Предложения с синтаксическим разбором
Синтаксический разбор предложения онлайн
Чтобы сделать синтаксический разбор предложений в тексте, введите текст в текстовое поле и нажмите кнопку разобрать.
Как программа делает разбор предложений?
Программа разбивает весь текст по словам и предложениям, далее разбирает каждое слово по
отдельности, выделяет морфологические признаки и начальную форму слова.
Оцените нашу программу ниже, оставляйте комментарии, мы обязательно ответим.
Морфологический разбор
Символов в тексте
Количество слов
Время выполнения:
- Показать все 9
- Глагол в личной форме 1
- Существительное 3
- Предлог 1
- Наречие 1
- Союз 1
- Инфинитив 1
- Прилагательное 1
Фонетический разбор
- ГВставьте
Разбор слова
- Вариант 1:
- Часть речи: Глагол в личной форме
- Начальная форма: ВСТАВИТЬ
- Все характеристики
- Стекст
Разбор слова
- Вариант 1:
- Часть речи: Существительное
- Начальная форма: ТЕКСТ
- Все характеристики
- ПРЕДЛв
Разбор слова
- Вариант 1:
- Часть речи: Предлог
- Начальная форма: В
- Споле
Разбор слова
- Вариант 1:
- Часть речи: Существительное
- Начальная форма: ПОЛ
- Все характеристики
- Нвыше,
Разбор слова
- Слово может быть разобрано в 4-х вариантах
- Вариант 1:
- Часть речи: Наречие
- Начальная форма: ВЫШЕ
- Вариант 2:
- Часть речи: Предлог
- Начальная форма: ВЫШЕ
- Вариант 3:
- Часть речи: Существительное
- Начальная форма: ВЫША
- Все характеристики
- Вариант 4:
- Часть речи: Прилагательное
- Начальная форма: ВЫСОКИЙ
- Все характеристики
- СОЮЗчтобы
Разбор слова
- Слово может быть разобрано в 2-х вариантах
- Вариант 1:
- Часть речи: Союз
- Начальная форма: ЧТОБЫ
- Вариант 2:
- Часть речи: Частица
- Начальная форма: ЧТОБЫ
- ИНФИНИТИВвыполнить
Разбор слова
- Вариант 1:
- Часть речи: Инфинитив
- Начальная форма: ВЫПОЛНИТЬ
- Все характеристики
- Псинтаксический
Разбор слова
- Вариант 1:
- Часть речи: Прилагательное
- Начальная форма: синтаксический
- Все характеристики
- Сразбор.
Разбор слова
- Вариант 1:
- Часть речи: Существительное
- Начальная форма: РАЗБОР
- Все характеристики
Характеристика предложения
| По цели высказывания | |
|---|---|
| По интонации (по эмоциональной окраске) | |
| По количеству грамматических основ | |
| По количеству главных членов предложения | |
| По наличию второстепенных членов | |
| - |
Об инструменте
После того как вы нажмете кнопку «Разобрать», вы получите результат синтаксического разбора
предложения. Сверху результата будет указано количество символов в тексте и количество слов.
Сверху результата будет указано количество символов в тексте и количество слов.
Каждая часть речи подсвечивается отдельным цветом, если вы хотите отображать только определенные части речи в предложении, выберите в панели инструментов нужную вам часть.
Приложение доступно в Google Play
Какой вариант разбора выбрать?
Омонимы — это слова одинаковые по написанию, но разные по значению, такие слова могут попасться в предложении и программа не может определить какой смысл несет слово. Здесь нужно выбрать подходящей разбор слова в предложение, смотрите по контексту.
Для этого вам помогут морфологические признаки слова, чтобы их увидеть наведите на слово и в
раскрывающемся меню выберите «Все характеристики».
Часть речи сверху слова
Чтобы показывать часть речи сверху слова, включите соответствующею функцию в настройке разбора.
Если у вас есть вопросы или пожелания, можете обратиться к нам по электронной почте [email protected]
- Морфологический разбор
- Разбор слова по составу
- Проверка орфографии
- Однокоренные слова
Кто-то
2 года назад
Прикольно конечно,но некоторые слова он не распознаёт вообще??
Стаканчик
2 года назад
Может просто ошибки в словах? Вот и не распознает.
Максим
2 года назад
Ошибок в словах нет. Не все программы идеальны, они часто могут работать не так, как положено
бешАннЫй УчЁнЫй
2 года назад
после запятых, и точек об'язательно нажимайте пробел иначе он пропустит слово которое совместно с запятой или точкой
Mimi
2 года назад
Сайт классный но иногда может ошибиться
W17
2 года назад
СПАСИБО, ОЧЕНЬ ПОЛЕЗНЫЙ САЙТ!!!
Алексей
2 года назад
Норм
Ксюша
2 года назад
просто супер.
Лана
2 года назад
не правильно разобрал: белой - это не существительное, а прилагательное.
демон
2 года назад
а сам подумать что это прилогательное?
Елисей
2 года назад
а как пишется слово прилагательное ты не подумал?
Ника
2 года назад
Слушай, человек просто высказал своё мнение ! Успокойся!
Синтаксический разбор предложения
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.

- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.

- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
https://uchim.org/russkij-yazyk/sintaksicheskij-razbor - uchim.org
Сказуемое
- Отмечаем, чем является сказуемое - простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое - какой формой глагола;
- составное глагольное - из чего оно состоит;
- составное именное - какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Лингвистические идеи для понимания естественного языка: анализ синтаксиса и составных частей
Анализ синтаксиса и составных частей
Человеческий язык невероятно сложен и постоянно меняется. Тем не менее, свободно говоря на одном или нескольких языках, люди могут понимать его почти неявно.
Лингвистика — это наука о человеческом языке, целью которой является описание его структуры, значения и того, как люди используют его в различных контекстах. При подходе к задаче понимания естественного языка (NLU), такой как классификация намерений, анализ настроений или ответы на вопросы, популярные архитектуры глубокого обучения, такие как LSTM и Transformers, могут проделать впечатляющую работу. Однако у этих подходов все еще есть проблемы с языковыми явлениями, которые мы, люди, понимаем без задней мысли.
Применение лингвистической теории может помочь нам приблизиться к пониманию языка на человеческом уровне, чтобы дополнить существующие алгоритмы и архитектуры для задач NLU. В этом сообщении блога мы возьмем один пример в качестве примера того, как может выглядеть это приложение лингвистической теории.
В этом сообщении блога мы возьмем один пример в качестве примера того, как может выглядеть это приложение лингвистической теории.
Давайте рассмотрим классификацию намерений, которую часто используют чат-боты и виртуальные помощники, чтобы понять, о чем спрашивает пользователь, чтобы дать правильный ответ. Модели классификации намерений обычно строятся для обеспечения единой классификации намерений для каждого высказывания. Итак, мы ожидаем, что модель классифицирует вопрос «Который час?» как вопрос о текущем времени, чтобы предоставить пользователю текущее время. Но люди не всегда разбивают свои предложения на отдельные намерения. Разговаривая с виртуальным помощником, вы можете спросить: «Который час и когда закрывается ресторан?» Или, разговаривая с Софией, помощником по виртуальным льготам Businessolver, на своем портале льгот для сотрудников, вы можете сказать: «Я хочу проверить свою франшизу, просмотреть свое заявление и изменить информацию о моем сыне». Модель, обученная извлекать одно намерение из одного предложения, никогда не сможет предоставить все детали, которые ищет пользователь, если она не сможет идентифицировать все вопросы, которые пользователь задает, в одном высказывании.
Что нам нужно, так это модель, которая может обеспечить классификацию одного или нескольких намерений, если пользователь задает более одного вопроса. Один из способов сделать это — обучить совершенно новый тип модели, которая может выводить несколько намерений. Это может быть дорогостоящей стратегией, если у нас еще нет помеченного набора данных высказываний с несколькими намерениями. Вместо этого предположим, что мы хотим продолжать использовать модель с одним намерением, которая у нас уже есть. Мы можем применить лингвистическую теорию, используя синтаксический разбор для расширения существующей модели.
Чтобы понять синтаксический анализ, нам сначала нужно иметь общее представление о том, что означает синтаксис в лингвистике. Давайте ненадолго отойдем от нашего примера классификации намерений.
Что такое синтаксический анализ?
Предложения структурированы, то есть предложения — это не просто набор слов, которые мы можем расположить в любом порядке, чтобы создать одно и то же значение. Рассмотрим следующие два предложения:
Рассмотрим следующие два предложения:
A. Собака укусила человека.
B. Мужчина укусил собаку.
Эти два предложения содержат одни и те же слова и одинаковый порядок тегов частей речи. Единственная разница заключается в порядке появления этих слов. В этом случае перестановка позиций «собака» и «человек» меняет подлежащее и дополнение глагола «укусить», тем самым меняя значение слов «кто был укушен» и «кто это сделал». кусаться.
Синтаксическая структура также играет роль в определении приемлемости предложений в языке. Например, если вы носитель английского языка, вы, вероятно, согласитесь с этим примером c. ниже не является грамматическим предложением:
C. Собака бит человек.
Опять же, это предложение содержит все те же слова, что и предложения в a. и б. но порядок этих слов нарушает наши правила ментальной грамматики английского языка. Документируя эти мыслительные правила, лингвисты могут создавать грамматики, которые затем можно использовать для комментирования структуры предложения.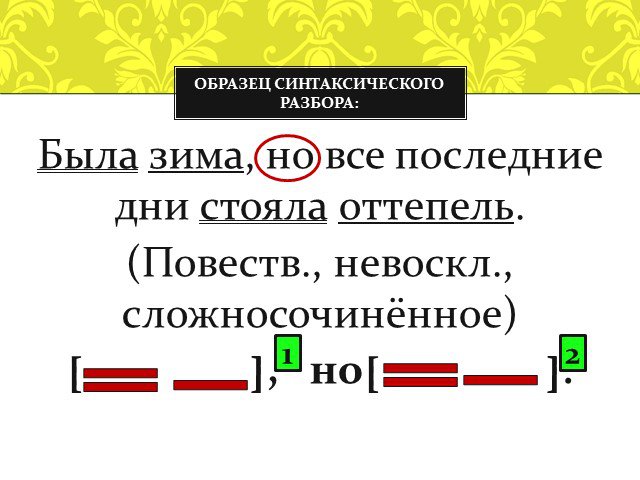
В этом контексте грамматика означает нечто несколько отличное от того, чему нас учат в начальной школе. Грамматика в лингвистике не используется, чтобы сказать говорящим, как использовать язык (например, «Не разделяйте инфинитивы!»). Вместо этого грамматики используются для описывают естественное использование языка говорящими. Например, наблюдая за носителями английского языка, мы можем узнать, что существительные, такие как «собака», «мужчина», «друг ее сестры» или «это», могут встречаться в одном и том же месте в предложении. Возьмите приведенные ниже предложения в качестве примера:
- Собака съела лакомство.
- Мужчина съел угощение.
- Подруга ее сестры съела угощение.
- Он съел угощение.
Хотя все четыре из этих предложений имеют разные значения, мы можем видеть, что четыре именные группы, которые мы описали выше, могут выполнять одну и ту же часть синтаксической структуры предложения — в этом случае все они являются подлежащим глагола «съел». . Примечательно, что независимо от длины этих именных словосочетаний они функционируют как единое целое в структуре предложения. Это свойство словосочетания функционировать как отдельная единица в предложении называется избирательный округ .
. Примечательно, что независимо от длины этих именных словосочетаний они функционируют как единое целое в структуре предложения. Это свойство словосочетания функционировать как отдельная единица в предложении называется избирательный округ .
Составляющие не ограничиваются именными словосочетаниями. Предложения могут содержать глагольные фразы (например, «укусить человека»), предложные фразы (например, «рядом с кроватью»), наречные фразы (например, «сонно») и т. д. Мы можем создавать грамматики, записывая правила, описывающие, как слова могут быть объединены. составлять члены и предложения. Взгляните на дерево синтаксического анализа для предложения «Собака укусила человека» ниже, а затем мы обсудим грамматику, которая использовалась для создания этого дерева.
Может быть не сразу понятно, что означают все метки и строки в этом дереве синтаксического анализа — мы доберемся до них через мгновение. Во-первых, давайте подумаем о составляющих этого дерева. Составляющая в дереве синтаксического анализа определяется как все слова, имеющие общий узел-предок. Ранее мы обсуждали, что «собака» является составной частью именной группы. Обратите внимание, что слова «the» и «собака» имеют общий предковый узел «NP» (существительное словосочетание). Точно так же мы можем видеть, что все слова в составе глагольной фразы «укусить человека» имеют общий предковый узел VP (глагольная фраза). Мы также можем использовать это дерево, чтобы увидеть, что не является составной частью . Например, последовательность слов «собака укусила» является составной частью , а не , потому что, хотя они имеют общий узел-предок S (предложение), этот узел S также является предком слова «человек». Другими словами, «собака укусила» не является составной частью, поскольку не включает все слова в общем предковом узле.
Составляющая в дереве синтаксического анализа определяется как все слова, имеющие общий узел-предок. Ранее мы обсуждали, что «собака» является составной частью именной группы. Обратите внимание, что слова «the» и «собака» имеют общий предковый узел «NP» (существительное словосочетание). Точно так же мы можем видеть, что все слова в составе глагольной фразы «укусить человека» имеют общий предковый узел VP (глагольная фраза). Мы также можем использовать это дерево, чтобы увидеть, что не является составной частью . Например, последовательность слов «собака укусила» является составной частью , а не , потому что, хотя они имеют общий узел-предок S (предложение), этот узел S также является предком слова «человек». Другими словами, «собака укусила» не является составной частью, поскольку не включает все слова в общем предковом узле.
Теперь, когда мы начинаем понимать, как идентифицировать составляющие, глядя на дерево, давайте посмотрим на грамматику, которая использовалась для создания этого дерева синтаксического анализа. Приведенная ниже грамматика представляет собой очень маленький игрушечный пример грамматики, которую можно использовать для описания структуры ограниченного числа предложений на английском языке.
Приведенная ниже грамматика представляет собой очень маленький игрушечный пример грамматики, которую можно использовать для описания структуры ограниченного числа предложений на английском языке.
S (Предложение) → NP VP NP (существительное) → Det Nom Nom (номинальное) → N Nom | Н VP (Глагол) → V NP N (существительное) → кошка | собака | мужчина | женщина | человек V (Глагол) → бит | укусы | лижет | лизнул Det (Определитель) → the
В этой нотации символ слева от стрелки (называемый неконечным символом ) может быть образован элементом(ами) справа от стрелки. Например, предложение (S) может быть образовано комбинацией именной фразы (NP), предшествующей глагольной фразе (VP). Символ вертикальной черты (|) означает «или», поэтому номинальное имя (Nom) может состоять либо из существительного (N), за которым следует номинальное, либо из одного существительного. Обратите внимание, что некоторые правила содержат только список слов справа от стрелки. Слова называются терминальные символы , потому что они встречаются только на листьях (узлах, у которых нет дочерних элементов) дерева синтаксического анализа. В большинстве случаев символ слева от правила с одним символом слова справа совпадает с тегом части речи для этого слова.
В большинстве случаев символ слева от правила с одним символом слова справа совпадает с тегом части речи для этого слова.
Используя эту грамматику, давайте построим дерево синтаксического анализа, которое мы видели выше. Существует несколько способов построить дерево синтаксического анализа, но для простоты мы построим его снизу вверх. Во-первых, мы смотрим на слова в нашем предложении «Собака больше человека» и смотрим, какие правила мы можем применить. Похоже, что все слова имеют соответствующее правило, которое дает метку этому отдельному слову. Давайте нарисуем эти метки:
Вы могли заметить, что мы добавили две метки к существительным в предложении – сначала метку существительного, затем именную метку. Хотя это важное различие в лингвистике, для нашего случая использования мы можем предположить, что существительные и именные по сути являются одной и той же категорией.
Теперь, когда у нас есть метки над каждым словом, что приводит к последовательности меток — Det, Nom, V Det, Nom — мы можем снова взглянуть на нашу грамматику, чтобы увидеть, какие правила могут применяться к последовательности меток. Поскольку у нас есть последовательность «Det Nom», мы можем применить правило NP → Det Nom. На самом деле, мы можем применить это правило дважды, так как в нашем предложении есть две последовательности «Det Nom»:
Поскольку у нас есть последовательность «Det Nom», мы можем применить правило NP → Det Nom. На самом деле, мы можем применить это правило дважды, так как в нашем предложении есть две последовательности «Det Nom»:
С помощью этого правила мы образовали две новые именные группы, и наша последовательность меток узлов теперь выглядит так: NP, V, NP. Порядок символов в правой части правила имеет значение при применении грамматики. Таким образом, хотя в нашей грамматике нет правила, образующего составную часть последовательности «NP V», — это правило, образующее составную часть последовательности «V NP»: VP → V NP. Поэтому мы можем добавить новый узел VP и соединить его с дочерними узлами V и NP:
Наконец, у нас есть только два узла в нашей последовательности меток: NP, VP. Это именно та последовательность меток, которая нам нужна для выполнения правила грамматики, формирующего предложение: S → NP VP. Добавляя этот узел, мы приходим к нашему окончательному дереву синтаксического анализа:
Мы знаем, что мы закончили синтаксический анализ предложения, потому что теперь у нас есть только один узел в верхней части дерева, и нет нижних узлов, которые были бы отсоединены от него. дерево – все они имеют родительский узел. Кроме того, единственный узел, который у нас остался, — это узел S, поэтому мы знаем, что создали структуру предложения, которая соответствует строке слов, с которой мы начали.
дерево – все они имеют родительский узел. Кроме того, единственный узел, который у нас остался, — это узел S, поэтому мы знаем, что создали структуру предложения, которая соответствует строке слов, с которой мы начали.
Важно отметить, что это очень упрощенный пример дерева синтаксического анализа избирательного округа. По этой теме можно еще многое узнать, включая различные фреймворки для синтаксического анализа (такие как x-bar, минимализм, HPSG, для вашего удовольствия) и различные синтаксические теории, которые сообщают правила в грамматике и результирующую древовидную структуру. Существуют также совершенно другие способы анализа предложения, такие как анализ зависимостей, который фокусируется на грамматических отношениях между отдельными словами (например, субъект, объект, модификатор и т. д.), а не на отношениях и структурах целых составляющих. Каждый из этих способов аннотирования структуры предложения может быть использован в различных приложениях НЛП. В этом сообщении блога давайте вернемся к нашему примеру классификации намерений и посмотрим, как даже это простое понимание синтаксического анализа избирательных округов может расширить систему NLU.
Применение синтаксиса к системам NLU:
Вспомните разговор с Софией, нашим помощником по виртуальным льготам, который мы обсуждали выше. Мы хотели, чтобы модель NLU понимала вопрос «Я хочу проверить свою франшизу, просмотреть свое заявление и отредактировать информацию о моем сыне». Пользователь спрашивает о трех разных задачах; «проверить мою франшизу», «просмотреть мою заявку» и «изменить информацию о моем сыне». В этом примере мы видим, что эти три задачи являются частью списка, где каждый из элементов списка представляет что-то, что пользователь хочет сделать. Мы знаем это, потому что списку предшествует фраза «Я хочу». Итак, как мы можем использовать синтаксический анализ избирательных округов, чтобы помочь нам решить эту проблему? Давайте посмотрим на дерево синтаксического анализа для этого предложения:
Это дерево выглядит немного иначе, чем примеры, которые мы видели раньше, но основная идея та же.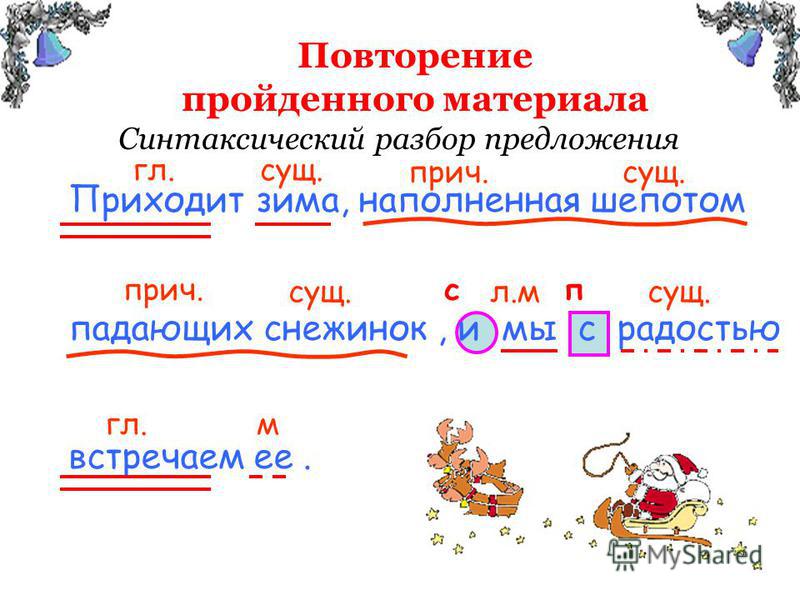 (Он был создан синтаксическим анализатором Stanford CoreNLP, о котором вы можете узнать больше здесь. Метки также немного отличаются, поскольку его грамматика основана на Penn Treebank, который использует свой собственный набор тегов.)
(Он был создан синтаксическим анализатором Stanford CoreNLP, о котором вы можете узнать больше здесь. Метки также немного отличаются, поскольку его грамматика основана на Penn Treebank, который использует свой собственный набор тегов.)
Верх структуры этого предложения выглядит почти идентично нашему предыдущему примеру — есть предложение (S), которое состоит из именной группы (NP), за которой следует глагольная группа (VP). Просто глагольная фраза в этом предложении немного сложнее, чем та, которую мы видели раньше. Частью этой сложности является наличие координированной глагольной фразы, то есть глагольной фразы, состоящей из двух или более других глагольных фраз (в данном случае трех других глагольных фраз). Мы можем визуально идентифицировать эту координированную глагольную фразу (обведена зеленым в дереве выше) по наличию более чем одного дочернего компонента и наличию координирующего союза CC (в данном случае «и»). Координируемые элементы — это ВП, обозначенные красными квадратами. Они являются потомками самой верхней ВП внутри зеленого круга, за исключением пунктуации и сочинительного союза. Если мы посмотрим на каждую из этих скоординированных глагольных фраз, мы увидим, что это именно то, что мы надеялись идентифицировать — три разных запроса, которые делает пользователь — «проверить мою франшизу», «просмотреть мою претензию» и «изменить информацию о моем сыне». ».
Они являются потомками самой верхней ВП внутри зеленого круга, за исключением пунктуации и сочинительного союза. Если мы посмотрим на каждую из этих скоординированных глагольных фраз, мы увидим, что это именно то, что мы надеялись идентифицировать — три разных запроса, которые делает пользователь — «проверить мою франшизу», «просмотреть мою претензию» и «изменить информацию о моем сыне». ».
Если наша система NLU имеет доступ к дереву синтаксического анализа для этого предложения, мы могли бы использовать наши знания о структуре координатной фразы, чтобы извлечь три запроса, которые делает пользователь.
Как София будет использовать синтаксис?
В случае Софии, виртуального помощника Businesssolver, мы работаем над тем, как внедрить этот синтаксический анализ в наше распознавание намерений, чтобы София могла понимать, когда пользователи задают несколько вопросов одновременно. В идеале мы хотели бы, чтобы София могла сказать: «Я понимаю, что вы хотите поговорить о вашей франшизе, ваших требованиях и вашем иждивении. С чего бы вы хотели начать?» Затем пользователь может выбрать, какую тему обсудить в первую очередь, и София предложит пользователю вернуться к другим темам позже в разговоре.
С чего бы вы хотели начать?» Затем пользователь может выбрать, какую тему обсудить в первую очередь, и София предложит пользователю вернуться к другим темам позже в разговоре.
Для этого нашему экстрактору списков на основе синтаксиса потребуется дополнительная работа. Хотя синтаксический анализ группы может надежно помочь нам извлечь элементы списка, у нас нет никакой гарантии, что эти элементы действительно соответствуют отдельным темам, как это определено нашими намерениями.
Например, в предложении «Я проверил свою франшизу и просмотрел свое заявление, но я не вижу, где изменить информацию о моем сыне», мы, вероятно, извлекли бы элементы списка «проверил мою франшизу» и «просмотрел свое заявление». ” Но пользователь действительно спрашивает об информации своего сына. Есть несколько способов смягчить эту проблему, один из которых заключается в поиске подсказок, указывающих на то, что в списке говорится о нескольких темах, например, в списке, которому предшествуют слова «Я хочу». Другой возможностью может быть рассмотрение соединения, которое присоединяется к элементу списка. Мы могли бы найти образец, который показывает, что мы должны относиться к спискам, соединенным с помощью «но», иначе, чем к спискам, соединенным с помощью «и». можно быть уверенным, что они будут надежно давать правильный результат.
Другой возможностью может быть рассмотрение соединения, которое присоединяется к элементу списка. Мы могли бы найти образец, который показывает, что мы должны относиться к спискам, соединенным с помощью «но», иначе, чем к спискам, соединенным с помощью «и». можно быть уверенным, что они будут надежно давать правильный результат.
Надеюсь, этот пример даст вам представление о том, как синтаксический анализ групп может быть полезен в задачах NLU. Подводя итог: поскольку синтаксис предложения так тесно связан с его значением, мы можем творчески использовать эту структуру, чтобы помочь приложениям искусственного интеллекта понимать язык более близко к тому, как это делают люди. Это может быть особенно полезно при дополнении нейронных подходов, которые часто являются «черным ящиком». То есть мы не знаем, какие функции или закономерности использует модель для принятия решений, поэтому мы не всегда можем предсказать, как она будет действовать. Добавление слоя синтаксической логики, основанной на правилах, может быть одним из способов снизить этот риск и использовать человеческое понимание структуры предложений для обучения компьютеров обработке языка. 0005
0005
Если вы хотите больше узнать о синтаксисе и синтаксическом разборе, в книге Jurafsky & Martin «Обработка речи и языка» есть несколько глав, которые дают хорошее введение в такие темы, как грамматика групп, анализ групп и логическое представление значения предложения.
Будьте в курсе этой серии блогов
Уведомления по электронной почте
Синтаксический анализ — документация lambeq 0.2.7
lambeq Диаграммы строк основаны на грамматике предварительной группы для отслеживания типов и взаимодействий между словами в предложении. Когда требуется подробный синтаксический вывод (как в случае DisCoCat), синтаксическое дерево должно быть предоставлено статистическим синтаксическим анализатором. Однако, поскольку формализм предгрупповой грамматики не особенно хорошо известен в сообществе НЛП, в настоящее время не существует предгруппового синтаксического анализатора с широким охватом, который мог бы автоматически предоставлять синтаксические производные. Для решения этой проблемы
Для решения этой проблемы lambeq обеспечивает переход от вывода в ближайшем альтернативном формализме грамматики, а именно комбинаторной категориальной грамматике (CCG), к строковой диаграмме, которая точно кодирует синтаксическую структуру предложения в предгрупповой форме [YK2021]. Благодаря наличию множества надежных инструментов синтаксического анализа CCG это позволяет преобразовывать большие корпуса с предложениями произвольной длины и синтаксической структуры в предгрупповую форму и форму DisCoCat.
Начиная с версии 0.2.0, стандарт Установка lambeq включает современный синтаксический анализатор CCG на основе [SC2021], полностью интегрированный в набор инструментов. Этот парсер предоставляется под названием Bobcat. Кроме того, lambeq реализует подробный интерфейс в пакете text2diagram , который позволяет подключаться к одному из многих доступных в настоящее время внешних инструментов анализа CCG. Например, lambeq также поставляется с поддержкой depccg 1 [YNM2017], быстрого парсера с удобным интерфейсом Python.
Дополнительные внешние синтаксические анализаторы могут быть доступны для lambeq путем расширения класса CCGParser для создания подкласса-оболочки, который инкапсулирует необходимые вызовы и переводит выходные данные соответствующего синтаксического анализатора в формат CCGTree .
Наконец, для пользователей, которые предпочитают не устанавливать набор инструментов, lambeq также включает веб-класс синтаксического анализатора, который отправляет запросы на синтаксический анализ в онлайн-API, так что локальная установка полного синтаксического анализатора CCG больше не требуется. – хотя настоятельно рекомендуется для большинства практических применений инструментария.
Совместимость с CCG делает доступным для lambeq широкий спектр языковых ресурсов. Например, lambeq содержит класс CCGBankParser , который позволяет преобразовывать весь корпус CCGBank 2 [HS2007] в строковые диаграммы.










Видео-курс
