий долгосрочное хранение, изменение содержимого документа возможно и не является отклонением от нормы, если оно не зашифровано.
Однако есть ещё один нюанс: для каждого конкретного документа, формат которого заявлен как PDF/A, невозможно заведомо утверждать, что это действительно так. В каждом случае необходима верификация на соответствие требованиям формата. И если на этапе размещения в архиве или после очередного изменения она не будет проведена, можно считать миссию обеспечения долгосрочного хранения потенциально проваленной (с некоторыми оговорками, но всё же).
Как проверить PDF/A
Действительно ли документ сохранён в нужном формате — очевидные сомнения. Внешне определить, PDF это или PDF/A, очень сложно.
Если файл соответствует формату PDF/A, то информацию об этом можно увидеть в приложении Acrobat Distiller на панели «Навигация» (Просмотр — Показать/Скрыть — Панели навигации — Стандарты).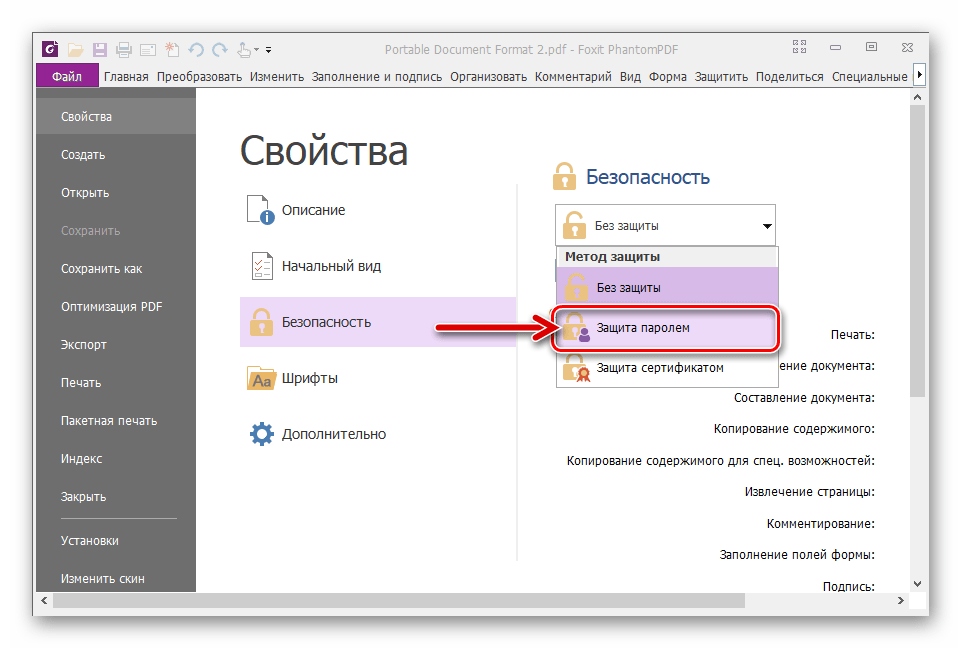 Подробнее — в справке Adobe.com.
Подробнее — в справке Adobe.com.
Также в этих случаях используются программы-валидаторы. Пример — veraPDF (можно скачать здесь). Программу создавал союз нескольких профессиональных сообществ, в том числе Ассоциация PDF (PDF Association).
Также есть сервисы, которые могут определить формат в режиме онлайн. В их числе avePDF, pdf-online и другие. Во многих таких сервисах можно не только проверить, но и изменить формат — перевести файл из PDF в PDF/A. Доверять онлайн-решениям или нет — вопрос, который остаётся на стороне пользователя. Во всяком случае к официально признанным программам-валидаторам PDF они не относятся.
Чтобы обеспечить целостность и юридическую значимость электронных документов, недостаточно использовать нужный формат. Также необходимо использовать специализированную систему долговременного хранения.
Как хранить отсканированный документ в PDF/A
Исходя из описанных выше различий между форматами PDF и его потомком PDF/A, вполне можно предположить, что первый больше пригоден для оперативного обмена и краткосрочного хранения электронных документов. При этом PDF/A, несмотря на потенциально большой размер единичного документа (в него внедрены все использованные шрифты, а это для краткосрочного использования избыточный и ощутимый балласт), имея статус международного стандарта, гарантирует, что даже через продолжительное время, вне зависимости от окружения и операционной системы, любой пользователь сможет открыть документ в данном формате, располагая приложением-просмотрщиком. Этот факт укладывается в концепцию архива электронных документов и должен учитываться при сохранении каждого документа в нём.
При этом PDF/A, несмотря на потенциально большой размер единичного документа (в него внедрены все использованные шрифты, а это для краткосрочного использования избыточный и ощутимый балласт), имея статус международного стандарта, гарантирует, что даже через продолжительное время, вне зависимости от окружения и операционной системы, любой пользователь сможет открыть документ в данном формате, располагая приложением-просмотрщиком. Этот факт укладывается в концепцию архива электронных документов и должен учитываться при сохранении каждого документа в нём.
Теперь необходимо определиться с тем, что такое отсканированный образ документов. Чаще всего это растровое изображение. Предполагается, что текста поверх него нет, то есть в документе хранится исключительно отсканированный растр — изображение, текст на котором непонятен компьютеру, а понятен только человеку.
В исключительных случаях поверх растрового изображения может быть расположен текстовый слой, частично или целиком наполненный. Причём делается это либо вручную человеком, либо с помощью системы распознавания текста. Можно предположить, что документ содержит метаданные, так или иначе связанные с видом документа и его содержимым (например, если это счёт-фактура, метаданные могут содержать информацию о поставщике, дате выставления, сумме и т. д.).
Причём делается это либо вручную человеком, либо с помощью системы распознавания текста. Можно предположить, что документ содержит метаданные, так или иначе связанные с видом документа и его содержимым (например, если это счёт-фактура, метаданные могут содержать информацию о поставщике, дате выставления, сумме и т. д.).
Очевидно, что отсканированный образ документа допускает, но не подразумевает долгосрочного хранения. Но всё-таки в большинстве случаев образ должен храниться не меньше бумажного оригинала, а зачастую значительно дольше, поскольку значимость и важность его в контексте организации-владельца всегда есть. Кроме того, образ снят с бумажного документа, а это значит, что его изменение не подразумевается, хотя и возможно.
На основании перечисленных особенностей, которыми обладает отсканированный образ документа, можно смело заявлять, что для хранения одинаково пригодны оба формата. Хотя PDF/A допускает и метаданные, и текстовый слой поверх изображения, и даже подписание документа с целью защитить его от модификации.
Чтобы прочитать эту статью до конца,
авторизуйтесь
или зарегистрируйтесь
pdf электронный документ сканирование форматы документов
Формат файла PDF - Что такое файл PDF?
Portable Document Format (PDF) — это тип документа, созданный Adobe еще в 1990-х годах. Цель этого формата файла состояла в том, чтобы ввести стандарт для представления документов и других справочных материалов в формате, который не зависит от прикладного программного обеспечения, аппаратного обеспечения, а также операционной системы. Формат файла PDF имеет полную возможность содержать такую информацию, как текст, изображения, гиперссылки, поля форм, мультимедийные материалы, цифровые подписи, вложения, метаданные, геопространственные функции и 3D-объекты, которые могут стать частью исходного документа.
В большинстве случаев существующие документы преобразуются в PDF, а не создаются новые PDF с нуля. Но это не означает, что нет программного обеспечения для создания или обработки PDF-файлов.
(Хотите поделиться чем-то о формате PDF-файла? Вы можете опубликовать свои выводы в разделе новостей о формате PDF-файла.)
Формат PDF-файла — краткая история Сроки следующие:
1993 — Adobe Systems предоставила спецификации PDF бесплатно
2008 — PDF был выпущен в качестве открытого стандарта 1 июля 2008 г. и опубликован Международной организацией по стандартизации как ISO 32000-1:2008 .
2008 — Adobe опубликовала Публичную патентную лицензию в формате ISO 32000-1, не требующую лицензионных отчислений для всех принадлежащих Adobe патентов, которые необходимы для создания, использования, продажи и распространения реализаций, совместимых с PDF.
Первая версия PDF, обозначенная как PDF 1. 0, которая позже претерпела изменения до PDF 1.7. PDF 1.7, который стал ISO 32000-1, включает некоторые нестандартизированные проприетарные технологии, а также архитектуру Adobe XML Forms (XFA) и расширение JavaScript для Acrobat. 28 июля 2017 года был опубликован PDF 2.0, известный как ISO 32000-2:2017, который не включает никаких нестандартизированных технологий.
0, которая позже претерпела изменения до PDF 1.7. PDF 1.7, который стал ISO 32000-1, включает некоторые нестандартизированные проприетарные технологии, а также архитектуру Adobe XML Forms (XFA) и расширение JavaScript для Acrobat. 28 июля 2017 года был опубликован PDF 2.0, известный как ISO 32000-2:2017, который не включает никаких нестандартизированных технологий.
Спецификации формата файла PDF
Файл PDF представляет собой набор байтов, которые можно сгруппировать в токены в соответствии с правилами синтаксиса, определенными спецификациями PDF. Один или несколько токенов объединяются для формирования синтаксических объектов более высокого уровня, в основном объектов, которые являются базовыми значениями данных, из которых строится документ PDF.
Файловая структура PDF-файлов
Содержимое PDF-файла внутри файла расположено в следующей последовательности.
|Заголовок |Тело |Таблица перекрестных ссылок |Trailer
Независимо от версии PDF файл PDF начинается с заголовка, содержащего уникальный идентификатор PDF и версию формата, например %PDF-1.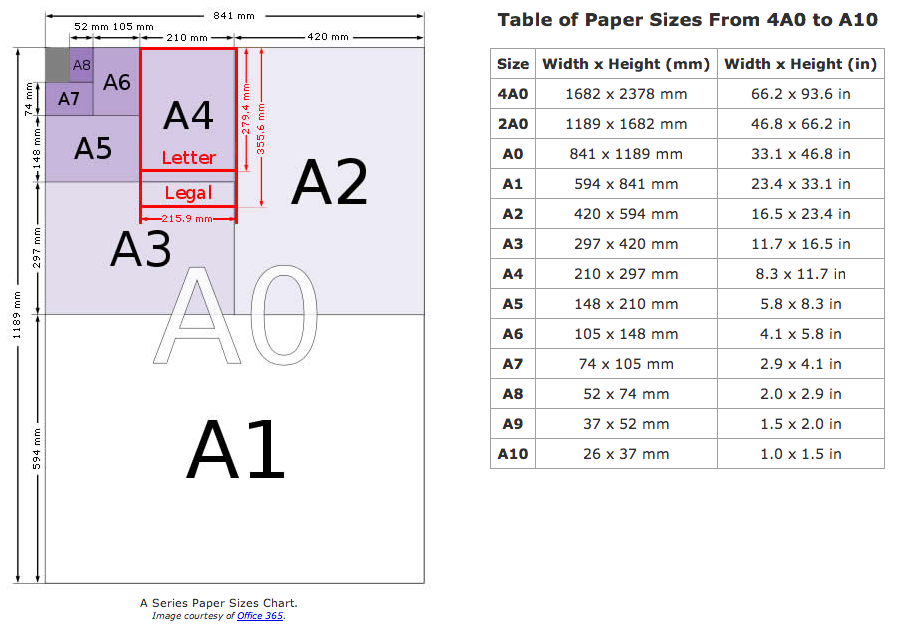 x, где x находится в диапазоне от 1 до 7.
x, где x находится в диапазоне от 1 до 7.
Тело файла
Тело файла PDF состоит из последовательности косвенных объектов, представляющих содержимое документа. Объекты, как описано выше, представляют компоненты документа, такие как шрифты, страницы и образцы изображений. Начиная с PDF 1.5, тело также может содержать потоки объектов, каждый из которых содержит последовательность косвенных объектов.
Таблица перекрестных ссылок
Таблица перекрестных ссылок содержит информацию, которая разрешает произвольный доступ к косвенным объектам в файле, поэтому нет необходимости читать весь файл, чтобы найти какой-либо конкретный объект. Таблица должна содержать однострочную запись для каждого косвенного объекта, указывающую смещение в байтах этого объекта в теле файла. (Начиная с PDF 1.5, часть или вся информация о перекрестных ссылках может альтернативно содержаться в потоках перекрестных ссылок.
Завершающий файл
Завершающий файл файла PDF позволяет соответствующему читателю быстро найти таблицу перекрестных ссылок и некоторые специальные объекты. Соответствующие читатели должны читать файл PDF с конца. Последняя строка файла должна содержать только маркер конца файла %%EOF. Две предшествующие строки должны содержать, по одной на строку и по порядку, ключевое слово startxref и смещение в байтах в декодированном потоке от начала файла до начала ключевого слова xref в последнем разделе перекрестных ссылок.
Соответствующие читатели должны читать файл PDF с конца. Последняя строка файла должна содержать только маркер конца файла %%EOF. Две предшествующие строки должны содержать, по одной на строку и по порядку, ключевое слово startxref и смещение в байтах в декодированном потоке от начала файла до начала ключевого слова xref в последнем разделе перекрестных ссылок.
Объекты PDF
Файл PDF включает в себя несколько различных типов объектов следующих типов:
- Логические значения — представляют условное значение true или false
- Числа — целые и вещественные значения
- Строки — содержат символы в скобках
- Имена - начните с символа вперед/напр. /ASomewhatLongerName приводит к AsomewhatLongerName
- Массивы — PDF поддерживает одномерные массивы. Массивы больших размерностей можно создавать, используя массивы как вложенные элементы
- Словари - коллекция объектов в виде пар ключ-значение. Он может иметь нулевые записи.
- Потоки — представляет собой последовательность байтов, которая также может иметь неограниченную длину.

- Пустой объект — представляет нулевое значение. .
Косвенные объекты
Любой объект в файле PDF может быть помечен как косвенный объект. Косвенным объектам присваивается уникальный идентификатор объекта, по которому другие объекты могут ссылаться на него. Перекрестные ссылки на них сохраняются в индексной таблице и помечаются ключевым словом xref, которое следует за основным телом и дает смещение в байтах каждого косвенного объекта от начала файла.
Линейные и нелинейные макеты PDF
Макеты PDF делятся на близкие и нелинейные в зависимости от целевых приложений и других факторов.
Нелинейный — нелинейные PDF-файлы занимают меньше места на диске по сравнению с линейными PDF-файлами. PDF-страницы документа находятся в разбросанном виде по всему PDF-файлу, поэтому нелинейные файлы медленнее по сравнению с линейными файлами.
Linear PDF — предназначенные для онлайн-просмотрщиков PDF, файлы Linear PDF сконструированы таким образом, что они записываются на диск линейным образом.
 Это не требует плагинов браузера для загрузки всего документа перед отображением.
Это не требует плагинов браузера для загрузки всего документа перед отображением. Обзор объектов
Как уже упоминалось, тело PDF представляет собой набор объектов, упомянутых выше. PDF в значительной степени основан на PostScript без управляющих функций языков программирования, таких как команды if и loop. Команды, выдаваемые кодом Postscript для создания графического содержимого, собираются и размечаются в дополнение к любым файлам, графике или шрифтам, на которые ссылается документ. Все это содержимое аккумулируется в один файл, в результате чего получается составной вывод PostScript.
Текст
Текст в PDF представлен текстовыми элементами, которые на самом деле отображаются глифами из шрифтов. Глиф — это графическая фигура, с которой можно выполнять все графические операции, такие как преобразование координат. Из-за важности текста в большинстве описаний страниц PDF предоставляет средства более высокого уровня для удобного и эффективного описания, выбора и отображения глифов.

Графика
Графические операторы, используемые в потоках содержимого PDF, описывают внешний вид страниц, которые должны быть воспроизведены на растровом устройстве вывода. Оборудование предназначено как для принтеров, так и для дисплеев. Графические операторы образуют шесть основных групп:
- Операторы состояния графики манипулируют структурой данных, называемой состоянием графики, глобальной структурой, в которой выполняются другие графические операторы. Состояние графики включает в себя текущую матрицу преобразования (CTM), которая сопоставляет координаты пространства пользователя, используемые в потоке содержимого PDF, с координатами устройства вывода. Он также включает текущий цвет, текущий путь отсечения и многие другие параметры, которые являются неявными операндами операторов рисования.
- Операторы построения пути задают пути, которые определяют формы, траектории линий и области различных типов. Они включают в себя операторы для начала нового пути, добавления к нему сегментов линий и кривых и его закрытия.

- Операторы рисования контура заполняют контур цветом, рисуют вдоль него обводку или используют ее в качестве границы отсечения.
- Другие операторы рисования рисуют определенные графические объекты с самоописанием. К ним относятся сэмплированные изображения, геометрически заданные затенения и целые потоки контента, которые, в свою очередь, содержат последовательности графических операторов.
- Текстовые операторы выбирают и отображают глифы символов из шрифтов (описания гарнитур для представления текстовых символов). Поскольку PDF обрабатывает глифы как обычные графические формы, многие текстовые операторы можно сгруппировать с операторами состояния графики или операторами рисования. Однако структуры данных и механизмы для работы с описаниями глифов и шрифтов достаточно специализированы.
- Операторы маркированного содержимого связывают логическую информацию более высокого уровня с объектами в потоке содержимого. Эта информация не влияет на отображаемый вид контента; это полезно для приложений, которые используют PDF для обмена документами.
Ссылки
- Формат PDF-файла: основная структура
- PDF — Википедия
- Справочник по PDF — Adobe
Формат PDF-файла: базовая структура [обновлено в 2020 г.]
Мы все знаем, что существуют атаки злоумышленник включает шелл-код в PDF-документ. Этот шеллкод использует некоторую уязвимость в том, как документ PDF анализируется и представляется пользователю для выполнения вредоносного кода в целевой системе.
На следующем изображении представлено количество уязвимостей, обнаруженных в популярной программе чтения PDF-файлов Adobe Acrobat Reader DC, которая была выпущена в 2015 году и стала единственной поддерживаемой версией Acrobat Reader после прекращения поддержки Acrobat XI в октябре 2017 года. Количество уязвимостей составляет увеличивается с годами. Наиболее важными уязвимостями являются уязвимости выполнения кода, которые злоумышленник может использовать для выполнения произвольного кода на целевой системе (если Acrobat Reader еще не пропатчен).
Рисунок 1: Уязвимости DC для Adobe Acrobat Reader
Это важный показатель того, что мы должны регулярно обновлять нашу программу для чтения PDF-файлов, потому что количество уязвимостей, обнаруженных в последнее время, весьма устрашающе.
Структура файла PDF
Всякий раз, когда мы хотим обнаружить новые уязвимости в программном обеспечении, мы должны сначала понять протокол или формат файла, в котором мы пытаемся обнаружить новые уязвимости. В нашем случае мы должны сначала подробно разобраться в формате файла PDF. В этой статье мы рассмотрим формат файла PDF и его внутренности.
PDF — это портативный формат документов, который можно использовать для представления документов, содержащих текст, изображения, мультимедийные элементы, ссылки на веб-страницы и многое другое. Он имеет широкий спектр функций. Спецификация формата PDF-файла общедоступна здесь и может использоваться всеми, кто интересуется форматом PDF-файла. Только для формата файла PDF имеется почти 800 страниц документации, так что читать ее — это не то, что нужно делать по прихоти.

PDF имеет больше функций, чем просто текст: он может включать изображения и другие мультимедийные элементы, быть защищенным паролем, выполнять JavaScript и т.д. Базовая структура файла PDF представлена на рисунке ниже:
Рисунок 2: Структура PDF
Каждый документ PDF состоит из следующих элементов:
Заголовок
Это первая строка файла PDF, в которой указывается номер версии используемой спецификации PDF, используемой в документе. Если мы хотим узнать это, мы можем использовать шестнадцатеричный редактор или просто использовать команду xxd , как показано ниже:
[plain]
# xxd temp.pdf | голова -n 1
0000000: 2550 4446 2d31 2e33 0a25 c4e5 f2e5 eba7 %PDF-1.3.%……
[/plain]PDF-документ temp.pdf использует спецификацию PDF 1.3. Символ «%» является комментарием в PDF, поэтому в приведенном выше примере первая и вторая строки фактически представляют собой комментарии, что верно для всех документов PDF.
 Следующие байты взяты из вывода ниже: 2550 4446 2d31 2e33 0a25 c4e5 и соответствуют ASCII-тексту «%PDF-1.3.%». Ниже приведены некоторые символы ASCII, которые используют непечатаемые символы (обратите внимание на точки «.»), которые обычно указывают некоторым программным продуктам, что файл содержит двоичные данные и не должен рассматриваться как 7-битный ASCII. текст. В настоящее время номера версий имеют форму 1.N, где N находится в диапазоне от 0 до 7.
Следующие байты взяты из вывода ниже: 2550 4446 2d31 2e33 0a25 c4e5 и соответствуют ASCII-тексту «%PDF-1.3.%». Ниже приведены некоторые символы ASCII, которые используют непечатаемые символы (обратите внимание на точки «.»), которые обычно указывают некоторым программным продуктам, что файл содержит двоичные данные и не должен рассматриваться как 7-битный ASCII. текст. В настоящее время номера версий имеют форму 1.N, где N находится в диапазоне от 0 до 7. Тело
В теле документа PDF есть объекты, которые обычно включают текстовые потоки, изображения, другие мультимедийные элементы и т. д. Раздел «Тело» используется для хранения всех данных документа, отображаемых пользователю.
Таблица внешних ссылок
Это таблица перекрестных ссылок, которая содержит ссылки на все объекты в документе. Назначение таблицы перекрестных ссылок заключается в том, что она обеспечивает произвольный доступ к объектам в файле, поэтому нам не нужно читать весь PDF-документ, чтобы найти конкретный объект.
 Каждый объект представлен одной записью в таблице перекрестных ссылок, длина которой всегда составляет 20 байт. Покажем пример:
Каждый объект представлен одной записью в таблице перекрестных ссылок, длина которой всегда составляет 20 байт. Покажем пример: [plain]
xref
0 1
0000000023 65535 f
3 1
0000025324 00000 n
21 4
0000025518 00002 n
0000025632 00000 n
0000000024 00001 f
0000000000 00001 f
36 1
0000026900 00000 n
[/ plain]Мы можем отобразить таблицу перекрестных ссылок PDF-документа, просто открыв PDF-файл в текстовом редакторе и прокрутив до конца документа. В приведенном выше примере мы видим, что у нас есть четыре подраздела (обратите внимание на четыре строки, которые содержат только два числа). Первое число в этих строках соответствует номеру объекта, а вторая строка указывает количество объектов в текущем подразделе. Каждый объект представлен одной записью длиной 20 байт (включая CRLF).
Первые 10 байтов — это смещение объекта от начала документа PDF до начала этого объекта. Далее следует пробел с другим числом, указывающим номер поколения объекта.
 После этого следует еще один разделитель пробела, за которым следует буква «f» или «n», чтобы указать, свободен ли объект или используется.
После этого следует еще один разделитель пробела, за которым следует буква «f» или «n», чтобы указать, свободен ли объект или используется. Первый объект имеет идентификатор 0 и всегда содержит одну запись с номером поколения 65535, которая находится во главе списка свободных объектов (обратите внимание на букву «f», которая означает «свободный»). Последний объект в таблице перекрестных ссылок использует номер поколения 0.
Второй подраздел имеет идентификатор объекта 3 и содержит один элемент, объект 3, который начинается со смещения 25324 байта от начала документа. Третий подраздел содержит четыре объекта, первый из которых имеет идентификатор 21 и начинается со смещения 25518 от начала файла. Другие объекты имеют последующие номера 22, 23 и 24.
Все объекты отмечены флажком «f» или «n». Флаг «f» означает, что объект все еще может присутствовать в файле, но помечен как свободный, поэтому его нельзя использовать. Эти объекты содержат ссылку на следующий свободный объект и номер поколения, который будет использоваться, если объект снова станет действительным.
 Флаг «n» используется для представления действительных и используемых объектов, которые содержат смещение от начала файла и номер поколения объекта.
Флаг «n» используется для представления действительных и используемых объектов, которые содержат смещение от начала файла и номер поколения объекта. Обратите внимание, что нулевой объект указывает на следующий свободный объект в таблице, объект 23. Поскольку объект 23 также свободен, он сам указывает на следующий свободный объект в таблице, объект 24. Но объект 24 является последним свободным объектом в файле, поэтому он указывает на нулевой объект. If we represent the above cross-reference table with every object number, it would look as follows:
[plain]
.
xref
0 1
0000000023 65535 f
3 1
0000025324 00000 n
21 1
0000025518 00002 n
22 1
0000025632 00000 N
23 1
0000000024 00001 F
24 1
0000000000 00001 F
36 1
0000026900 00000 n
[//clain] если объект снова становится действительным (меняет флаг с «f» на «n»), номер поколения остается действительным без необходимости его увеличения. Номер поколения объекта 23 равен 1, поэтому, если он снова станет действительным, номер поколения по-прежнему будет 1, но если его снова удалить, номер поколения увеличится до 2.
если объект снова становится действительным (меняет флаг с «f» на «n»), номер поколения остается действительным без необходимости его увеличения. Номер поколения объекта 23 равен 1, поэтому, если он снова станет действительным, номер поколения по-прежнему будет 1, но если его снова удалить, номер поколения увеличится до 2.
В документах PDF, которые постепенно обновляются, обычно присутствует несколько подразделов, в противном случае должен присутствовать только один подраздел, начинающийся с нуля.
Трейлер
Трейлер PDF указывает, как приложение, читающее PDF-документ, должно находить таблицу перекрестных ссылок и другие специальные объекты. Все программы чтения PDF должны начинать чтение PDF с конца файла. Пример трейлера представлен ниже:
прицеп
<<
/Размер 22
/Корень 2 0 R
/Информация 1 0 R
&gt;&gt;
startxref
24212
%%EOF
Последняя строка документа PDF содержит конец строки файла «%%EOF». Перед концом тега файла находится строка со строкой startxref , указывающая смещение от начала файла до таблицы перекрестных ссылок. В нашем случае таблица перекрестных ссылок начинается со смещения 24212 байт. До этого trailer строка, указывающая начало раздела трейлера. Содержимое концевых разделов заключено в символы << и >> (это словарь, который принимает пары ключ-значение).
Перед концом тега файла находится строка со строкой startxref , указывающая смещение от начала файла до таблицы перекрестных ссылок. В нашем случае таблица перекрестных ссылок начинается со смещения 24212 байт. До этого trailer строка, указывающая начало раздела трейлера. Содержимое концевых разделов заключено в символы << и >> (это словарь, который принимает пары ключ-значение). Мы видим, что раздел трейлера определяет несколько клавиш, каждая из которых предназначена для определенного действия. Раздел трейлера может указывать следующие ключи:
- /Size [целое число]: указывает количество записей в таблице перекрестных ссылок (включая объекты в обновленных разделах). Используемый номер не должен быть косвенной ссылкой.
- /Prev [целое число]: указывает смещение от начала файла до предыдущего раздела перекрестных ссылок, которое используется при наличии нескольких разделов перекрестных ссылок. Номер должен быть перекрестной ссылкой.
- /Root [словарь]: указывает объект ссылки для объекта каталога документов, который является специальным объектом, содержащим различные указатели на различные виды других специальных объектов (подробнее об этом позже).
- /Encrypt [словарь]: указывает словарь шифрования документа.
- /Info [словарь]: указывает ссылочный объект для информационного словаря документа.
- /ID [массив]: указывает массив двухбайтовых незашифрованных строк, формирующих идентификатор файла.
- /XrefStm [целое число]: указывает смещение от начала файла до потока перекрестных ссылок в декодированном потоке. Это присутствует только в файлах гибридных ссылок, что указано, если мы также хотим открывать документы, даже если приложения не поддерживают потоки сжатых ссылок.
Мы должны помнить, что исходная структура может быть изменена, если мы обновим документ PDF позже. Обновление обычно добавляет дополнительные элементы в конец файла.
Добавочные обновления
PDF был разработан с учетом добавочных обновлений, поскольку мы можем добавлять некоторые объекты в конец файла PDF без перезаписи всего файла. Благодаря этому изменения в документе PDF можно быстро сохранить.
 Новую структуру PDF-документа можно увидеть на картинке ниже:
Новую структуру PDF-документа можно увидеть на картинке ниже:
Рисунок 3: Структура PDF
Мы видим, что документ PDF по-прежнему содержит исходный заголовок, основную часть, таблицу перекрестных ссылок и трейлер. Кроме того, в документ PDF были добавлены другие разделы основной части, перекрестных ссылок и трейлеров. Дополнительные разделы перекрестных ссылок будут содержать только записи для объектов, которые были изменены, заменены или удалены. Удаленные объекты останутся в файле, но будут помечены флагом «f». Каждый трейлер должен заканчиваться тегом «%%EOF» и должен содержать запись /Prev, которая указывает на предыдущий раздел перекрестных ссылок.
В версиях PDF 1.4 и выше мы можем указать запись версии в словаре каталога документа, чтобы переопределить версию по умолчанию из заголовка PDF.
Пример
Давайте представим простой пример PDF и проанализируем его. Давайте загрузим образец PDF-документа отсюда и проанализируем его.
 При открытии этого PDF-документа он выглядит следующим образом:
При открытии этого PDF-документа он выглядит следующим образом: Рисунок 4: Образец PDF-документа
Разделы перекрестных ссылок и трейлера представлены на рисунке ниже:
Рисунок 5: Разделы перекрестных ссылок и концевые разделы
Раздел перекрестных ссылок был сокращен для ясности. Раздел перекрестных ссылок содержит один подраздел, содержащий 223 объекта. Раздел трейлера начинается со смещения байта 50291 и включает 223 объекта, где корневой элемент указывает на объект 221, а информационный элемент указывает на объект 222.
В следующем разделе мы рассмотрим основные типы данных структуры PDF.
Типы данных PDF
Документ PDF содержит восемь основных типов объектов, описанных ниже. Это следующие типы: логические значения, числа, строки, имена, массивы, словари, потоки и нулевой объект. Объекты могут быть помечены, чтобы на них могли ссылаться другие объекты. Помеченный объект также называется косвенным объектом.

Логические значения
Есть два ключевых слова: true и false , которые представляют логические значения.
Числа
В PDF-документе есть два типа чисел: целые и действительные. Целое число состоит из одной или нескольких цифр, которым может предшествовать знак плюс или минус. Пример целочисленных объектов можно увидеть ниже:
- 123 +123 -123
Действительное значение может быть представлено одной или несколькими цифрами, с необязательным знаком и начальным, конечным или встроенным десятичным запятым (точкой). Пример действительных чисел можно увидеть ниже:
- 123,0 -123,0 +123,0 123. -0,123
Имена
Имена в документах PDF представлены последовательностью символов ASCII в диапазоне от 0x21 до 0x7E. Исключением являются символы: %, (, ), <, >, [ ], {, }, / и #, перед которыми должна стоять косая черта. Альтернативным представлением символов является их шестнадцатеричный эквивалент, которому предшествует символ «#».
 Существует ограничение длины элемента имени, которое может составлять всего 127 байт.
Существует ограничение длины элемента имени, которое может составлять всего 127 байт. При написании имени необходимо использовать косую черту; косая черта не является частью имени, а является префиксом, указывающим, что далее следует последовательность символов, представляющая имя. Если мы хотим использовать пробел или любой другой специальный символ как часть имени, он должен быть закодирован двузначным шестнадцатеричным представлением.
Примеры имен можно увидеть в таблице ниже:
Рисунок 6: Имена PDF (источник)
Строки
Строки в документе PDF представлены в виде последовательности байтов, заключенных в скобки или угловые скобки, но могут иметь максимальную длину 65535 байт. Любой символ может быть представлен в виде ASCII, а также в восьмеричном или шестнадцатеричном представлении. Восьмеричное представление требует, чтобы символ был записан в форме ддд, где ддд — восьмеричное число. Шестнадцатеричное представление требовало, чтобы символ был записан в форме
- , где dd — шестнадцатеричное число.

Ниже приведен пример представления строки, заключенной в круглые скобки:
- (mystring)
Пример представления строки, заключенной в угловые скобки, можно увидеть ниже (шестнадцатеричное представление ниже такое же, как и выше, и оно читается как «mystring»):
- <6d79737472696e67>
Мы также можем использовать специальные известные символы при представлении строки. Это: n для новой строки, r для возврата каретки, t для горизонтального табулятора, b для возврата, f для перевода страницы, ( для левой скобки, ) для правой скобки и для обратной косой черты.
Массивы
Массивы в документах PDF представлены в виде последовательности объектов PDF, которые могут быть разных типов и заключены в квадратные скобки. Вот почему массив в документе PDF может содержать любые типы объектов, такие как числа, строки, словари и даже другие массивы. Массив также может иметь нулевые элементы. Массив представлен квадратной скобкой.
 Пример массива представлен ниже:
Пример массива представлен ниже: - 123 123.0 true (mystring) /myname]
Словари
Словари в документе PDF представлены в виде таблицы пар ключ/значение. Ключ должен быть объектом имени, тогда как значением может быть любой объект, включая другой словарь. Максимальное количество статей в словаре — 4096 статей. Словарь может быть представлен статьями, заключенными в двойные угловые скобки << и >>. Пример словаря представлен ниже:
<< /mykey1 123/mykey2 0,123
/mykey3 << /mykey4 правда
/mykey5 (mystring)
>>
>>
Потоки
Потоковый объект представлен последовательностью байтов и может быть неограниченной длины, поэтому изображения и другие блоки больших данных обычно представляются в виде потоков. Объект потока представлен объектом словаря, за которым следует поток ключевых слов, за которым следуют новая строка и конец потока.

Пример объекта потока можно увидеть ниже:
<</Тип /Страница
/Длина 23 0 R
/Фильтр /LZWDecode
>>
поток
…
конечный поток
Все объекты потока должны быть косвенными объектами, а словарь потока должен быть прямым объектом. Словарь потока указывает точное количество байтов потока. После данных должен быть символ новой строки и ключевое слово endstream.Общие ключевые слова, используемые во всех потоковых словарях, следующие (обратите внимание, что запись длины обязательна):
- Длина: сколько байт файла PDF используется для данных потока. Если поток содержит запись фильтра, длина должна указывать количество байтов закодированных данных.
- Тип: тип объекта PDF, который описывает словарь.
- Фильтр: имя фильтра, который будет применяться при обработке данных потока. Можно указать несколько фильтров в том порядке, в котором они должны применяться.
- DecodeParms: словарь или массив словарей, используемых фильтрами, заданными параметром Filter.
 Это значение указывает параметры, которые необходимо передать фильтрам при их применении. В этом нет необходимости, если фильтры используют значения по умолчанию.
Это значение указывает параметры, которые необходимо передать фильтрам при их применении. В этом нет необходимости, если фильтры используют значения по умолчанию. - F: Указывает файл, содержащий данные потока.
- FFilter: имя фильтра, который будет применяться при обработке данных, найденных во внешнем файле потока.
- FDecodeParms: словарь или массив словарей, используемых фильтрами, указанными в FFilter.
- DL: указывает количество байтов в декодированном потоке. Это можно использовать, если на диске достаточно места для записи потока в файл.
- N: количество косвенных объектов, хранящихся в потоке.
- Первый: смещение в декодированном потоке первого сжатого объекта.
- Расширяет: указывает ссылку на другие потоки объектов, формирующие дерево наследования.
Данные потока в потоке объектов будут содержать N пар целых чисел, где первое целое число представляет номер объекта, а второе целое число представляет смещение в декодированном потоке этого объекта.
 Объекты в потоках объектов являются последовательными, и их не нужно хранить в порядке возрастания относительно номера объекта. Первая запись в словаре идентифицирует первый объект в потоке объектов.
Объекты в потоках объектов являются последовательными, и их не нужно хранить в порядке возрастания относительно номера объекта. Первая запись в словаре идентифицирует первый объект в потоке объектов. Мы не должны хранить следующую информацию в потоке объектов:
- Объекты потока
- Объекты с номером поколения, отличным от нуля
- Словарь шифрования документа
- Косвенный объект записи длины в словаре потока объектов
- Каталог документов, словарь линеаризации, страничные объекты
В PDF 1.5 информация о перекрестных ссылках может храниться в потоке перекрестных ссылок, а не в таблице перекрестных ссылок. Каждый поток перекрестных ссылок содержит информацию, эквивалентную таблице перекрестных ссылок и трейлеру.
Пустой объект
Пустой объект представлен ключевым словом «null».
Косвенные объекты
Прежде всего, мы должны знать, что любой объект в документе PDF может быть помечен как косвенный объект.
 Это дает объекту уникальный идентификатор объекта, который другие объекты могут использовать для ссылки на косвенный объект. Косвенный объект — это пронумерованный объект, представленный ключевыми словами «obj» и «endobj». Endobj должен присутствовать в отдельной строке, но obj должен располагаться в конце строки идентификатора объекта, которая является первой строкой косвенного объекта. Строка идентификатора объекта состоит из номера объекта, номера поколения и ключевого слова «obj». Пример косвенного объекта выглядит следующим образом:
Это дает объекту уникальный идентификатор объекта, который другие объекты могут использовать для ссылки на косвенный объект. Косвенный объект — это пронумерованный объект, представленный ключевыми словами «obj» и «endobj». Endobj должен присутствовать в отдельной строке, но obj должен располагаться в конце строки идентификатора объекта, которая является первой строкой косвенного объекта. Строка идентификатора объекта состоит из номера объекта, номера поколения и ключевого слова «obj». Пример косвенного объекта выглядит следующим образом:
2 1 obj12345
endobj
В приведенном выше примере мы создаем новый косвенный объект, который содержит объект номер 12345. Объявив объект косвенным объектом, мы можем использовать его в таблице перекрестных ссылок PDF-документа и повторно использовать его на любой странице, словаре и т. д. в документе. Поскольку каждый косвенный объект имеет свою собственную запись в таблице перекрестных ссылок, доступ к косвенным объектам можно получить очень быстро.
Идентификатор объекта косвенного объекта состоит из двух частей; первая часть - это номер текущего косвенного объекта. Непрямые объекты не обязательно должны быть последовательно пронумерованы в документе PDF. Вторая часть — это номер поколения, который устанавливается равным нулю для всех объектов во вновь созданном файле. Позже это число увеличивается при обновлении объектов.
Мы можем обращаться к косвенным объектам с косвенной ссылкой, которая состоит из номера объекта, номера поколения и ключевого слова R. Чтобы сослаться на указанный выше косвенный объект, мы должны написать что-то вроде следующего:
- 2 1 R
Если мы пытаемся сослаться на неопределенный объект, мы на самом деле ссылаемся на нулевой объект.
Структура документа
Документ PDF состоит из объектов, содержащихся в разделе body файла PDF. Большинство объектов в документе PDF являются словарями. Каждая страница документа представлена объектом страницы, который представляет собой словарь, включающий ссылки на содержимое страницы.
 Объекты страницы связаны между собой и образуют дерево страниц, которое объявляется косвенной ссылкой в каталоге документов.
Объекты страницы связаны между собой и образуют дерево страниц, которое объявляется косвенной ссылкой в каталоге документов. Всю структуру документа PDF можно представить на рисунке ниже [1]:
Рисунок 7: Структура документа PDF (исходник)
На рисунке выше мы видим, что документ каталог содержит ссылки на дерево страниц, структуру иерархии, цепочки статей, именованные адресаты и интерактивную форму. Мы не будем вдаваться в подробности того, что делает каждый из этих разделов, а представим только самый важный раздел — Дерево страниц.
Каталог документов
Из рисунка выше видно, что каталог документов является корнем объектов в документе PDF. Мы уже говорили, что именно элемент /Root в разделе Trailer PDF указывает каталог документов. Каталог документов содержит ссылки на другие объекты, определяющие содержание документа. Он также содержит информацию, определяющую, как документ будет отображаться на экране. Записи в каталоге документов следующие:
- /Тип: Тип объекта PDF, который описывает каталог (в нашем случае это Каталог, так как это объект каталога документов).

- /Версия: Версия спецификации PDF, на основе которой был создан документ.
- /Extensions: информация о расширениях для разработчиков в этом документе.
- /Pages: косвенная ссылка на объект, являющийся корнем дерева страниц документа.
- /Dests: косвенная ссылка на объект, который является корнем именованного объекта назначения.
- /Outlines: косвенная ссылка на объект каталога структуры, который является корнем иерархии схемы документа.
- /Threads: косвенная ссылка на массив словарей потоков, представляющих темы статей документа.
- /Metadata: косвенная ссылка на поток метаданных, содержащий метаданные для документа.
Есть много других записей, которые мы видим как часть каталога документов, но не будем описывать их здесь. Подробности читатель может посмотреть в наших источниках. Пример каталога документов представлен ниже:
1 0 объект<< /Type /Catalog
/Pages 2 0 R
/PageMode /UseOutlines
/Outlines 3 0 R
>>
endobj
Дерево страниц
Доступ к страницам документа осуществляется через дерево страниц, которое определяет все страницы в документе PDF.
 Дерево содержит узлы, представляющие страницы PDF-документа, которые могут быть двух типов: промежуточные и конечные узлы. Промежуточные узлы также называются узлами дерева страниц, а конечные узлы называются объектами страниц.
Дерево содержит узлы, представляющие страницы PDF-документа, которые могут быть двух типов: промежуточные и конечные узлы. Промежуточные узлы также называются узлами дерева страниц, а конечные узлы называются объектами страниц. Простейшая структура дерева страниц может состоять из одного узла дерева страниц, который напрямую ссылается на все объекты страницы (таким образом, все объекты страницы являются листами).
Каждый узел в дереве страниц должен иметь следующие записи:
- /Type: Тип объекта PDF, который описывает этот объект (в нашем случае это Pages , так как мы говорим об узлах дерева страниц).
- /Parent: Должен присутствовать во всех узлах дерева страниц, кроме корневого, где эта запись не должна присутствовать. Эта запись указывает своего родителя.
- /Kids: должен присутствовать во всех узлах дерева страниц, кроме конечных, и указывает все дочерние элементы, непосредственно доступные из текущего узла.
- /Count: указывает количество конечных узлов, которые являются потомками этого узла в последующем дереве страниц.

Мы должны помнить, что дерево страниц не относится ни к чему в документе PDF, например к страницам или главам.
Базовый пример дерева страниц можно увидеть ниже:
2 0 obj<< /Тип /Страницы
/Дети [ 4 0 R
10 0 R
24 0 R
]
/Количество 3
>>
endobj
4 0 obj
<< /Тип /Страница
…
>>
endobj
10 0 obj
<< /Тип /Страница
…
>>
endobj
24 0 obj
<< /Тип /Страница
…
>>
endobj
Дерево страниц выше определяет объект Root с идентификатором 2, у которого есть три дочерних объекта, объекты 4, 10 и 20. Мы также можем видеть, что листья дерева страниц являются словарями, определяющими атрибуты одной страницы документа. Есть несколько атрибутов, которые мы можем использовать при их определении для каждой страницы документа.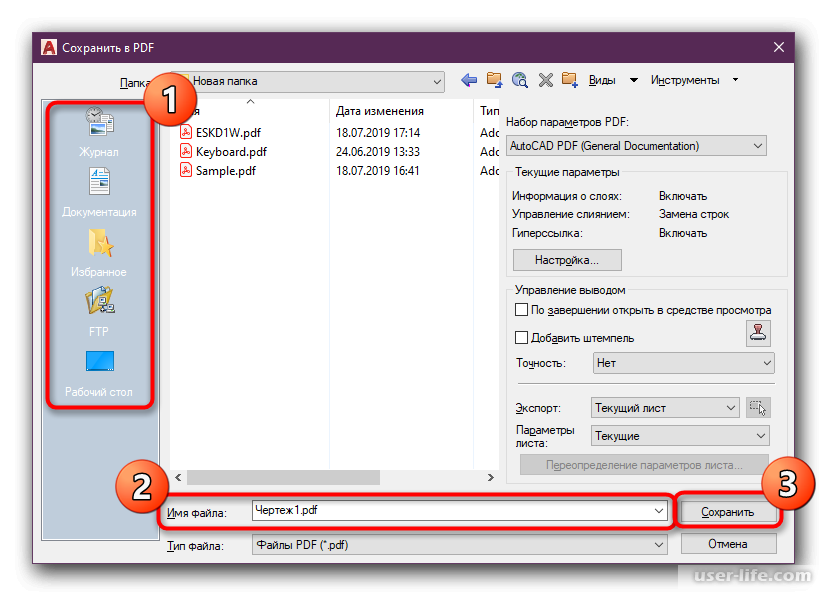
Мы рассмотрели базовую структуру PDF-документа и его типы данных. Если мы хотим начать поиск уязвимостей в читалках PDF, нам нужно изменить PDF-документ таким образом, чтобы читатель PDF не смог с ним справиться и вылетал. Обычно, если мы можем вызвать сбой программы для чтения PDF, мы обнаруживаем уязвимость в системе безопасности, которую мы можем использовать для выполнения произвольного кода на целевой машине.
Пример
В этой статье мы рассмотрим очень простой пример PDF-документа. Сначала нам нужно создать PDF-документ, чтобы затем попытаться его проанализировать. Чтобы создать документ PDF, давайте сначала создадим очень простой документ .tex, содержащий то, что можно увидеть на рисунке ниже:
действительно содержат много. Во-первых, мы определяем документ как статью, а затем включаем содержимое статьи в начальный и конечный документ. Мы включаем новый раздел с заголовком (Введение) и включаем статический текст «Hello World!».
Мы можем скомпилировать документ .
 tex в документ PDF с помощью команды pdflatex и указать имя файла .tex в качестве аргумента. Полученный PDF-файл выглядит так, как показано на рисунке ниже:
tex в документ PDF с помощью команды pdflatex и указать имя файла .tex в качестве аргумента. Полученный PDF-файл выглядит так, как показано на рисунке ниже: Рисунок 9: Результат
изображения, JavaScript или другие элементы.
Пример 1
Давайте посмотрим на структуру PDF-документа, которая представлена в выводе ниже:
%PDF-1.5%РФШ
3 0 obj <<
/Длина 138
/Фильтр /FlateDecode
>>
поток
…
конец потока
endobj
10 0 obj <<
/Длина2 1526
/Длина3 7193
/Длина4 0
/Длина 8194
/Фильтр /FlateDecode
>>
поток
…
конечный поток
endobj
12 0 obj <<
/Длина2 1509
/Длина3 9410
/Длина4 0
/Длина 10422
/Фильтр /FlateDecode
>>
поток
…
конец потока
endobj
15 0 obj <<
/Производитель (pdfTeX-1.
 40.12)
40.12) /Создатель (TeX)
/CreationDate (D:20121012175007+02’00’)
/ModDate (D:2019101201275000003
/Trapped /False
/PTEX.Fullbanner (Это pdfTeX, версия 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea версия 6.0.1)
>> endobj
6 0 obj <<
/Тип /ObjStm
/N 10
/Первый 65
/Длина 761
/Фильтр /FlateDecode
>>
поток
…
конец потока
endobj
16 0 obj <<
/type /xref
/Индекс [0 17]
/Размер 17
/W [1 2 1]
/Root 14 0 R
/Info 15 0 R
/ID [& LT; 1DC2E3E09458C9B4B8B67F56B57 <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Длина 60
/Фильтр /FlateDecode
>>
stream
…
endstream
endobj
startxref
20215
%%EOF
Существует довольно много сложных документов, необходимых для создания такого простого документа PDF. будет смотреться. Мы также должны помнить, что все закодированные потоки данных были удалены и заменены тремя точками для ясности и краткости.
будет смотреться. Мы также должны помнить, что все закодированные потоки данных были удалены и заменены тремя точками для ясности и краткости. Давайте представим каждый из разделов PDF. Заголовок можно увидеть на рисунке ниже:
Рисунок 10: Заголовок PDF
Тело можно увидеть на рисунке ниже:
Рисунок 11: Тело PDF
3 Раздел 90 x можно увидеть на рисунке ниже:
Рисунок 11: PDF xref
И, наконец, раздел Trailer представлен ниже:
Рисунок 12: трейлер PDF
Мы представили все разделы документа PDF, но нам еще предстоит их проанализировать. Заголовок PDF-документа стандартный и нам особо о нем говорить не нужно, а раздел body оставим на потом.
Вот почему мы должны сначала взглянуть на раздел внешних ссылок. Мы видим, что смещение от начала файла до таблицы xref составляет 20215 байт, что в шестнадцатеричном виде равно 0x4ef7.
 Если мы посмотрим на шестнадцатеричное представление файла, которое мы можем получить с помощью инструмента xxd, мы увидим то, что представлено на рисунке ниже:
Если мы посмотрим на шестнадцатеричное представление файла, которое мы можем получить с помощью инструмента xxd, мы увидим то, что представлено на рисунке ниже: Рисунок 13: Шестнадцатеричное представление файла
Выделенные байты лежат точно в начале смещения 20125 байт от начала файла. Предыдущие байты 0x0a — это новая строка, а текущие байты 0x31 представляют собой число 1, которое точно является началом таблицы внешних ссылок. Вот почему таблица внешних ссылок представлена косвенным объектом с идентификатором 16 и номером поколения 0. (Это должно иметь место для всех объектов, поскольку мы только что создали документ PDF и ни один из объектов еще не был изменен. Если мы посмотрите на весь документ в формате PDF, мы увидим, что это совершенно верно, все объекты имеют нулевой номер поколения.)
Параметр /Type косвенного объекта классифицирует его как таблицу внешних ссылок. Массив /Index содержит пару целых чисел для каждого подраздела в этом разделе.
 Первое целое число указывает номер первого объекта в подразделе, а второе целое число указывает количество записей в подразделе. В нашем примере номер объекта равен нулю, а в этом подразделе 17 записей. Это также определяется директивой /Size. Обратите внимание, что это число на единицу больше, чем наибольшее число любого номера объекта в подразделе. Атрибут /W указывает массив целых чисел, представляющих размер полей в записи перекрестной ссылки, что означает, что поля имеют размер один байт, два байта и один байт.
Первое целое число указывает номер первого объекта в подразделе, а второе целое число указывает количество записей в подразделе. В нашем примере номер объекта равен нулю, а в этом подразделе 17 записей. Это также определяется директивой /Size. Обратите внимание, что это число на единицу больше, чем наибольшее число любого номера объекта в подразделе. Атрибут /W указывает массив целых чисел, представляющих размер полей в записи перекрестной ссылки, что означает, что поля имеют размер один байт, два байта и один байт. После этого следует элемент /Root, указывающий каталог каталога для документа PDF как объект номер 14. /Info — это информационный каталог документа PDF, который содержится в объекте номер 15. Массив /ID требуется, поскольку Запись Encrypt присутствует и содержит две строки, составляющие идентификатор файла. Эти две строки используются в качестве входных данных для алгоритма шифрования.
Параметр /Length указывает длину ключа шифрования в битах; значение должно быть кратно 8 в диапазоне от 40 до 128 (значение по умолчанию — 40).
 В нашем случае длина ключа шифрования составляет 60 бит. Параметр /Filter указывает имя обработчика безопасности для этого документа; это также обработчик безопасности, который использовался для шифрования документа. В нашем случае это FlateDecode, который кодирует данные методом сжатия zlib/deflate.
В нашем случае длина ключа шифрования составляет 60 бит. Параметр /Filter указывает имя обработчика безопасности для этого документа; это также обработчик безопасности, который использовался для шифрования документа. В нашем случае это FlateDecode, который кодирует данные методом сжатия zlib/deflate. Мы видим, что другая часть таблицы внешних ссылок сжата, поэтому мы не можем ее прочитать. Мы могли бы, конечно, применить к сжатым данным какой-нибудь алгоритм декомпрессии zlib, но есть вариант получше. Зачем нам писать для этого программу, если инструмент уже существует? С помощью pdftk мы можем восстановить поврежденную таблицу внешних ссылок PDF с помощью следующей команды:
- # pdftk in.pdf output out.pdf
После этого файл out.pdf содержит следующие разделы xref и trailer:
Рисунок 14: xref и trailer
Ясно, что номера объектов /Root и /Info изменились и многое другое, но мы получили ключевые слова trailer и xref, которые определяют таблицу xref.
 Мы видим, что в таблице внешних ссылок 14 объектов.
Мы видим, что в таблице внешних ссылок 14 объектов. Мы могли бы продолжить и попытаться расшифровать и другие разделы, но это выходит за рамки данной статьи. Далее мы проверим документ, который не закодирован.
Пример 2
Давайте взглянем на образец PDF-документа, который доступен здесь. Некоторые объекты потока зашифрованы, но сейчас это не так важно. Поскольку мы уже знаем, как работать с PDF-документами, мы не будем терять слишком много слов на простых вещах.
Давайте откроем этот PDF-файл в текстовом редакторе, таком как gvim, и просмотрим раздел трейлера. Мы уже должны знать, что все PDF-документы следует читать с конца до начала. Трейлер представлен на рисунке ниже:
Рисунок 15: PDF трейлер
Давайте также представим Xref всего несколькими объектами (остальные для ясности отброшены):
Рисунок 16 : PDF xref
Мы видим, что /Root документа PDF содержится в объекте с идентификатором 221, а в объекте 222 есть дополнительная информация.
 Объект 221 является наиболее важным объектом во всем документе, поэтому давайте представим это:
Объект 221 является наиболее важным объектом во всем документе, поэтому давайте представим это: Рисунок 17: Объект 221
Мы видим, что этот объект действительно является Каталогом документов. Объект дерева страниц — 212, объект Outlines — 213, объект Names — 220, а объект OpenAction — 58. Мы не говорили ни о каких других типах, кроме объекта дерева страниц, поэтому продолжим разговор о дереве страниц. Только.
Объект Дерево страниц с ID 212 представлен на рисунке ниже:
Рисунок 18: Объект Дерево страниц
Таким образом, объект 212 содержит фактические страницы PDF-документа. Он содержит 10 страниц, что совершенно верно (мы можем проверить это, если откроем PDF-файл в любой программе для чтения PDF-файлов и проверим количество страниц).
Мы знаем, что атрибут Kids определяет все дочерние элементы, непосредственно доступные из текущего узла. В нашем случае есть два прямых дочерних узла с идентификаторами объекта 66 и 135.
 Объект 66 представлен ниже:
Объект 66 представлен ниже: Рисунок 19: Объект 66
Объект 66 содержит другие детские элементы с ID 57, 69, 75, 97, 108 и 120.
Рисунок 20: Объект 135
Объект 135 Далее определяет объекты 129, 138, 133 и 158.
Если мы посчитаем все элементы, то увидим, что элементов ровно 10, что означает 10 страниц из 10 страниц. Это также означает, что все представленные объекты на самом деле являются фактическими страницами PDF-документа и не содержат никаких дополнительных дочерних узлов.
Все представленные объекты объявляются одинаково, поэтому не будем рассматривать каждый из объектов по очереди. Вместо этого мы просто рассмотрим один объект, а именно объект 57. Объект 57 содержит объявление следующим образом:
Рисунок 21: Объект 57
Мы видим, что тип объекта — /Page что прямо подразумевает, что это конечный узел, представляющий одну из страниц PDF-документа.
 Содержимое этой страницы PDF можно найти в объекте 62:9.0003
Содержимое этой страницы PDF можно найти в объекте 62:9.0003 Рисунок 22: Объект 62
Мы видим, что фактическое содержимое страницы PDF закодировано с помощью FlateDecode, который представляет собой простой алгоритм кодирования zlib.
Заключение
Мы рассмотрели два примера того, как можно создавать PDF-документы. С полученными знаниями мы можем начать генерировать неправильные PDF-документы и передавать их различным программам для чтения PDF-файлов. В случае, если определенная программа чтения PDF дает сбой при чтении определенного документа PDF, этот документ содержит что-то, с чем программа чтения PDF не может справиться. Это подразумевает возможность уязвимости, которую необходимо изучить дополнительно.
В конце концов, если окажется, что уязвимость присутствует, мы можем даже написать PDF-документ, содержащий вредоносный код, который выполняется, когда жертва открывает PDF-документ с помощью уязвимой программы для чтения PDF-файлов на целевой машине.











Видео-курс
