Что значит нижний регистр
Символы, которые можно использовать при вводе имени пользователя и пароля
Первая страница > Руководство по безопасности > Начало работы > Настройка аутентификации администратора > Регистрация и замена администраторов > Символы, которые можно использовать при вводе имени пользователя и пароля
Для ввода имени пользователя и пароля разрешается применять следующие символы. Имя пользователя и пароль следует вводить с учетом регистра.
Заглавные латинские буквы: от A до Z (26 символов)
Строчные латинские буквы: от a до z (26 символов)
Цифры от 0 до 9 (10 символов)
Символы: (пробел) ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _` { | } ~ (33 символа)
Имя пользователя для входа в систему
Пробелы, двоеточия и кавычки не допускаются.
Это поле не может оставаться пустым.
Длина ограничивается 32 символами.
В регистрационном имени администратора длиной до 8 символов должны содержаться нецифровые символы (т.е. символы, не являющиеся числами). Если же оно состоит только из цифр, то его длина должна составлять не менее 9 символов.
Пароль для входа в систему
Максимально допустимая длина пароля для администраторов и супервайзера составляет 32 символа, тогда как для пользователей длина ограничивается 128 символами.
В отношении типов символов, которые могут использоваться для задания пароля, никаких ограничений не установлено. В целях безопасности рекомендуется создавать пароли, содержащие буквы верхнего и нижнего регистров, цифры и другие символы. Чем большее число символов используется в пароле, тем более трудной является задача его подбора для посторонних лиц.
В подразделе [Политика паролей] раздела [Расширенная безопасность] вы можете установить требование в отношении обязательного включения в пароль букв верхнего и нижнего регистров, цифр и других символов, а также минимально необходимое количество символов в пароле. Для получения сведений о формировании политики паролей см. Настройка функций расширенной безопасности.
Правда о регистре символов, которую должны знать программисты / Хабр
На
конференцииNorth Bay Python в 2018 году я делал
докладоб именах пользователей. Информация из доклада по большей части была собрана мною за 12 лет поддержки
django-registration. Этот опыт дал мне гораздо больше знаний, чем я планировал получить, о том, насколько сложными могут быть «простые» вещи.
В начале доклада я, правда, упомянул, что это не будет очередное разоблачение из серии «заблуждения по поводу Х, в которые верят программисты». Таких разоблачений можно найти сколько угодно. Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Поэтому в своём докладе я постарался как можно лучше объяснить некоторые проблемы и пояснить, как их решать – такой подход мне нравится гораздо больше. Одна из тем, которой я коснулся лишь вскользь (это был всего один слайд и пара упоминаний на других слайдах) – это сложности, которые могут быть связаны с регистром символов. Для задачи, которую я обсуждал – сравнение идентификаторов без учёта регистра – есть официальный Правильный Ответ™, и в докладе я дал лучшее из известных мне решений, использующее только стандартную библиотеку Python.
Однако я кратко упомянул о более глубоких сложностях с регистром символов в Unicode, и хочу посвятить некоторое время описанию подробностей. Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
И ещё одно: в Unicode полно терминологии. В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
Регистров бывает больше двух
Носители европейских языков привыкли к тому, что в их языках регистр символов используется для обозначения конкретных вещей. К примеру, в английском [и русском] языках мы обычно начинаем предложения с буквы в верхнем регистре, а продолжаем чаще всего буквами в нижнем регистре. Также имена собственные начинаются с букв в верхнем регистре, и многие акронимы и аббревиатуры записываются в верхнем регистре.
И мы обычно считаем, что регистров существует всего два. Есть буква «А», и есть буква «а». Одна в верхнем, другая в нижнем регистре – не правда ли?
Однако в Unicode есть три регистра. Есть верхний, есть нижний, и есть титульный регистр [titlecase]. В английском языке так записываются названия. Например, «Avengers: Infinity War». Обычно для этого первая буква каждого слова просто пишется в верхнем регистре (и в зависимости от разных правил и стилей, некоторые слова, например, артикли, не пишутся с заглавных букв).
В стандарте Unicode дан такой пример символа в титульном регистре: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. Выглядит он так: Dz.
Подобные символы иногда требуются для обработки негативных последствий одного из ранних решений разработки стандарта Unicode: совместимости с существующими текстовыми кодировками в обе стороны. Для Unicode было бы удобнее составлять последовательности при помощи имеющихся у стандарта возможностей по комбинированию символов. Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа "é" есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Хотя кодовая позиция этого символа совпадает с его байтовым значением из latin-1, полагаться на это не стоит. Вряд ли кодирование символов в Unicode сохранит эти позиции. К примеру, в UTF-8 кодовая позиция U+00E9 записана в виде байтовой последовательности 0xc3 0xa9.
И, конечно, в уже существующих кодировках есть символы, которым требовалось особое обхождение при использовании титульного регистра, из-за чего они были включены в Unicode «как есть». Если хотите посмотреть на них, поищите в своей любимой базе Unicode символы из категории Lt («Letter, titlecase»).
Есть несколько способов определить регистр
В стандарте Unicode (§4.2) перечислено три разных определения регистра. Возможно, выбор одного из трёх за вас делает ваш язык программирования; в противном случае, ваш выбор будет зависеть от конкретной цели. Вот эти определения:
- Символ находится в верхнем регистре, если он принадлежит к категории Lu («Letter, uppercase»), и в нижнем регистре, если принадлежит к категории Ll («Letter, lowercase»). В стандарте признаётся ограниченность этого определения: каждый конкретный символ приходится относить только к одной из категорий. Из-за этого многие символы, которые «должны находиться» в верхнем или нижнем регистре не удовлетворят этому требованию потому, что принадлежат к какой-то другой категории.
- Символ находится в верхнем регистре, если он унаследовал свойство Uppercase, и в нижнем регистре, если унаследовал свойство Lowercase. Это комбинация определения один с другими свойствами символов, среди которых может быть и регистр.
- Символ находится в верхнем регистре, если после применения к нему регистрового отображения в верхний регистр он не меняется. Символ находится в нижнем регистре, если после применения к нему регистрового отображения в нижний регистр он не меняется. Довольно общее определение, однако и оно может вести себя неинутитивно.
Если вы работаете с ограниченным подмножеством символов (конкретно, с буквами), то вам может хватить и 1-го определения. Если ваш репертуар шире – в него входят похожие на буквы символы, не являющиеся буквами, вам может подойти 2-е определение. Его рекомендует и стандарт Unicode, §4.2:
Программистам, манипулирующим строками в Unicode, стоит работать с такими строковыми функциями, как isLowerCase (и её функциональным родственником toLowerCase), если они не работают со свойствами символов напрямую.
Упомянутая здесь функция определяется в §3.13 стандарта Unicode. Формально в 3-м определении используются функции isLowerCase и isUpperCase из §3.13, определяемые в терминах фиксированных позиций в toLowerCase и toUpperCase соответственно.
Если в вашем языке программирования есть функции для проверки или преобразования регистра строк или отдельных символов, стоит изучить, какие из упомянутых определений используются в реализации. Если вам интересно, то методы isupper() и islower() в Python используют 2-е определение.
Нельзя понять регистр символа по его внешнему виду или названию
По внешнему виду многих символов можно понять, в каком они регистре. К примеру, «А» находится в верхнем регистре. Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
На самом же деле она наследует свойство Lowercase, поэтому по определению №2 она находится в нижнем регистре, несмотря на то, что визуально напоминает заглавную Н, а в названии есть слово «CAPITAL».
У некоторых символов вообще нет регистра
Определение 135 в §3.13 стандарта Unicode гласит:
Символ С имеет регистр тогда и только тогда, когда у С есть свойство Lowercase или Uppercase, или значение параметра General_Category равно Titlecase_Letter.
Значит, очень много символов из Unicode – на самом деле, большая их часть – регистра не имеет. Не имеют смысла вопросы об их регистре, а изменения регистра на них не действуют. Однако мы можем получить ответ на этот вопрос по определению №3.
Некоторые символы ведут себя так, будто у них несколько регистров
Из этого следует, что если вы используете определение №3, и задаёте вопрос, находится ли символ без регистра в верхнем или нижнем регистре, вы получите ответ «да».
В стандарте Unicode даётся пример (таблица 4-1, строка 7) символа U+02BD MODIFIER LETTER REVERSED COMMA (который выглядит так: ʽ). У него нет унаследованных свойств Lowercase или Uppercase, он не принадлежит к категории Lt, поэтому регистра у него нет. При этом преобразование в верхний регистр его не меняет, и преобразование в нижний регистр его не меняет, поэтому по 3-му определению он отвечает «да» на оба вопроса: «принадлежишь ли ты к верхнему регистру?» и «принадлежишь ли ты к нижнему регистру?»
Кажется, что из-за этого может возникнуть никому не нужная путаница, однако смысл в том, что определение №3 работает с любой последовательностью символов Unicode, и позволяет упростить алгоритмы преобразования регистра (символы без регистра просто превращаются сами в себя).
Регистр зависит от контекста
Можно подумать, что если таблицы преобразования регистра в Unicode покрывают все символы, то это преобразование заключается просто в поиске нужного места в таблице. К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
Один из примеров, в котором этот подход не работает – греческий язык. Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
А это значит, что у регистра нет взаимной однозначности или транзитивности. Ещё один пример — ß (U+00DF LATIN SMALL LETTER SHARP S, или эсцет). В верхнем регистре это будет «SS», хотя теперь существует и другая его форма в верхнем регистре (ẞ, U+1E9E LATIN CAPITAL LETTER SHARP S). А при переводе «SS» в нижний регистр получается «ss», поэтому (используя терминологию стандарта Unicode для преобразования регистра): toLowerCase(toUpperCase(ß)) != ß.
Регистр зависит от локали
В разных языках правила преобразования регистра разные. Самый популярный пример: i (U+0069 LATIN SMALL LETTER I) и I (U+0049 LATIN CAPITAL LETTER I) в большинстве локалей преобразовываются друг в друга – в большинстве, но не во всех. В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
Сам Unicode не обрабатывает все возможные правила преобразования регистра для всех локалей. В базе данных Unicode есть только общие правила преобразования всех символов, не зависящие от локали. Также там есть особые правила для некоторых языков и составных форм – литовского языка, тюркских языков, некоторых особенностей греческого. Всего остального там нет. §3.13 стандарта упоминает это и рекомендует при необходимости вводить правила преобразования, зависящие от локали.
Один пример будет знаком англоговорящим – это титульный регистр определённых имён. «o’brian» нужно преобразовывать в «O’Brian» (а не в «O’brian»). Однако при этом «it’s» нужно преобразовывать в «It’s», а не в «It’S». Ещё один пример, который не обрабатывается в Unicode – это голландское буквосочетание "ij", которое при преобразовании в титульный регистр должно переходить в верхний регистр целиком, если стоит в начале слова. Таким образом, большой залив в Нидерландах в титульном регистре будет "IJsselmeer", а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Сравнение без учёта регистра требует приведения к сложенному регистру
Возвращаясь к материалу, представленному в докладе. Сложность работы с регистром в Unicode означает, что регистронезависимое сравнение нельзя проводить при помощи стандартных функций приведения к нижнему или верхнему регистру, имеющихся во многих языках программирования. Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Можно решить, что приведение к сложенному регистру похоже на приведение к нижнему регистру – но это не так. Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
На одном из слайдов моего доклада рекомендации Unicode Technical Report #36 реализуются на Python настолько полно, насколько это возможно. Проводится нормализация NFKC и потом для полученной строки вызывается метод casefold() (доступный только в Python 3+). И даже при этом некоторые крайние случаи выпадают, и это не совсем то, что рекомендуется для сравнения идентификаторов. Сначала плохие новости: Python не выдаёт наружу достаточно свойств Unicode для того, чтобы отфильтровать символы, которых нет в XID_Start или XID_Continue или символы, имеющие свойство Default_Ignorable_Code_Point. Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5.1.
Хорошие новости: большинство этих крайних случаев не связано с какими-либо реальными рисками безопасности, создаваемыми рассматриваемыми символами. И складывание регистра в принципе не определяется как операция, сохраняющая нормализацию (отсюда и отображение NFKC_Casefold, которое повторно нормализуется до NFC после складывания регистра). Как правило, при сравнении вас не волнует, будут ли обе строки нормализованы после предварительной обработки. Вас заботит, не противоречива ли предварительная обработка, и гарантирует ли она, что только строки, которые «должны» отличаться впоследствии, будут отличаться впоследствии. Если вас это беспокоит, вы можете вручную выполнить повторную нормализацию после сложения регистра.
Пока достаточно
Эта статья, как и предыдущий доклад, не является исчерпывающей, и вряд ли можно уложить весь этот материал в единственный пост. Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию. Поэтому в принципе, можно остановиться и тут.
Не будет ли наивной моя надежда на то, что другие люди перестанут писать разоблачения из серии «заблуждения по поводу Х, в которые верят программисты», и начнут уже писать статьи типа «правда, которую должны знать программисты»?
Переключить клавиатуру из нижнего регистра в верхний регистр на iPhone / iPad [How-to]
Клавиатуры на устройствах iOS всегда видели полезные улучшения с каждым обновлением программного обеспечения, выпущенным Apple. Во время выпуска iOS 9 компания Apple представила значительные изменения в клавиатурах iPhone и iPad. Вы всегда можете показать клавиши UPPERCASE на вашем iPhone и iPad во время использования клавиатуры.
Эта функция работает в приложениях iOS по умолчанию, а также в сторонних приложениях, в которых предполагается использовать клавиатуру. Без лишних слов, давайте перейдем к ступеням.
Почему вы всегда должны показывать клавиши UPPERCASE на устройствах iOS?
Цель этого взлома - сделать клавиши более заметными, чтобы люди с плохим зрением могли правильно видеть клавиши во время набора текста. Когда вы отключите «Показать строчные ключи», буквы на клавиатуре станут заглавными, даже если вы не используете опции Shift или Caps Lock. При выборе по умолчанию (Показать строчные клавиши) вам нужно нажать на Shift или Caps Lock, чтобы включить прописные клавиши.
Как переключить клавиатуру с нижнего регистра на верхний регистр на iPhone / iPad
Шаг 1. Запустите приложение «Настройки» на вашем iPhone / iPad → Нажмите « Общие».
Шаг 2. Теперь нажмите на Доступность.
Шаг 3. Далее, прокрутите вниз и нажмите на клавиатуре (эта опция доступна в разделе 3D Touch).
Шаг № 4. Переключить Показать строчные клавиши ВЫКЛ.
Это оно!
Вы преобразовали клавиатуру из строчных в прописные только по внешнему виду.
Подписание ...
С большими буквами пользователи могут быстро выбирать клавиши для ввода длинных сообщений, используя такие приложения, как Mail и WhatsApp.
Взгляните также на эти посты:
- Как исправить прогнозирующую клавиатуру Emoji, не работающую на iPhone или iPad
- Как выделить текст в iPhone, используя клавиатуру в качестве трекпада
- Лучшие клавиатурные приложения для iPhone и iPad, которые вы не должны пропустить
- Сочетания клавиш Keynote для iPad: ускорение рабочего процесса
Хотели бы вы показать клавиши UPPERCASE на вашем iPhone или iPad? Поделитесь своими отзывами с нами на Facebook, Twitter и Telegram. Загрузите наше приложение, чтобы прочитать другие полезные учебники.
Знакомство с пакетом Strings в Go
Введение
Пакет strings в Go позволяет использовать ряд функций для работы со строковым типом данных. Эти функции позволяют нам легко изменять строки и совершать с ними другие манипуляции. Функции можно сравнить с определенными действиями, которые мы совершаем с элементами нашего кода. Встроенные функции — это функции, которые определены в языке программирования Go и доступны для использования без каких-либо сложностей.
В этом обучающем руководстве мы рассмотрим несколько различных функций, которые мы можем использовать для работы со строками в Go.
Перевод строк в верхний и нижний регистр
Функции strings.ToUpper и strings.ToLower будут возвращать строку со всеми символами оригинальной строки, переведенными в верхний или нижний регистр. Поскольку строки — это неизменяемый тип данных, возвращенная строка будет представлять собой новую строку. Любые символы в строке, которые не являются буквам, останутся неизменными.
Для преобразования строки "Sammy Shark"в верхний регистр, используйте функцию strings.ToUpper:
ss := "Sammy Shark" fmt.Println(strings.ToUpper(ss)) Output
SAMMY SHARK Для преобразования строки в нижний регистр используйте следующий код:
fmt.Println(strings.ToLower(ss)) Output
sammy shark Поскольку вы используете пакет strings, вам нужно предварительно импортировать его в программу. Программа для преобразования строки в строку с символами в верхнем и нижнем регистре будет выглядеть следующим образом:
package main import ( "fmt" "strings" ) func main() { ss := "Sammy Shark" fmt.Println(strings.ToUpper(ss)) fmt.Println(strings.ToLower(ss)) } Функции strings.ToUpper и strings.ToLower упрощают оценку и сравнение строк, обеспечивая единообразие их регистра. Например, если пользователь пишет свое имя в нижнем регистре, мы все равно сможем определить, содержится ли его имя в нашей базе данных, проверив версию строки в верхнем регистре.
Функции поиска строки
Пакет strings имеет ряд функций, которые помогают определить, содержит ли строка конкретную последовательность символов.
| Функция | Использование |
|---|---|
strings.HasPrefix | Поиск строки с начала |
strings.HasSuffix | Поиск строки с конца |
strings.Contains | Поиск в любом месте строки |
strings.Count | Счетчик количества появлений строки в тексте |
Функции strings.HasPrefix и strings.HasSuffix позволяют проверить, начинается строка с определенного набора символов или заканчивается ли строка определенным набором символов.
Например, чтобы проверить, начинается ли строка "Sammy Shark" с Sammy и заканчивается ли она словом Shark:
ss := "Sammy Shark" fmt.Println(strings.HasPrefix(ss, "Sammy")) fmt.Println(strings.HasSuffix(ss, "Shark")) Output
true true Вы можете использовать функцию strings.Contains для проверки того, содержит ли строка "Sammy Shark" последовательность символов Sh:
fmt.Println(strings.Contains(ss, "Sh")) Output
true Наконец, чтобы узнать, сколько раз символ S появляется в выражении Sammy Shark:
fmt.Println(strings.Count(ss, "S")) Output
2 Примечание. Все строки в Go чувствительны к регистру. Это означает, что строка Sammy не аналогична строке sammy.
Использование символа s в нижнем регистре для подсчета количества появлений в строке Sammy Shark не дает тот же результат, что и использование символа S в верхнем регистре:
fmt.Println(strings.Count(ss, "s")) Output
0 Так как S отличается от s, функция будет возвращать значение 0.
Функции для работы со строками оказываются полезны, когда вы хотите сопоставить строки или выполнить поиск строк в вашей программе.
Определение длины строки
Встроенная функция len() возвращает количество символов в строке. Эта функция полезна, когда вам нужно установить минимальную или максимальную длину пароля или установить определенный лимит для больших строк для использования сокращений.
Для демонстрации работы этой функции мы определим длину строки, которая содержит целое предложение:
import ( "fmt" "strings" ) func main() { openSource := "Sammy contributes to open source." fmt.Println(len(openSource)) } Output
33 Мы задали переменную OpenSource, которая соответствует строке "Sammy contributes to open source.", а затем передали эту переменную в функцию len() с помощью конструкции len(openSource). В конечном итоге мы передали вывод нашей функции в функцию fmt.Println(), чтобы увидеть результат выполнения программы на экране.
Необходимо учитывать, что функция len() будет считать любые символы, которые содержатся внутри двойных кавычек, включая буквы, числа, символы пробела и специальные символы.
Функции для манипуляций со строками
Функции strings.Join, strings.Split и strings.ReplaceAll предоставляют ряд дополнительных методов манипуляций со строками в Go.
Функция strings.Join полезна для объединения набора строк в новую единую строку.
Для создания разделенной запятой строки из набора строк мы будем использовать эту функцию следующим образом:
fmt.Println(strings.Join([]string{"sharks", "crustaceans", "plankton"}, ",")) Output
sharks,crustaceans,plankton Если мы хотим добавлять запятую и пробел между значениями строк в нашей новой строке, мы можем просто перезаписать наше выражение с пробелом после запятой: strings.Join([]string{"sharks", "crustaceans", "plankton"}, ", ").
Так же, как мы можем объединять строки, мы можем и разбивать строки на несколько отдельных строк. Для этого мы можем использовать функцию strings.Split и выполнить разделение строки по пробелам:
balloon := "Sammy has a balloon." s := strings.Split(balloon, " ") fmt.Println(s) Output
[Sammy has a balloon] В результате мы получим набор строк. Поскольку мы использовали strings.Println, очень трудно сказать, какой мы получили результат, посмотрев на вывод. Чтобы убедиться, что мы получили набор строк, используйте функцию fmt.Printf с оператором %q, чтобы вывести строки:
fmt.Printf("%q", s) Output
["Sammy" "has" "a" "balloon."] Еще одной полезной функцией, помимо strings.Split, является функция strings.Fields. Разница между этими функциями состоит в том, что strings.Fields будет игнорировать все пробелы и разделять строку по реальным полям в строке:
data := " username password email date" fields := strings.Fields(data) fmt.Printf("%q", fields) Output
["username" "password" "email" "date"] Функция strings.ReplaceAll получает оригинальную строку и возвращает обновленную строку с определенными изменениями.
Давайте представим, что Sammy потерял свой шарик. Поскольку у Sammy больше нет шарика, мы изменим подстроку "has" (есть) оригинальной строки ballon на "had" (был) в новой строке:
fmt.Println(strings.ReplaceAll(balloon, "has", "had")) В скобках первым параметром указан balloon, переменная, которая хранит оригинальную строку; далее идет подстрока "has", которую мы хотим заменить, а третьим параметром идет "had", подстрока, которую мы хотим вставить в оригинальную строку. Наш вывод будет выглядеть следующим образом, когда мы добавим этот код в программу:
Output
Sammy had a balloon. Использование функций strings.Join, strings.Split и strings.ReplaceAll позволяет получить дополнительные возможности для манипуляций со строками в Go.
Заключение
В этом обучающем руководстве мы изучили ряд стандартных функций пакета string для строковых данных, которые вы можете использовать для работы со строками в ваших программах Go.
Дополнительную информацию о других типах данных вы можете получить в статье Знакомство с типами данных, а узнать больше о строках можно из руководства Начало работы со строками.
Учет верхнего и нижнего регистра в Excel для формулы поиска
Функция ВПР и другие подобные ей функции поиска имеют один недостаток – они не могут различать верхний и нижний регистр символов (большие и маленькие буквы). Данный недостаток может оказаться весьма раздражающим, а иногда существенно усложняющим для определенного рода задач. Если поставленная перед вами задача в Excel требует учитывать регистр символов в тексте значений, тогда функцию ВПР (и подобные ей) следует заменить формулой.
Как заставить формулу Excel различать большие и маленькие буквы
Допустим, что содержимое исходного значения для поиска находится в ячейке D1, а таблица, по которой будет выполнен поиск, находится в диапазоне A1:B10.
Чтобы найти необходимые значения:
- В ячейку E1 введите следующую формулу:
- После ввода формулы, для подтверждения нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter, так как формула должна быть выполнена в массиве. Если все сделано правильно в строке формул появятся фигурные скобки { }.
Пример таблицы и работы формулы показано на рисунке:
Как видно теперь в критериях поиска учитывается верхний регистр символов.
Внимание! Если таблица не содержит исходное значение для поиска, тогда формула возвращает пустую ячейку. Если же таблица содержит несколько дубликатов исходного значения, тогда формула возвращает последний дубликат. Это противоположный результат функции ВПР, которая при наличии дубликатов возвращает первый из них.
Принцип действия формулы поиска с учетом регистра
Для поиска значения формула использует функцию =СОВПАД(), которая сравнивает два текста. При этому учитывает верхний регистр символов и возвращает логическое значение ИСТИНА, если тексты значений совпали. Иначе будет возвращено логическое значение ЛОЖЬ. Так как мы используем эту функцию в массиве формул, сравнение значения D1 происходит с каждым значением всех ячеек таблицы в диапазоне A1:A10.
Задача функции =ЕСЛИ() – возвращать постой текст, в случаи когда логическое выражение ИЛИ(СОВПАД(A1:A10;D1)) возвращает значение ЛОЖЬ. Пустой текст формула вернет если функция СОВПАД не найдет ни одного совпадения при сравнении с исходным текстом. Если вместо этого значение будет найдено, то в фрагменте формулы: СОВПАД(A1:A10;D1)*СТРОКА(A1:B10) будет выполнен повторный поиск и в результате в память будет возвращен номер строки, которая содержит найденное значение. Здесь используется тот факт, что во врем выполнения арифметических действий логические значения ИСТИНА и ЛОЖЬ заменяются на числа 1 и 0 – соответственно. Поэтому в случаи, когда в процессе поиска текст найден, будет получено значение соответствующие номеру строки (иначе будет равно 0). Из всех полученных номеров строк функция =МАКС() выбирает наибольший и передает его в качестве аргумента для функции =ИНДЕКС(). Эта функция уже возвращает окончательный результат отображения значения ячейки из столбца B соответственной номеру выбранной строки.
Изменить регистр текста в Word 2010
В этой главе мы обсудим, как изменить текстовые регистры в Word 2010. Вы также можете набрать заглавные буквы, нажимая и удерживая клавишу SHIFT во время ввода. Вы также можете нажать CAPS LOCK, чтобы каждая введенная вами буква была заглавной, а затем снова нажмите CAPS LOCK, чтобы отключить заглавные буквы.
Изменить текст на предложение
Случай предложения — это случай, когда первый символ каждого предложения пишется с большой буквы. Очень просто изменить выделенную часть текста в регистр предложений, выполнив два простых шага:
Шаг 1 — Выберите часть текста, которая должна быть помещена в регистр предложений. Вы можете использовать любой из методов выделения текста, чтобы выделить часть текста.
Шаг 2 — Нажмите кнопку « Изменить регистр» , а затем выберите опцию «Вариант предложения», чтобы использовать заглавные буквы в каждом первом предложении.
Изменить текст в нижний регистр
Изменение текста в нижний регистр, где каждое слово предложения в нижнем регистре. Преобразовать выделенную часть текста в нижний регистр очень просто, выполнив два простых шага:
Шаг 1 — Выберите часть текста, которая должна быть в нижнем регистре. Вы можете использовать любой из методов выделения текста, чтобы выделить часть текста.
Шаг 2 — Нажмите кнопку « Изменить регистр» , а затем выберите параметр « Строчные буквы», чтобы отобразить все выбранные слова в нижнем регистре.
Изменить текст в верхний регистр
Это где каждое слово предложения в верхнем регистре. Преобразовать выделенный текст в верхний регистр очень просто, выполнив два простых шага:
Шаг 1 — Выберите часть текста, которую вы хотите изменить на жирный шрифт. Вы можете использовать любой метод выделения текста, чтобы выделить часть текста.
Шаг 2 — Нажмите кнопку « Изменить регистр» , а затем выберите опцию « UPPERCASE», чтобы отобразить все выбранные слова заглавными буквами. Все символы каждого выбранного слова будут написаны заглавными буквами.
Прописать текст
Случай с заглавной буквы — это случай, когда каждый первый символ каждого выбранного слова указан заглавной. Это очень просто, чтобы преобразовать выделенный текст в заглавные, выполнив два простых шага:
Шаг 1 — Выберите часть текста, которая должна быть написана заглавными буквами. Вы можете использовать любой метод выделения текста, чтобы выделить часть текста.
Шаг 2 — Нажмите кнопку « Изменить регистр» , а затем выберите опцию « Прописать каждое слово», чтобы поставить начальное заглавие на каждое выбранное слово.
Переключить текст
Операция Toggle изменит регистр каждого символа в обратном порядке. Символ с большой буквы станет символом в нижнем регистре, а символ в нижнем регистре станет символом в верхнем регистре. Переключить регистр текста очень просто, выполнив два простых шага:
Шаг 1 — Выберите часть текста, которую вы хотите изменить на жирный шрифт. Вы можете использовать любой метод выделения текста, чтобы выделить часть текста.
Шаг 2 — Нажмите кнопку « Изменить регистр» , а затем выберите опцию « tOGGLE CASE», чтобы изменить все слова в нижнем регистре на слова в верхнем регистре; слова в верхнем регистре изменяются на слова в нижнем регистре.
Важен ли регистр?
Что имеется ввиду под сортировкой по алфавиту? В методе isGreaterThan используется метод String compareTo. Почитал - поковырял его дебагером - судя по всему логика его такова, что символ в верхнем регистре для него меньше аналогичного в нижнем регистре. Соответственно, отсортированный массив будет иметь вид : строки с большой буквы в алфавитном порядке -> строки с маленькой буквы в алфавитном порядке. Как по мне - это немного не в алфавитном порядке. То-есть нужно сравнивать не учитывая регистр. Из того что пока-что надумал - двумерный массив, где для каждой строки будет свой массив с длиной равной длине строки, булевый, например. По каждой строке пройтись посимвольно и по индексам расставить в массиве true или false в зависимости от регистра. Таким образом сохраниться изначальное состояние массива строк. Потом все перегнать в нижний регистр - отсортировать. После вернуть большие буквы куда нужно. Но это выглядит как-то громоздко. Может есть какой-то способ полегче? В какую сторону стоит смотреть?public class Solution { public static void main(String[] args) throws Exception { BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); String[] array = new String[20]; for (int i = 0; i < array.length; i++) { array[i] = reader.readLine(); } sort(array); for (String x : array) { System.out.println(x); } } public static void sort(String[] array) { for(int i=0; i<array.length; i++) { for(int j=i; j<array.length; j++) { if(isGreaterThan(array[i],array[j])) { String tmp = array[i]; array[i] = array[j]; array[j] = tmp; } } } } public static boolean isGreaterThan(String a, String b) { return a.compareTo(b) > 0; } }Изменить заглавные буквы текста
Вы можете изменить регистр выделенного текста в документе, нажав одну кнопку на вкладке Главная . Это кнопка Change Case .
Изменить регистр букв
Чтобы изменить регистр выделенного текста в документе, выполните следующие действия:
-
Выберите текст, для которого вы хотите изменить регистр.
-
Перейдите на страницы > и измените .
-
Выполните одно из следующих действий:
-
Чтобы сделать букву в начале предложения заглавной, а остальные буквы сделать строчными, нажмите Как в предложении .
-
Чтобы сделать все буквы строчными, нажмите нижний регистр .
-
Чтобы сделать все буквы прописными, нажмите ЗАГЛАВНЫЕ БУКВЫ .
-
Чтобы каждое слово было прописным, а остальные буквы — строчными, нажмите Like Custom Names .
-
Для переключения между двумя представлениями (например, представлением «Как имена собственные» и его противоположностью, представлением «КАК ПОЛЬЗОВАТЕЛЬСКИЕ ИМЕНА» ), нажмите ЗАМЕНИТЬ НА МАЛЕНЬКИЙ/ВЕРХНИЙ .
Консультация:
-
Чтобы применить параметр Малые прописные к тексту, выберите текст, а затем на вкладке Главная в группе Шрифт щелкните стрелку в правом нижнем углу.В диалоговом окне Font в разделе Effects установите флажок Small Caps .
-
Чтобы отменить изменение буквы, нажмите CTRL + Z.
-
Чтобы использовать сочетание клавиш для замены строчных, прописных и прописных букв на отдельные слова, выделите текст и нажимайте SHIFT + F3, пока не будут применены все буквы.
-
См. также
Вставка вставки
Выберите параметры автозамены с учетом регистра
Изменить регистр букв
Чтобы изменить регистр выделенного текста в документе, выполните следующие действия:
-
Выберите текст, для которого вы хотите изменить регистр.
-
Перейдите на страницы > и измените .
-
Выполните одно из следующих действий:
-
Чтобы сделать букву в начале предложения заглавной, а остальные буквы сделать строчными, нажмите Как в предложении .
-
Чтобы сделать все буквы строчными, нажмите нижний регистр .
-
Чтобы сделать все буквы прописными, нажмите ЗАГЛАВНЫЕ БУКВЫ .
-
Чтобы каждое слово было прописным, а остальные буквы — строчными, нажмите Like Custom Names .
-
Для переключения между двумя представлениями (например, представлением «Как имена собственные» и его противоположностью, представлением «КАК ПОЛЬЗОВАТЕЛЬСКИЕ ИМЕНА» ), нажмите ЗАМЕНИТЬ НА МАЛЕНЬКИЙ/ВЕРХНИЙ .
Консультация:
-
Чтобы применить к тексту заглавные буквы, выделите текст, затем выберите шрифт , в меню Формат и в диалоговом окне «Шрифт» в разделе «Эффекты» выберите поле «Капли».
Клавиша быстрого доступа с заглавными буквами: ⌘ + SHIFT + K
-
Чтобы отменить изменение буквы, нажмите клавиши ⌘ + Z.
-
Чтобы использовать сочетание клавиш для замены строчных, прописных и прописных букв на отдельные слова, выделите текст, а затем нажимайте клавиши Fn + SHIFT + F3, пока не будет применен нужный стиль.
-
См. также
Вставка вставки
Выберите параметры автозамены с учетом регистра
PowerPoint в Интернете поддерживает изменение букв.См. процедуру ниже.
Веб-приложение Word не поддерживает изменение регистра. Откройте документ в настольном приложении и измените регистр текста здесь. Или вы можете вручную изменить регистр текста в Word для Интернета.
-
Выберите текст, который хотите изменить.
-
Перейти к инструменты> Дополнительные параметры шрифты> Изменить регистр .

-
Выберите нужный размер букв.
| Номер | Имя (субъект) | Описание | Представление в браузере |
| ' | " | Quot (прямые кавычки) | " |
| & # 38; | и ампер; | Амперсанд (знак и) | и |
| & # 60; | < | Менее | < |
| ' | > | Больше | > |
| & # 160; | & NBSP; | Неразрывный пробел | |
| & # 161; | и т.д. | Перевернутый восклицательный знак | ¡ |
| & # 162; | & цент; | Знак цента (цент) | ¢ |
| & # 163; | фунт; | Знак фунта стерлингов (фунт стерлингов) | |
| & # 164; | & текущий; | Общий знак валюты | ¤ |
| & # 165; | иен; | Знак иены (иена) | ¥ |
| & # 166; | & брвбар; | Сломанный вертикальный стержень | ¦ |
| & # 167; | и раздел; | Знак раздела | § |
| & # 168; | & умл; | Умляут/диерисис (умляут или диэреза) | ¨ |
| & # 169; | & копия; | Авторское право (знак авторского права) | © |
| & # 170; | & ordf; | Женский порядковый номер | ª |
| & # 171; | « | Котировка левого угла, кайра слева | « |
| & # 172; | & нет; | Не подписывать | ¬ |
| & # 173; | & застенчивый; | Мягкий дефис (дополнительный аксессуар) | |
| & # 174; | и рег. | Зарегистрированная торговая марка | ® |
| & # 175; | & макрос; | Акцент Macron верхняя панель) | ¯ |
| & # 176; | & град; | Знак градуса | ° |
| ' | & plusmn; | Плюс или минус (плюс-минус) | ± |
| & # 178; | и выше2; | Верхний индекс два (2 вверх) | ² |
| & # 179; | и выше3; | Верхний индекс три (3 вверх) | |
| & # 180; | & острый; | Острый акцент | ´ |
| & # 181; | & микро; | Микрознак (греческая буква м и ) | мкм |
| & # 182; | и пункт; | Знак абзаца | ¶ |
| & # 183; | & средняя точка; | Средняя точка | |
| & # 184; | и далее; | Седилья (седилья) | ¸ |
| & # 185; | и выше1; | Верхний индекс один (1 вверх) | |
| & # 186; | & заказ; | Порядковый номер мужского рода | º |
| & # 187; | » | Цитата под прямым углом, кайра справа | » |
| & # 188; | & frac14; | Дробь - четверть | = |
| & # 189; | & frac12; | Дробь - половина | ½ |
| & # 190; | & frac34; | Дробь - три четверти | ¾ |
| & # 191; | & поиск; | Перевернутый вопросительный знак | |
| & # 192; | & Аграв; | Заглавная А, серьезный ударение (из-за А со слабым ударением) | А |
| & # 193; | & острый; | Заглавная А с острым ударением (из-за А с сильным ударением) | Á |
| & # 194; | & Цирк; | Заглавная А, циркумфлексное ударение (из-за А с циркумфлексом) | Â |
| & # 195; | и Атильда; | Заглавная буква А, тильда (должная буква А с тильдой) | Ã |
| & # 196; | и Аумл; | Заглавная буква А, умлаут (причитается А от диреса) | Ä |
| & # 197; | и Аринг; | Заглавная буква А, кольцо (соединенная А с кку) | Å |
| & # 198; | и AElig; | Капитальный дифтонг AE - лигатура (Ligatura AE) | и AElig |
| & # 199; | и Ccedil; | Заглавная буква C, седилья (доля C cedilla) | Ç |
| & # 200; | & Выгравировать; | Заглавная Е, серьезное ударение (из-за Е со слабым ударением) | È |
| & # 201; | & Острый; | Заглавная Е, острое ударение (из-за Е с сильным ударением) | Э |
| & # 202; | & Ecirc; | Заглавная буква E, ударение с циркумфлексом (должное E с циркумфлексом) | |
| & # 203; | и Емл; | Заглавная Е, умляут - диерисис (должное Е с умлаутом) | Ë |
| & # 204; | & Игра; | Заглавная I с серьезным ударением (из-за I со слабым ударением) | М |
| & # 205; | и острый; | Заглавная I с острым ударением (из-за I с сильным ударением) | Í |
| ' | и круг; | Заглавная I, циркумфлексное ударение (из-за I с циркумфлексом) | О |
| ' | & Юмл; | Заглавная I, умляут - диерисис (из-за I с умлаутом) | О |
| ' | и эфир; | Capital Eth, исландский (исландский eth ) | Р |
| & # 209; | & Нтильда; | Заглавная буква N, тильда (должная буква N с тильдой) | |
| & # 210; | и Ограв; | Заглавная О, серьезное ударение (из-за О со слабым ударением) | Т |
| ' | и Острый | Заглавная О, острый ударение (из-за О с сильным ударением) | |
| & # 212; | & Ocirc; | Заглавная буква O, ударение с циркумфлексом (из-за буквы O с циркумфлексом) | Ô |
| & # 213; | и Отильда; | Заглавная O, тильда (из-за O от тильды) | х |
| & # 214; | & Ouml; | Заглавная О, умлаут - диеризис (вследствие О с умляутом) | Ö |
| & # 215; | & раз; | Знак умножения | × |
| & # 216; | и Ослэш; | Заглавная О, косая черта (через О с крестом) | Ø |
| & # 217; | и Уграв | Заглавная буква U, серьезный ударение (из-за буквы U со слабым ударением) | Ù |
| & # 218; | & Острая; | Заглавная U, акут (из-за U с сильным ударением) | Ú |
| & # 219; | и Ucirc; | Заглавная буква U, ударение огибающей (из-за буквы U с крышкой) | Û |
| & # 220; | Заглавная буква U, умлаут - диерисис (из-за буквы U с умлаутом) | О | |
| & # 221; | и Якуте; | Заглавная Y с острым ударением (из-за Y с сильным ударением) | Ý |
| & # 222; | & ШИП; | Capital Thorn, исландский (из-за исландского шипа ) | Þ |
| & # 223; | & шлиг; | Маленькая диез s, немецкая лигатура sz (немецкая лигатура sharfes с ) | ß |
| & # 224; | & agrave; | Маленькая а, серьезное ударение | отдо |
| & # 225; | & острый; | Маленькая а с острым ударением (маэ а с сильным ударением) | а |
| & # 226; | & круг; | Маленькая буква а, огибающая акцент | - |
| & # 227; | & далее; | Маленькая а, тильда | ã |
| & # 228; | и аумл | Маленькая а, умлаут - диерисис (маленькая а с умляутом) | и |
| & # 229; | & кольцо; | Малый, кольцо | - |
| & # 230; | & элиг; | Малый дифтонг ae - лигатура | и элиг |
| & # 231; | & ccedil; | Малый c, cedilla (mae c cedill) | и |
| & # 232; | & выгравировать; | Маленькая буква е, серьезное ударение | и |
| & # 233; | & острый; | Маленькая е, острое ударение (маэ е с сильным ударением) | и |
| & # 234; | и контур; | Маленькая буква e, ударение по огибающей | |
| & # 235; | & еумл; | Маленькая е, умлаут - диерисис (маленькая е с умляутом) | - |
| & # 236; | & игра; | Маленькое i, серьезное ударение (малое и слабое ударение) | х |
| & # 237; | & iacute; | Малый и острый акцент | и |
| & # 238; | и круг; | Маленький i, ударение по циркумфлексу (маленькое и с циркумфлексом) | î |
| & # 239; | & мл; | Маленькое i, умляут - диерисис (маленький и с умляутом) | ï |
| & # 240; | и др.; | Маленький eth, исландский (исландский mae eth ) | ð |
| & # 241; | & нтильда; | Маленькая н, тильда (мэн н тильды) | |
| & # 242; | & ograve; | Маленькая буква o, гравировка | х |
| & # 243; | & острый; | Маленькое о, острое ударение (маэ о с сильным ударением) | |
| & # 244; | & оцир; | Маленькое o, ударение по огибающей | х |
| & # 245; | & отильда; | Маленький о, тильда | х |
| & # 246; | & oумл; | Маленькая о, умлаут - диерисис (маленькая о с умлаутом) | или |
| & # 247; | & разделить; | Знак подразделения | ÷ |
| & # 248; | & косая черта; | Маленький о, косая черта | ø |
| & # 249; | & Уграв; | Маленькая буква u, серьезное ударение | х |
| ' | & uacute; | Маленькое у, острое ударение (мае у с сильным ударением) | ú |
| & # 251; | & ucirc; | Маленькая буква u, ударение по огибающей | х |
| & # 252; | & уумл; | Маленькая у, умлаут - диерисис (маленькая у с умляутом) | ü |
| & # 253; | & якут; | Маленькое у, острое ударение (может быть у со слабым ударением) | х |
| & # 254; | & шип; | Маленький шип, исландский (исландский mae thorn ) | + |
| & # 255; | & юмл; | Маленькая буква y, умлаут - диерисис (маленькая буква y с умлаутом) | ÿ |
| & # 338; | & OElig; | Latin Capital OE - лигатура | – |
| & # 339; | & Олиг; | Латинская малая OE - вязь | - |
| & # 352; | и Скарон; | Заглавная буква S с кароном | © |
| & # 353; | & скарон; | Малый s с кароном | š |
| & # 376; | и Юмл; | Заглавная буква Y с диеризом (должное Y с умляутом) | Ÿ |
| & # 710; | & circ; | Акцент Circumflex | ˆ |
| & # 732; | & тильда; | Маленькая тильда | ~ |
| & # 8211; | – | Короткое тире (пауза) | - |
| & # 8212; | & mdash; | Короткое тире (пауза - тире) | - |
| & # 8216; | & Lsquo; | Левая одинарная кавычка | ' |
| & # 8217; | & Rsquo; | Правая одинарная кавычка | ' |
| & # 8218; | & sbquo; | Одинарная нижняя 9 кавычка (запятая) | ‚ |
| & # 8220; | & ldquo; | Левая двойная кавычка | " |
| & # 8221; | & Rquo; | Правая двойная кавычка (правая кавычка) | " |
| & # 8222; | & ldquo; | Двойная младшая 9 кавычка | " |
| & # 8224; | & кинжал; | Кинжал (кричащий знак) | † |
| & # 8225; | & Кинжал; | Двойной кинжал | ‡ |
| & # 8240; | & пермил; | Знак промилле (тысячи) (промилле) | ‰ |
| & # 8249; | & Lsaquo; | Одинарная кавычка, указывающая влево | ‹ |
| & # 8250; | & Rsaquo; | Одинарная правая кавычка | › |
| & # 8364; | и евро; | Знак евро (знак евро) | 90 037 € 90 040|
| & торговля; | Товарный знак (торговая марка) | ™ |
Grep и основные регулярные выражения - Лукаш Борхманн
Команда grep используется для поиска в тексте с использованием регулярных выражений, формализма, позволяющего искать определенные шаблоны. Этот формализм широко используется и узнать о нем будет полезно во многих других случаях, а проще всего понять его (и о чем речь) на примерах.
Предположим, что у нас есть файл slowoformy.txt , созданный, как описано в предыдущем разделе заметок.в регулярных выражениях это означает начало, и $ - готово, следовательно:
- пример во второй строке вернет только слова, начинающиеся с «нет» (например, неприятный , нет , немой и отвращение ),
- выражение no $ будет отфильтровывать словоформы, оканчивающиеся на «нет» (например, абсурдно , нет , наркотик ),
- В последнем примере будут найдены слова, для которых между началом и концом стоит только "нет", то есть только слово , а не .
Любой символ и выбранное количество повторов
точка ( .) в регулярных выражениях используется для обозначения любого символа. Объединив эту информацию с приведенной выше, мы можем попробовать команды для поиска слов, начинающихся с «нет» и состоящих из четырех (например, , , , затем ), пяти ( его , nieuk ) и шесть символов ( приятный , не жирный ):
grep '^ нет.нет... $ 'slowoformy.txt
Теперь давайте введем опцию E (от до ), который в силу какой-то недостойной исторической подоплеки требуется для обработки некоторых регулярных выражений. Полезно об этом помнить, когда тщательно разработанное регулярное выражение не вернет никаких результатов... С этого момента все вызовы команды grep будет содержать параметр E, даже если это не требуется для правильного функционирования выражения.и {2} идентичны и будут находить слова, начинающиеся с "аа", например из Аарона .
В фигурных скобках мы можем указать не только точное количество повторений данного символа, но и интервал. В следующих примерах мы ищем слова от 3 до 5 символов, слова от 6 до 11 символов и слова, состоящие из 4 и более символов (второе значение намеренно не дано после запятой, а значит нет верхнего предела) .
grep -E '^.[ab] 'slowoformy.txt
Строки 1 и 2 идентичны (порядок символов в квадратных скобках не имеет значения). Строка 3 включает слова, начинающиеся с заглавных букв (по умолчанию grep, как некоторые говорят, «различает семантику верхнего и нижнего регистра», т.е. чувствителен к регистру ). Строки 3 и 4 идентичны — в последней используются опции и , которые отключают регистронезависимую (так что команда становится нечувствительной к регистру ).
Однако мы не обязаны заменять все символы, которые мы хотим разрешить, один за другим, но можно применить некоторое упрощение написания, и так:
- [A-Z] означает все заглавные буквы латинского алфавита (но не польские буквы с диакритическими знаками),
- [a-z] - это то же самое, что перечисление в этих скобках всех строчных букв латинского алфавита,
- [0-9] идентично [0123456789] и допускает любую цифру,
- [A-Za-z] означает все (заглавные и строчные) латинские буквы,
- [a-zaćęłńóśżź] — класс, включающий в себя все строчные буквы польского алфавита (что можно написать немного проще, о чем в будущем).A-Z].{4,} $ 'slowoformy.txt
Символы звезды, плюса и вопросительного знака
Звезда ( *, плюс ( +) и знак вопроса ( ?) можно рассматривать как синонимы упомянутых выше частных случаев фигурных скобок.
Первый символ означает любое количество повторений символа (т.е. .* означает то же самое, что и .{0,}), а второй - количество повторений больше одного (таким образом, оба [а-я] + и [a-z] {1,} — хотя бы одна строчная буква латинского алфавита).За знаком вопроса стоит ноль или одно повторение, следовательно [0-9] {0.1} и [0-9] ?, любая арабская цифра или нет.
.СимволР в круге - что он означает? Когда его можно использовать?
Вы, должно быть, видели торговую марку с символом R в круге по крайней мере несколько раз в своей жизни. Оно стало ассоциироваться с понятием оригинальности. Когда мы спросим обывателя о значении R, он ответит прямо – этот знак подчеркивает, что товар высочайшего качества и уж точно не подделка. Однако это не совсем так. Пришло время представить факты и мифы по этому вопросу.
Конечно, лучше всего начать с мифов.Ведь в нашем сознании они стали легендарными. Ведь вы не можете сказать мне, что когда вы видите символ R, вы не думаете, что контактируете с чем-то «лучше».
Указывает ли символ R на подлинность продукта?
Kruczek.pl не имеет буквы R в названии. Значит ли это, что мы подделка? Конечно, нет. Я также попытаюсь представить вам противоположную ситуацию. Мошенник, который производит обувь, выдавая себя за другую марку, пропускает символ R, потому что он доказывает оригинальность продукта? Конечно, нет.Р-ка не голограмма и ее очень легко подделать. Его задача не в том, чтобы отметить оригинальность. С этой точки зрения многие компании, особенно те, которые продают продукты, могут потерять много денег. Не знаю, знаете ли вы, но некоторое время назад эта проблема коснулась Timberland, чья обувь поставлялась через интернет-магазин Zalando. Люди хотели составлять фразы из-за отсутствия «штампа оригинальности» в названии. Другими словами, обувь поставлялась с логотипом Timberland вместо Timberland®.
Один клиент решил объяснить ситуацию и написал напрямую в компанию. Ниже ответ на его запрос.
Здравствуйте (...),
Благодарим за обращение в службу поддержки клиентов Timberland Online. Объяснение того, почему на кроссовках нет буквы (R), заключается в том, что, несмотря на то, что все они являются оригинальными туфлями Timberland, в зависимости от места их производства, иногда обувь не имеет знака (R).Не о чем беспокоиться, это все еще оригинальные туфли, но без (R). Если у вас есть какие-либо вопросы, свяжитесь со мной снова - я буду рад помочь.
С наилучшими пожеланиями
ПетарТаким образом, R-ka не имеет ничего общего с оригинальностью продукта.
РУКОВОДСТВО ПО АРЕНДЕ, КОНСУЛЬТАЦИИ И СОГЛАШЕНИЯ О ПРЕМИУМ
ПОСМОТРЕТЬ ПРЕДЛОЖЕНИЕ НАШЕГО МАГАЗИНА
Является ли символ R знаком авторского права?
Многие предприниматели используют этот символ для идентификации своей компании.Их намерение состоит в том, чтобы подчеркнуть свои авторские права. Это не только миф, но и деяние, наказуемое штрафом. Почему? Я уже отвечаю. R в кружке — это не что иное, как сокращение от «registered». Это означает, что этот товарный знак защищен Патентным ведомством.
Другими словами, только те, кто имеет право на охрану, полученное в PPO, EUIPO или WIPO, могут (не обязаны) использовать комбинацию «Enterprise®». Крупные и авторитетные компании, такие как Google, не нуждаются в символе R, чтобы все знали, что у них есть права на защиту своих товарных знаков.
Символ R - каков риск незаконного использования?
Пожалуй, самое время упомянуть об уголовно-правовых аспектах использования «символа оригинальности». Начать лучше всего со ст. 308 Закона о промышленной собственности (далее: ПИС), в которой указывается, что любой, кто размещает на рынке товары, отмеченные товарным знаком с идентификатором, предназначенным для создания ошибочного предположения о том, что эти товары охраняются, подлежит штрафу. Этим отличительным признаком, безусловно, является символ R. Так что предпринимателям, искажающим информацию о своем бренде, могут грозить санкции в виде штрафа.Неважно, было ли действие преднамеренным или непреднамеренным. Согласно ст. 1 Кодекса о мелких правонарушениях штраф может достигать 5000 злотых. Не стоит, тем более, что вы тоже можете быстро потерять доверие клиентов. Достаточно поднять конкуренцию, что вы обманываете потребителей, вводя их в заблуждение.
Что делать, если конкуренты незаконно используют R?
Лучше всего обратиться в полицию. Вам не нужно беспокоиться о своих личных данных, так как вы можете сделать это анонимно.Если доказательства окажутся неопровержимыми, например, символ R можно найти рядом с логотипом компании на сайте, рекламных баннерах или на вывеске, вам даже не придется представлять никаких объяснений. Однако, если вы не хотите задействовать вооруженную руку правосудия, вы всегда можете воспользоваться гражданским путем. Достаточно иска со ссылкой на положения Закона о борьбе с недобросовестной конкуренцией. В соответствии со ст. 14 того же правового акта мы называем актом недобросовестной конкуренции, в частности, распространение ложной или вводящей в заблуждение информации опредприятия с целью получения выгоды или причинения вреда.
Прочтите: Что означает буква C в кружке?
Скорее нет смысла утверждать, что "Przedsiębiorstwo®" представляет определенный уровень престижа и обычно хорошо ассоциируется у потребителей. Следовательно, использование Р-ки незаконным образом может ввести в заблуждение и принести пользу мошеннику или навредить законному владельцу, не достигшему этой выгоды.
НАША СТАТЬЯ НЕ РАЗРЕШИЛА ВСЕ ВАШИ СОМНЕНИЯ?
ПОЛУЧИТЬ ЮРИДИЧЕСКУЮ КОНСУЛЬТАЦИЮ
Символ R - зачем его использовать?
Символ - ® ассоциируется с престижем.Поэтому при регистрации знака ставьте рядом с ним символ R. Люди, имея выбор между двумя товарами, выберут тот, который им покажется более качественным. Помните, что покупатель тоже будет готов заплатить за такой товар больше. Таким образом, инвестиции в право на охрану товарных знаков могут в конечном итоге увеличить оборот вашей компании.
Второй важный и позитивный штрих — это, конечно же, собственный бренд. Вы делаете это не только локально, но и по всей стране, региону или миру.Как владелец, вы имеете право защищать свой продукт или услугу. Никто другой не может использовать ваш бренд, но если кто-то попытается, за вами стоит государственный аппарат для обеспечения соблюдения ваших прав. Это третье преимущество. Конкуренты побоятся использовать ваше имя или логотип, не говоря уже о том, чтобы поставить рядом с ним символ R.
Что вместо системы "Przedsiębiorstwo®"?
Безопаснее всего выбрать товарный знак, чтобы подчеркнуть, что вы рассматриваете свое имя или логотип как товарный знак.Обратите внимание, что обозначение «Przedsiębiorstwo™» никоим образом не указывает на то, что вы подали заявку в Патентное ведомство, поэтому вы не вводите своих клиентов в заблуждение.
Символы TM и R также могут использоваться взаимозаменяемо.
Как получить (®) на клавиатуре?
Чтобы получить (®) на клавиатуре, вы должны сделать определенную комбинацию клавиш, т.е. (левая) ALT + 0174
Вы делаете это, нажав и удерживая левую клавишу «Alt». Не отпускайте ее, пока не нажмете цифры 0-1-7-4 на цифровой клавиатуре.Как только вы это сделаете, отпустите клавишу Alt. Вы должны увидеть символ R в круге на экране. Помните, однако, что может случиться и так, что в данном шрифте (шрифте), который вы используете, не будет R-ки. В этом случае вам придется выбрать другой. Однако это очень редкое явление. Все системные шрифты Windows должны иметь такой знак.
.Маркировка грузовых вагонов - transportszynowy.pl 9000 1
Грузовые вагоныНормальный строительный Угольный вагон
Специальная строительная платформа WAGON
WAGON для сыпучих товаров
Маркировка размещена на пассажирских вагонах регулирует «международные правила на грузовых вагонах», то есть RIV ( Regolamento Internazionale Veicoli).Несоблюдение норм RIV в маркировке вагонов в случае грузовых вагонов лишает эти вагоны права движения по другим железнодорожным администрациям, поскольку такие вагоны не допускаются на маршруты иностранной железнодорожной администрации.
Среди маркировок также можно встретить знак PPW (Prawiła Polzowania Wagonami), который имеет международную аббревиатуру MC и определяет стандарты маркировки вагонов, движущихся по Восточной Европе.Маркировка на вагонах расположена с левой стороны обеих боковых стенок вагонов.Обозначение состоит из двенадцатизначного кода и буквенного обозначения.
Пример описания грузового вагона с пояснением:
Пример обозначения вагона - Польша (ПКП)Пример обозначения вагона - Венгрия (МАВ)
6 Обозначение вагона -Словакия (МАВ)
6
Примерное обозначение цистерн - Франция (SNCF)
Значение цифр, входящих в маркировку грузовых вагонов
12-значный идентификатор EVN вагона также является его инвентарным номером .Он состоит из пяти групп цифр:- первая группа (2 цифры)
- унифицированный код взаимозаменяемости вагонов в международном сообщении.Указывает, подходит ли вагон для международных перевозок и, если
система
, то можно ли ходить по колеям разной ширины (нормальной/широкой).
01 - нормальный путь, международное движение в системе RIV
01 - нормальный/широкий путь, международное движение в системе RIV
20 - нормальный путь, только внутренняя связь
21 - нормальный путь, международное сообщение движение в системе РИВ и МК
22 - нормальный/широкий путь, международное сообщение в системе РИВ и МК
30 - вагон для нужд внутренних железных дорог
31 - нормальный путь, г/п 40т, международное сообщение в РИВ и МС- вторая группа (2 цифры)
обозначение страны собственника или железной дороги, вводившей вагон в эксплуатацию:
10 - Финляндия
20 - Россия
21 - Беларусь 3 20 5 - Украина
23 - Молдова
24 - Литва
25 - Латвия
26 - Эстония IA
27 - Казахстан
28 - Грузия
- Грузия
- - Узбекистан 29 - Узбекистан
30 - Северная Корея
31 - Mongolia
32 - Вьетнам
33 - KUBA 40
41 - Albania
42 - Япония
43 - Венгрия - Raab-Ebenfurt железная железная дорога (GYSEV)
44 - Венгрия - Будапештская транспортная компания (BHEV)
51 -
Польша 52 - Болгария
53 - Румыния
54 - Чешская Республика
55 - Венгрия
- Венгрия
56 - Словакия
56 - Азербайджан
57 - Азербайджан
58 - Армения
59 - Кыргызстан
59 - Кыргызстан - Ирландия
61 - Южная Корея
900 04 62 - Швейцария - Частные швейцарские железные дороги (SP)
63 - Железная дорога Берн-Лочберг-Симполь (BLS)
64 - Железная дорога Норд-Милано-Эшерчицио (FNME)
65 - Югославия и Македония 66 - Tajikistan
68 - Ahaus-Alstate Railways (AAE)
69 - Eurotunnel Company
70 - Великобритания - Британская транспортная ассоциация (RFD)
71 - Испания Испания - Сербия и montenegro
73 - Греция
74 - Швеция
7000 - Турция
76 - Норвегия
78 - Хорватия
79 - Словения
80 - Германия - Австрия
82 - Люксембург
83 - Италия
84 - Нидерланды
85 - Швейцария
86 - Дания
- Дания
87 - Франция
8000 - Бельгия
89 - Босния и Герцеговина
90 - Египет
91 - Тунис 92 0 - Тунис 920003
93 - Morocco
94 - Португалия
- Португалия
95 - Израиль
9000 - Иран
9000 - Сирия
- Ливан
99 - Iraq- третья группа):
обозначают серию вагона (первый - тип, а три последовательных технических признака
вагона), последняя цифра этой группы связана с прописной буквой, а
остальные цифры этой группы связаны со строчными буквами.- четвертая группа (3 цифры):
- порядковый номер вагона данной производственной серии.- пятая группа (1 цифра):
это номер самоконтроля и рассчитывается так же как и в легковых автомобилях.Значение букв, входящих в буквенный ряд грузовых вагонов
Буквенный ряд содержит информацию о технических и эксплуатационных характеристиках вагонов. Заглавная буква означает тип автомобиля , а строчные буквы являются дополнительными буквами, информирующими о технических и эксплуатационных данных.
- Заглавная буква
Указывает тип вагона и ассоциируется с пятой цифрой номера вагона:0 - Т - вагон с открытой крышей
5 -
1 Крытый вагон 2 - H - Крытый вагон специальной конструкции
3 - K - Вагон-платформа нормальной конструкции на независимых осях
3 - O - Вагон-смеситель с платформой нормальной конструкции, 2 или 3 оси
3 - R - вагон-платформа стандартной конструкции на тележках
4 - L - вагон-платформа специальной конструкции на независимых осях
4 - 00004 - 9 вагонов на платформе S 9000 5 - E - вагон для угля обычной конструкции
6 - F - вес n Специальный строительный угольный вагон
7 - Z - танковый вагон
8 - I - холодильник Wagon
9 - U - Специальный или сервисный универсал- строчные буквы
с прописной буквой .
буквы с значение международное (действительно
во всех правлениях железных дорог МСЖД) и буквы со значением
внутреннее (используются индивидуально железнодорожными властями).
Строчные буквы международного значения проставляются на вагонах
в алфавитном порядке
С другой стороны, строчные буквы внутреннего значения помещаются
после букв международного значения, разделенных дефисом.
Буквы международного значения варьируются от и до q .Ниже приведены буквы международного значения, что
относятся к грузовым вагонам всех типов :ф - приспособлен для сообщения с Великобританией
ff - приспособлен для сообщения с Великобританией через тоннель
ff f - подходит для сообщения с Великобританией только через паром
q - электрический нагревательный кабель для всех типов напряжения
qq - электрический нагревательный кабель и устройства для всех типов напряжения
s - подходит для движения со скоростью 100 км/ч
сс - приспособлены для движения со скоростью 120 км/чБуквы международного значения не упомянутые выше относятся
относятся к конкретным типам грузовых вагонов:- вагоны серии Е 9 0003 Вагоны для угля нормальной конструкции с плоским полом, приспособленные
для разгрузки на поворотные самосвалы - спереди или сбоку.
2-осный: более 7,70 м, 25–30 т
4-осный: более 12 м, 50–60 т
6-осный: более 12 м, 60–75 тa — 4 оси c - с разгрузочными люками в полу
k - 2 оси до 20т, 4 оси до 40т, 6 осей до 50т
кк - 2 оси 20 - 25т, 4 оси 40 - 50т, 6 оси 50 - 60т
л - не приспособлены для разгрузки на самосвалы с поворотным бортом
м - 2 оси до 7,70м, 4 оси до 12м
n - 2 оси свыше 30т, 4 оси свыше 60т, 6 осей более 75т
o - не приспособлены для разгрузки на самосвалы- Вагоны серии F
Вагоны для угля специальной конструкции
2-х осный: 25 - 30т
3-х осный: 25 - 403т 4-90 ось: 50–60 т
6-осная: 60–75 та - 4 оси
аа - 6 осей
б - одноосный вагон большой грузоподъемности
с - с одинарной или двойной дозированной выгрузкой с высокими желобами
куб.см - с одинарной или двойной дозированной выгрузкой
k - 2 или 3 оси до 20 т, 4 оси до 40 т, 6 осей до 50 т
kk - 2 или 3 оси 20 - 25 т, 4 оси 40 - 50 т, 6 осей 50 - 60 т3
3
3 л - с полной разгрузкой, одновременно двухсторонней с высокими желобами
ll - с полной разгрузкой, одновременно двухсторонней с низкими желобами
n - 2 оси свыше 30т, 3 оси свыше 40т, 4 оси свыше 60т, 6-осные свыше 75 т
o - с полной разгрузкой, только между рельсами, с высокими желобами
oo - с полной разгрузкой, только между рельсами, с низкими желобами
р - с дозированной выгрузкой, только между рельсами, с высокими желобами
рр - с дозированной выгрузкой, только между рельсами, с низкими желобамиВыгрузка в вагонах серии Ф автоматическая и самотечная.Эти угольные вагоны
не имеют ровного пола и не приспособлены для разгрузки
на опрокидыватели с фронтальным и боковым барабанами.
Желоба бывают двух типов:
- расположенные над осью пути - разгрузочные между рельсами,
- расположенные по обеим сторонам пути - разгрузочные вне рельсов.
Выгрузка на наружную сторону рельсов может быть одновременно двусторонней
(выгружается одновременно с обеих сторон) или неодновременно
двухсторонней (выгружается одновременно с обеих сторон)- серия Г вагоны
Крытые вагоны нормальной конструкции минимум 8 вент.
2-осный: 9–12 м, 25–30 т
4-осный: 15–18 м, 50–60 т
6-осный: 15–18 м, 60–75 тa - 4 оси a 60 900 ось
б - пассажирские вагоны: 2 оси свыше 12м и свыше 70 м3, 4 оси свыше 18м
г - для зернового транспорта
ч - для свежих овощей
к - 2 оси, до 4 20т оси до 40 т, 6 осей до 50
kk - 2 оси 20 - 25 т, 4 оси от 40 до 50 т, 6 осей 50 - 60 т
l - менее восьми вентиляционных отверстий
м 90x05 - 2 оси до 9 м, 4 и более осей до 15 м
n - 2 оси до 30 т, 4 оси до 60 т, 6 осей до 75 т
o - 2 оси до 12 м и более 70 м3Только грузовые для перевозки свежих овощей используются вагоны
, которые имеют дополнительные вентиляционные отверстия на уровне пола.- Вагоны серии Н
Крытые вагоны специальной конструкции.
2-осный: 9–12 м, 25–28 т
4-осный: 15–18 м, 50–60 т 70 м3, 4 и более осей 18 - 22
bb - 2 оси до 14м, 4 и более осей до 22м
c - с дверью в торцах
cc - с дверью в торцах и внутреннее устройство
для автомобильного транспорта
d - с бортами в полу
e - с двумя этажами
ee - с тремя и более этажами
g - для зернового транспорта
h овощи
и - с открывающимися боковыми стенками
к - 2 оси до 20т, 4 оси до 40т, 6 осей до 50т
кк - 2 оси 20 - 25т, 4 оси 40 - 50т, 6 оси 50 - 60т
л - с перемещениями с перегородками
ll - с запираемыми подвижными перегородками
m - 2 оси до 9 м, 4 и более осей до 15 м
n - 2 оси свыше 28 т
o o и свыше 70 м3- Вагоны I серии
Вагоны-рефрижераторы (температурно-изотермические) со средней изоляцией
(класса IN), с роторными вентиляторами, с напольной решеткой и
льдогенераторами вместимостью 3,5 м3.a - 4 оси
b - 2 оси большая площадь 22 - 27 м3
bb - 2 оси очень большая площадь более 27 м3
е - с электровентиляцией
г - вагон с агрегатным охлаждением
гг - рефрижератор с охлаждением на СУГ
ч - с усиленной изоляцией (классы IR)
и - с рефрижераторным охлаждением единица отдельный технический вагон
ii - технический вагон
к - 2 оси свыше 15 т, 4 оси свыше 30 т
л - изотермический вагон без цистерн для льда
м - 2 оси м2, до 4 19 оси до 39 м2
n - 2 оси до 25 т, 4 оси до 40 т
o - с емкостями для льда вместимостью менее 3,5 м3
р - без решетки пола- Вагоны серии К
Вагоны платформы двухосные нормальной конструкции с откидными стенками
и короткими стойками.
12 м, 25 - 30 тb - с длинными стойками
г - подходит для перевозки контейнеров
и - с подвижной крышкой и фиксированными торцевыми стенками
к - 5 тонн до - 20 кк - 20T 25T
- 20T 25T
L - без стойки
м - 9 - 12 м
мм - до 9 м
мм N - более 30Т
O - с фиксированными стенками
P - без бортов
пп --0004 пп со съемными бортами- Вагоны серии Л
Вагоны-платформы специальной конструкции на одинарных осях.
12м, 25 - 30тб - подходит для перевозки средних контейнеров
с - с поворотным столом
г - без пола, для автомобильного транспорта
д - с двойным -палубный пол, для автомобильного транспорта
г - подходит для перевозки контейнеров (без носителя)
hh - для перевозки листов в бухтах, загружаемых горизонтально
hh - для перевозки листов в бухтах, в вертикальном положении
и - с подвижной крышкой и неподвижными торцевыми пластинами
j - с амортизатором
k - до 20 т
kk - 20 - 25 л - без
стойки
м - 2 оси, 9 - 12 м, 3 оси (или более) 18 - 22м
мм - до 9м
n - свыше 30 т
р - без бортов- Вагоны серии О
Вагоны-платформы специальной конструкции на одинарной оси.а - 3 оси
к - группа нагрузка <20т
кк - 20т <гр. нагрузка <25т
л - без стоек
м - 9м <погрузочная длина <12м
мм - погрузочная длина <9м
n - 2 оси: тыс. нагрузка > 30 т / 3 оси: гр. нагрузка > 40тБуквы внутреннего значения - используемые PKP SA:
t - вагон типа G, H, E приспособленный для военного транспорта
u - крытый вагон: служебный (S), частный (P), с ограниченной технической эффективностью
w - вагон для угля нормальной конструкции: служебный, коммерческий, частный
v - вагон для угля специальной конструкции: служебный, частный
z - вагон-платформа: служебный, частный
y - специальный вагон : бизнес, частный
x - вагон с новой нумерацией, действующей с 1980 г.Маркировка вагонов серии R, S, Z, T, U и многовагонных вагонов F, H, I, U, Z, L, S - материал ПОД ГОТОВ.
Размеры , указанные в приведенных выше спецификациях, относятся к погрузочной длине вагонов (т.е. не всего вагона).
Масса , указанная в приведенных выше спецификациях, информирует о группе загрузки вагона (т.е. не о массе всего вагона)Прочие надписи и знаки, размещаемые на грузовых вагонах, и таблицы пределов загрузки вагонов представлены ниже:
Прочие надписи и знаки на грузовых вагонах
Таблица грузоподъемности вагоновНа борту вагона за специальной решеткой находится накладная , т.е. карточка с информацией о транспорте (отправитель, адресат, спецификация груза и т.д.).
.Какой пароль доступа? Как создавать безопасные и надежные пароли? »Home.pl
Во множестве повседневных задач мы все чаще создаем случайные и слабые пароли, которые, к сожалению, становятся легкой мишенью для киберпреступников. В этой статье объясняется, что такое пароль и как создавать безопасные и надежные пароли.
СОДЕРЖАНИЕ
Какой пароль?
Пароль представляет собой строку символов, которая обычно используется при входе на различные типы ресурсов, например.в операционные системы, базы данных, порталы, электронная почта и т. д.Пароли могут состоять из букв, цифр, а также специальных символов или символов. Многие системы также чувствительны к регистру или требуют внешнего ключа для расшифровки данных.
ВАЖНО! Пароль должен оставаться известен только тому, кто его устанавливает. Им нельзя делиться или сохранять в местах, доступных для других пользователей.
Зачем использовать надежные пароли?
Данные вашей учетной записи электронной почты, личные данные и ресурсы, которые вы защищаете, будут в безопасности только при использовании надежных паролей.Чем сложнее пароль, тем больше времени потребуется для его расшифровки третьей стороной или машиной.
Никогда не думайте, что установленный пароль невозможно взломать. В двадцать первом веке компьютеры с доступным программным обеспечением позволяют делать бесконечное количество попыток входа в систему с различными комбинациями паролей за короткий промежуток времени.
В качестве дополнительной меры безопасности пароль регулярно меняется через определенные промежутки времени.Благодаря этому, даже если мы не знаем, что пароль был украден или прочитан другими людьми, мы эффективно защитим наши данные от кражи.
Как создавать безопасные пароли?
Используйте приведенные ниже советы, чтобы повысить «надежность» вашего пароля:
- пароль должен быть не менее 8 символов,
- Пароль не может содержать имя вашей службы,
- пароль не может содержать польских символов,
- Пароль должен содержать как прописные, так и строчные буквы,
- пароль должен содержать цифры,
- также используют специальные символы (например,&, @,!).
Хорошая практика:
- комбинация из нескольких слов, может быть разделена специальными символами,
- комбинация прописных и строчных букв,
- замена обычных букв специальными символами, например, a-@, i-1, o = 0, s =% и т. д.,
- использование специальных символов, чередующихся с буквами и цифрами,
- слов, намеренно написанных с ошибками, но все же легко запоминающихся или легко ассоциируемых -
-
с использованием сочетаний, не имеющих смысла, но ассоциирующихся и запоминающихся благодаря характерному обертону, можно дополнить дополнительными знаками, напримерджеб (кум) кум, хулалула => 10%.
В Интернете доступно множество инструментов, позволяющих генерировать пароли, отвечающие вышеуказанным требованиям. Существуют также инструменты, позволяющие проверить надежность уже имеющегося у вас пароля.
ВАЖНО! Никогда не вводите свой пароль, если вы не знакомы с сайтом или сомневаетесь в его внешнем виде или преимуществах.
Для проверки надежности вашего пароля мы рекомендуем инструмент от «Лаборатории Касперского»: Secure Password Check Введенные пароли не запоминаются на сайте, они проверяются в режиме реального времени.Что нельзя использовать при создании паролей?
Очень большое количество паролей, используемых в Интернете пользователями, представляет собой базовую строку символов, которая часто напрямую связана с информацией о ее владельце. Они содержат такие данные, как даты рождения, номера социального страхования, имена или популярные комбинации последовательных клавиш клавиатуры. Эти типы паролей легко запомнить, но также легко взломать. Мы предлагаем вам избегать паролей, содержащих:
- фраза для создания логина,
- информация о пользователе, например.имена, фамилии, важные даты,
- указывает на окружение пользователя, любимые предметы, названия животных, места,
- , состоящий только из букв или цифр, например, abcdefgh, 123654 и т. д.,
- имена, фамилии или имена известных персонажей или общеупотребительные слова, например, kasia1, batman2 и т. д.,
- последовательности, прочитанные с клавиатуры, например, 123456, qwerty и т. д.,
- короче 6 символов.
Как мне следить за своим паролем?
Хороший пароль защищает ваши данные, но безопасность вашего пароля в основном зависит от вас.Обратите особое внимание на рабочую среду и безопасность вашего компьютера.
-
Избегайте записи паролей на карты, блокноты или другие источники, которые могут попасть в чужие руки или являются общедоступными,
-
не сообщать пароли третьим лицам,
-
на веб-сайтах, таких как банки, платежные системы, рабочие инструменты и базы данных, используйте надежные пароли, не забывая обновлять их,
-
на несущественных веб-сайтах, например.случайные форумы, разовые регистрации и т.п. используйте пароли отличные от указанного выше пункта,
-
один сайт, программа, система один пароль, в случае его взлома остальные данные в сохранности,
-
внедрить небольшую политику безопасности дома или в компании, которая будет, например, предполагать регулярную смену пароля, в соответствии с указанными ранее требованиями,
-
использовать антивирусные программы, которые обеспечат устранение риска перехвата паролей,
ВАЖНЫЙ! Существует множество антивирусных программ.Также доступны пакеты интернет-безопасности. Они сочетают в себе функции антивируса, брандмауэра, блокировщика спама или блокировщика спама и превентивной системы. Вы можете зарегистрировать лучший антивирусный пакет такого типа на home.pl по очень низкой цене. Нажмите здесь, чтобы узнать больше о Kaspersky Internet Security. - для обеспечения безопасности, например, клиентов вашего интернет-магазина или портала, используйте SSL-сертификаты на веб-сайтах, которые обеспечивают безопасность передаваемых данных, например.при входе в систему или совершении покупок.
Управление паролями
Дополнительные инструменты, такие как менеджеры паролей, помогают поддерживать хорошие и надежные пароли, которые позволяют разделить несколько систем, в которых применяются пароли.
Приложения этого типа позволяют сохранять информацию о данных доступа, а также адреса веб-сайтов. Чаще всего все сохраняемые данные доступа дополнительно шифруются ключом. Доступ к менеджеру паролей обычно защищен одним мастер-паролем.Таким образом, вы можете сохранить все свои пароли в одном безопасном месте.
Хорошие менеджеры паролей также позволяют сгенерировать ключ, который можно хранить, например, на флешке. В этом случае для доступа к базе паролей требуется не только указать основной пароль к программе, но и указать файл (ключ), который позволит получить доступ к данным.
Примеры рекомендуемых в Интернете приложений, позволяющих управлять паролями доступа:
- Касперский ЧИСТЫЙ
- Безопасный пароль KeePass
- Была ли эта статья полезной?
- Да Нет
.Символ Омега
Что такое символ омега?
Омега — последняя из 24 букв греческого алфавита. В греческой системе счисления ему соответствовало число 800. В древности его называли омега «о». Минускул, маленькая омега, это «омикрон». Названия этих букв имеют византийское происхождение.
Как выглядит символ омега?
Majuskuła, или заглавная буква омега, выглядит как открытый внизу круг с двумя линиями, идущими снизу в обе стороны.Строчная буква омега, минускул, представляет собой две соединенные друг с другом петли, напоминающие латинскую строчную «w».
 Majuskuła и минускульные буквы омега, источник: Pixabay
Majuskuła и минускульные буквы омега, источник: Pixabay Что означает символ омега?
Последняя буква алфавита символизирует конец. Омега используется как символ во многих различных областях. Majuskuła означает, среди прочего в системе СИ - сопротивление, в космологии - плотность Вселенной; в парусном - яхт-класс; в математике - множество возможных комбинаций тех или иных элементов при данных условиях, в теории вероятностей - пространство элементарных событий.
Значений минускула столько же:
- в теории вероятностей означает единичное элементарное событие
- в технике - символ круговой части
- в астрономии - 24 звезды в данном созвездии (обозначение Байера)
- в физике является символом угловой скорости, т.е. вектор
- в квантовой механике - пульсации Планка.
Похожие символы
.

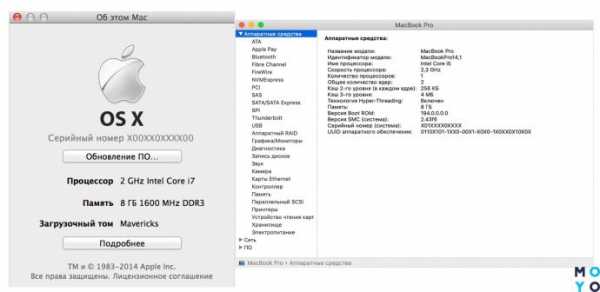







Видео-курс
