Что делать если в зоне пишет поиск источников
Помощь по работе с программой Zona
Что-то не работает
-
Антивирус блокирует Зону
Зона не содержит каких-либо вирусов, троянов и червей. Это подтверждают эксперты компании «AntiMalware» в своем отчете.
Зона гарантирует отсутствие вирусов в каталоге. Приложение работает только с проверенными базами. Риск заражения компьютера при работе с Зоной ниже, чем при скачивании файлов через браузер.
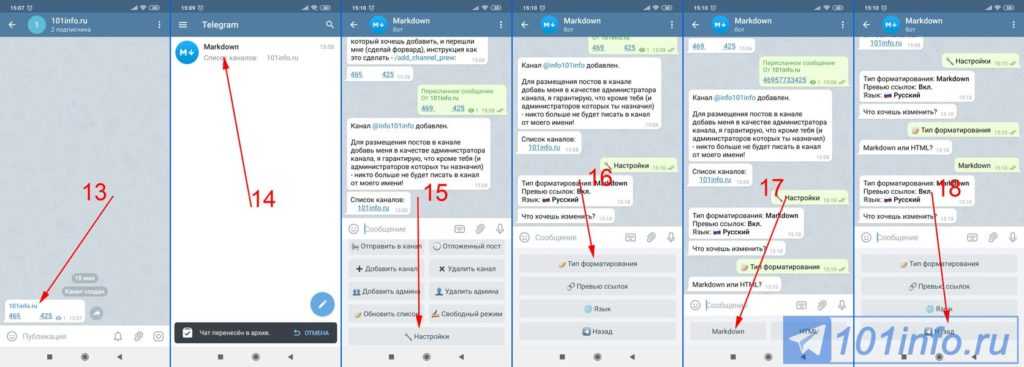
Инструкции по настройке Dr. Web, Eset Nod 32, AVG, Avast, Comodo и Avira
-
Ошибка доступа к серверу
Обычно эта ошибка связана с тем, что ваш антивирус или фаервол ошибочно блокирует Зону. Добавьте её в исключения. Инструкции по настройке Dr. Web, Eset Nod 32, AVG, Avast, Comodo и Avira
Так же эта ошибка может возникнуть, если у вас отключился интернет — проверьте настройки сети.
В редких случаях сервер Зоны не работает по техническим причинам. В этом случае подождите, когда работа сервера будет восстановлена.
-
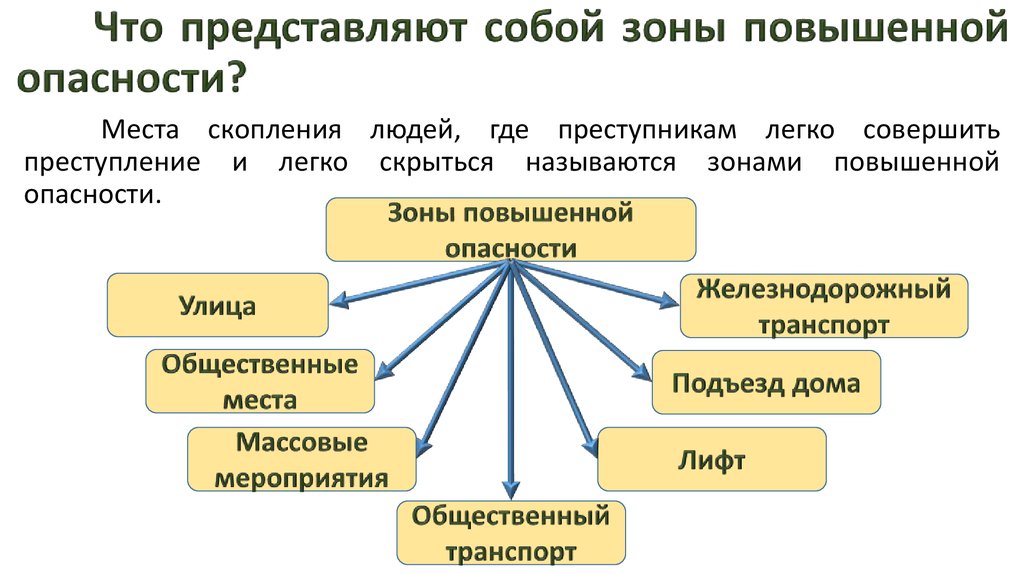
Нет источников
Зона скачивает фильмы и сериалы с помощью технологии торрент. Это означает, что файлы скачиваются с компьютеров других людей — это и есть источники.
Иногда источников нет в сети. Подождите, когда они появятся. Если файл не начал качаться в течение суток, скорее всего этот вариант никто не раздает — найдите другой вариант фильма или сериала, с большим количеством источников.
-
Не работают ТВ-каналы
Зона сменила поставщика телеканалов. В ближайшее время будет восстановлено работа 150 телеканалов. Установите последнюю версию Зоны.
-
Не работает раздел спорт
Зона находит ссылки на трансляции на разных сайтах. К сожалению, ссылки не всегда работают. Нажмите на название трансляции и выберите другой вариант из списка.
-
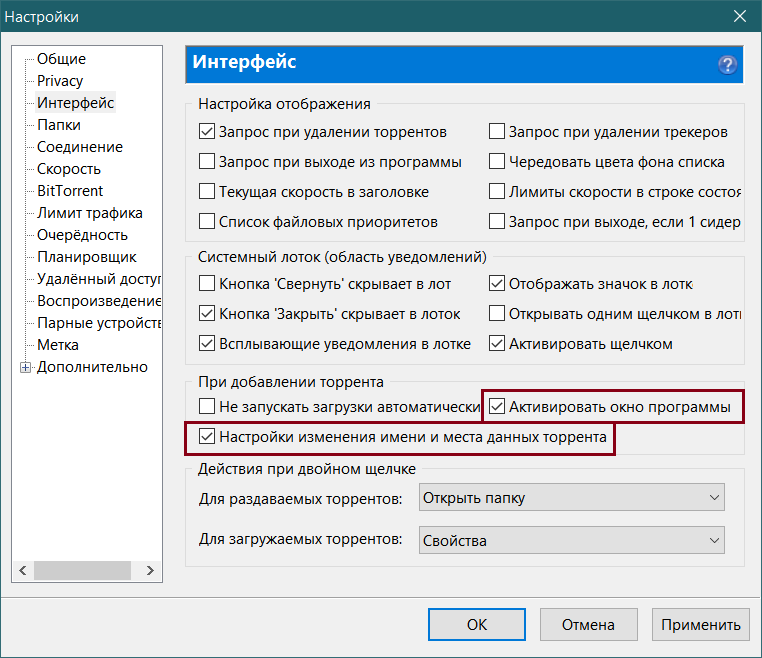
Телевизор не «видит» Зону
Убедитесь, что ваш телевизор поддерживает технологию DLNA.
Проверьте, что в настройках Зоны стоит галочка «Показывать скачанные фильмы на телевизорах с DLNA».
Зона на других платформах
-
Smart TV
Специального приложения для платформы Smart TV нет. Однако Зона транслирует видео по DLNA. Современные телевизоры с системой Smart TV поддерживают работу с DLNA.
-
Mac OS X, Linux
Зоны для этих платформ не существует. К сожалению, мы не можем сообщить, когда они выйдут и появятся ли вообще.
-
iOS, Android
Для просмотра фильмов и сериалов онлайн с мобильного устройства перейдите на сайтw6.zona.plus
Общие вопросы
-
Низкая скорость загрузки
В разделе загрузок откройте регулятор скорости в правом верхнем углу и нажмите «Без ограничений».
Убедитесь, что другие программы ничего не загружают в данным момент. Скачайте вариант фильма или сериала с большим количеством источников.
Подробнее в нашей группе VK
-
Как скачать весь сериал?
Зайдите на страницу сериала, нажав на его название.
 Прокрутите страницу до таблицы вариантов загрузки. Выберите «все сезоны» и «все серии», чтобы скачать сериал целиком.
Прокрутите страницу до таблицы вариантов загрузки. Выберите «все сезоны» и «все серии», чтобы скачать сериал целиком. -
Когда выйдет фильм?
Обычно фильмы появляются в Зоне через пару дней после выхода в кинотеатре. Cначала фильм появляется в низком качестве, снятый на камеру с экрана.
После выхода DVD он появится в высоком качестве. Чтобы не пропустить выход фильма — подпишитесь на него. Включите вкладку «+ недоступные» на странице поиска и нажмите «Узнать о выходе». Или оставьте заявку Вконтакте.
-
Как посмотреть новинки?
Зона показывает список фильмов в порядке популярности. Если вы хотите увидеть новинки, зайдите в раздел фильмов, нажмите на сортировку «Популярные сверху» и выберите «Новые сверху».
-
Как скопировать избранное?
Для доступа к избранному, подпискам и истории просмотров с разных компьютеров заведите учётную запись в Зоне. Все отметки о фильмах и сериалах будут едиными на всех ваших компьютерах и мобильных устройствах с Зоной.

Подробнее о регистрации и синхронизации
-
Фильмы для взрослых
В настройках программы включите функцию «Показывать фильмы, сериалы и ТВ-каналы для взрослых». Затем выберите «для взрослых» в списке жанров в нужном разделе. Скачанные и просмотренные фильмы попадают в «историю просмотра». При необходимости вы можете удалить их.
-
Как удалить Зону
Зайдите в «Пуск → Панель управления → Установка и удаление программ».
Найдите в списке Зону и нажмите «Удалить».
Регистрация и синхронизация
-
Зачем нужна регистрация?
Регистрация гарантирует хранение и доступ к избранному, истории и подпискам со всех устройств с установленной Зоной. В ближайшем будущем — и в мобильной Зоне.
-
Как зарегистрироваться?
Для регистрации нажмите «Вход» в верхнем правом углу окна Зоны. В появившейся форме введите почту и пароль и нажмите «Зарегистрироваться».
 Зона отправит на почтовый ящик письмо с кнопкой для потдверждения создания учётной записи. После её нажатия вернитесь к Зоне — учётная запись будет создана.
Зона отправит на почтовый ящик письмо с кнопкой для потдверждения создания учётной записи. После её нажатия вернитесь к Зоне — учётная запись будет создана. -
Что синхронизируется?
Синхронизируются избранное, просмотренные фильмы, подписки на фильмы и сериалы, позиция просмотра видео, язык интерфейса и предпочтительный язык фильмов. Загруженные фильмы и сериалы между компьютерами не переносятся.
Проблемы с установкой и их решение
-
Устаревшая версия Java
Зона сама пробует установить необходимую для работы версию Java. Это не всегда получается. Если у вас не запускается Зона, переустановите Java.
Зайдите в «Пуск → Панель управления → Установка и удаление программ».
Найдите в списке все программы, название которых начинается на Java, и нажмите Удалить. Найдите в списке программ Зону и удалите её. Теперь установите последнюю версию Зоны ещё раз.
-
Антивирус блокирует Зону
Зона не содержит каких-либо вирусов, троянов и червей.
 Это подтверждают эксперты компании «AntiMalware» в своем отчете.
Это подтверждают эксперты компании «AntiMalware» в своем отчете.Зона гарантирует отсутствие вирусов в каталоге. Приложение работает только с проверенными базами. Риск заражения компьютера при работе с Зоной ниже, чем при скачивании файлов через браузер.
Инструкции по настройке Dr. Web, Eset Nod 32, AVG, Avast, Comodo и Avira.
Инструкции о том, как сделать так, чтобы Аваст перестал блокировать Зону, от одного из наших пользователей.
-
Ничего не помогает
Скачайте и запустите скрипт диагностики. В результате его работы будет создан файл Diag.7z.
Отправьте этот файл по адресу [email protected], в тексте письма опишите, как именно проявляется проблема у вас.
из-за чего сбоит клиент (обновлено) — МирДоступа
Часто сервис Zona отказывается скачивать фильм или другой медиа-файл. Расскажем, почему Zona не качает и как вернуть клиент к жизни…
Торрент клиент Zona предназначен для потокового просмотра фильмов и скачивания других медиа продуктов таких как аудио, книги, игры.
[adace-ad id=»5173″]
Клиент обладает широким функционалом и стандартным набором инструментов.
Несмотря на в целом положительные отзывы многие пользователи жалуются на сбои в работе клиента. Кроме этого есть много жалоб на рассылку рекламных сообщений на которую пользователь подписываются при установке клиента
Случаются и сбои, при которых Zona и вовсе не запускается или не скачивает файлы.
Далее — разберем самые распространенные причины почему Zona не качает.
Почему Zona не открывается и не скачивает видео
Если клиент не запускается, то это может свидетельствовать о несовместимости программного обеспечения с текущей версии операционные системы. Проблемы с совместимостью ПО возникает чаще всего на ОС Windows 8, но данная проблема устраняется, буквально, одним кликом.
Необходимо кликнуть по ярлыку клиента правой кнопкой мыши и выбрать «Свойства» и найти подменю «Совместимость», далее — отметить соответствующую операционную систему
Если Zona запускается, но не качает, то необходимо проверить, блокирует ли работу программы брандмауэр или установленный антивирус — именно антивирусное программное обеспечение чаще всего является причиной того почему Zona не качает.
Чтобы проверить действительно ли антивирус является причиной сбоя Zona необходимо на время отключить антивирусное программное обеспечение
Если именно антивирус является причиной, то опознать данный случай очень просто.
[adace-ad id=»5168″]
Так если скачивание файла началось, то необходимо добавить клиент Zona в список исключений и антивирус больше не будет на него реагировать.
Zona не качает — причины и решения
Часто чтобы ответить на вопрос почему Zona не качает стоит попробовать переустановить платформу Java — для работы клиента Zona требуется её последняя версия.
Вообще, рекомендуется обновить все системные библиотеки и фреймворки до последней версии для корректной работы клиента
Часто если Zona не качает помогает её переустановка. Для этого необходимо сперва деинсталлировать клиент через «Установку и Удаление программ» Windows, а затем заново установить клиент.
Для корректного удаление клиента необходимо открыть проводник и в командной строке набрать %AppData%/Zona
После подтверждение команды все содержимое открывшейся папки нужно выделить и удалить. Только после этого необходимо приступать к инсталляции новой версии Java, а затем и самой Zona.
Только после этого необходимо приступать к инсталляции новой версии Java, а затем и самой Zona.
Скачивать дистрибутивы необходимо только с официальных сайтов разработчика. Установка в указанном порядке делается для того чтобы избежать конфликтов программного обеспечения.
Объяснениезон DNS
Что такое зона DNS?
Зона DNS — это отдельная часть пространства доменных имен, делегированная юридическому лицу — физическому лицу, организации или компании, ответственным за обслуживание зоны DNS. Зона DNS также является административной функцией, позволяющей детально контролировать компоненты DNS, такие как полномочные серверы имен.
Когда веб-браузеру или другому сетевому устройству необходимо найти IP-адрес для имени хоста, такого как «example.com», он выполняет поиск DNS — по сути, проверку зоны DNS — и перенаправляется на DNS-сервер, который управляет DNS зона для этого имени хоста. Этот сервер называется полномочным сервером имен для домена. Затем авторитетный сервер имен разрешает поиск DNS, предоставляя IP-адрес или другие данные для запрошенного имени хоста.
Затем авторитетный сервер имен разрешает поиск DNS, предоставляя IP-адрес или другие данные для запрошенного имени хоста.
Уровни зон DNS
Система доменных имен (DNS) определяет пространство доменных имен, в котором указаны домены верхнего уровня (например, «.com»), домены второго уровня (например, «acme.com») и ниже. домены уровня , также называемые субдоменами (например, «support.acme.com»). Каждый из этих уровней может быть зоной DNS.
Например, корневой домен «acme.com» может быть делегирован корпорации Acme. Acme берет на себя ответственность за настройку авторитетного DNS-сервера, который содержит правильные DNS-записи для домена.
На каждом иерархическом уровне системы DNS имеется сервер имен, содержащий файл зоны, который содержит надежные и правильные записи DNS для этой зоны.
Корневая зона DNS
Корень системы DNS, представленный точкой в конце доменного имени, например, www.example.com . — основная зона DNS. С 2016 года корневая зона находится под контролем Интернет-корпорации по присвоению имен и номеров (ICANN), которая делегирует управление дочерней компании, действующей в качестве Управления по присвоению номеров в Интернете (IANA).
С 2016 года корневая зона находится под контролем Интернет-корпорации по присвоению имен и номеров (ICANN), которая делегирует управление дочерней компании, действующей в качестве Управления по присвоению номеров в Интернете (IANA).
Корневая зона DNS управляется 13 логическими серверами, которыми управляют такие организации, как Verisign, Исследовательские лаборатории армии США и НАСА. Любой рекурсивный DNS-запрос (узнайте больше о типах DNS-запросов) начинается с обращения к одному из этих корневых серверов и запроса сведений для следующего уровня вниз по дереву — сервера домена верхнего уровня (TLD).
Зоны TLD
Для каждого домена верхнего уровня, например «.com», «.org» или кода страны, например «.co.uk», существует зона DNS. в настоящее время существует более 1500 доменов верхнего уровня. Большинство доменов верхнего уровня управляются ICANN/IANA.
Доменные зоны
Домены второго уровня, такие как домен, который вы сейчас просматриваете, «ns1. com», определяются как отдельные зоны DNS, управляемые отдельными лицами или организациями. Организации могут использовать свои собственные DNS-серверы имен или делегировать управление внешнему поставщику.
com», определяются как отдельные зоны DNS, управляемые отдельными лицами или организациями. Организации могут использовать свои собственные DNS-серверы имен или делегировать управление внешнему поставщику.
Если у домена есть поддомены, они могут быть частью одной зоны. В качестве альтернативы, если поддомен является независимым веб-сайтом и требует отдельного управления DNS, его можно определить как собственную зону DNS. На приведенной выше диаграмме «blog.example.com» был настроен как зона DNS, тогда как «support.example.com» является частью зоны DNS «example.com».
Вторичные зоны DNS
DNS-серверы могут быть развернуты в первичной/вторичной топологии, где вторичный DNS-сервер содержит доступную только для чтения копию DNS-записей первичного DNS-сервера. Первичный сервер содержит файл первичной зоны, а вторичный сервер представляет собой идентичную вторичную зону ; DNS-запросы распределяются между первичным и вторичным серверами. Передача зоны DNS происходит, когда файл зоны первичного сервера полностью или частично копируется на вторичный DNS-сервер.
Передача зоны DNS происходит, когда файл зоны первичного сервера полностью или частично копируется на вторичный DNS-сервер.
Все о файле зоны DNS
Файлы зоны DNS определены в RFC 1035 и RFC 1034. Файл зоны содержит сопоставления между доменными именами, IP-адресами и другими ресурсами, организованными в виде ресурсных записей (RR).
Чтобы увидеть фактический файл зоны для домена и протестировать передачу зоны DNS, вы можете выполнить поиск файла зоны с помощью одного из многих инструментов DNS.
Типы зон DNS
Существует два типа файлов зон:
- Первичный файл DNS, который авторитетно описывает зону
- Файл кэша DNS, в котором перечислены содержимое кэша DNS — это только копия официальной зоны DNS
Записи зоны DNS
В файле зоны каждая строка представляет запись ресурса DNS (RR). A record is made up of the following fields:
| name | ttl | record class | record type | record data |
- Имя — это буквенно-цифровой идентификатор записи DNS.
 Его можно оставить пустым, и он наследует свое значение от предыдущей записи.
Его можно оставить пустым, и он наследует свое значение от предыдущей записи. - TTL (время жизни) указывает, как долго запись должна храниться в локальном кэше DNS-клиента. Если не указано, используется глобальное значение TTL в начале файла зоны.
- Класс записи указывает пространство имен — обычно IN, которое является пространством имен Интернета.
- Тип записи — это тип записи DNS — например, запись A сопоставляет имя хоста с адресом IPv4, а CNAME — это псевдоним, который указывает имя хоста на другое имя хоста.
- Данные записи содержат один или несколько информационных элементов, в зависимости от типа записи, разделенных пробелом. Например, запись MX состоит из двух элементов — приоритета и доменного имени почтового сервера.
Структура файла зоны
Файлы зоны DNS начинаются с двух обязательных записей:
- Глобальное время жизни (TTL) , которое указывает, как записи должны храниться в локальном кэше DNS.

- Запись Start of Authority (SOA) — указывает основной полномочный сервер имен для зоны DNS.
После этих двух записей файл зоны может содержать любое количество записей ресурсов, включая: делегировано конкретному полномочному серверу имен
Zone File Tips
- При добавлении записи для имени хоста имя хоста должно заканчиваться точкой (.)
- Имена хостов, которые не заканчиваются точкой, считаются относительными к основному доменному имени — например, при указании записи «www» или «ftp» точка не нужна.

- Вы можете добавлять комментарии в файл зоны, добавляя точку с запятой (;) после записи ресурса.
Пример файла зоны DNS
$ORIGIN example.com. ; начало файла зоны $TTL 30m ; время истечения срока действия кэша по умолчанию для ресурса recordsexample.com. В SOA ns.example.com. root.example.com. ( 1999120701 ; серийный номер этой зоны file1d ; частота обновления вторичного DNS (d=day)1d ; частота обновления вторичного DNS в случае problem4w ; срок действия вторичного DNS (w=week)1h ; минимальное время кэширования, если разрешение failedexample.com. NS dns1.dnsprovider.com. ; есть два сервера имен, которые могут предоставлять услуги DNS, например, example.comexample.com. NS dns2.dnsprovider.com.example.com. MX 10 mx1.dnsprovider.com ; почтовый серверexample.com. MX 10 mx2.dnsprovider.comexample.com. А 192.168.100.1 ; IP-адрес для корневого домена www A 192.168.100.1 ; IP-адрес для субдомена www
Зоны DNS и службы DNS следующего поколения
Традиционная инфраструктура DNS имеет свои ограничения. Когда-то IP-адрес указывал на один сервер. Теперь за одним IP-адресом может скрываться пул сетевых ресурсов с балансировкой нагрузки, развернутых в разных центрах обработки данных по всему миру. Чтобы эффективно обслуживать эти ресурсы для пользователей, обеспечивать высокую производительность и обеспечивать быстрое распространение изменений, вам следует рассмотреть поставщика DNS следующего поколения, такого как NS1.
Когда-то IP-адрес указывал на один сервер. Теперь за одним IP-адресом может скрываться пул сетевых ресурсов с балансировкой нагрузки, развернутых в разных центрах обработки данных по всему миру. Чтобы эффективно обслуживать эти ресурсы для пользователей, обеспечивать высокую производительность и обеспечивать быстрое распространение изменений, вам следует рассмотреть поставщика DNS следующего поколения, такого как NS1.
NS1 Предоставляет:
- Управляемый DNS — служба DNS на основе высокопроизводительной глобальной сети DNS с произвольным вещанием и расширенными функциями управления трафиком.
- Выделенный DNS — полностью управляемое развертывание DNS локально или в облаке с расширенным управлением трафиком по принципу «укажи и щелкни». технологии генерации DNS.
рекомендаций по обходу контента в SharePoint Server — SharePoint Server
- Статья
- 18 минут на чтение
ПРИМЕНЯЕТСЯ К: 2013 2016 2019 Подписка SharePoint в Microsoft 365
Узнайте о рекомендациях по обходу контента в SharePoint Server.
Система поиска просматривает содержимое для создания поискового индекса, к которому пользователи могут выполнять поисковые запросы. В этой статье содержатся рекомендации по наиболее эффективному управлению сканированием.
Узнайте о ручном запросе сканирования и переиндексации для SharePoint в Microsoft 365.
Используйте учетную запись доступа к контенту по умолчанию для обхода большей части контента
Учетная запись доступа к контенту по умолчанию — это учетная запись домена, которую вы указываете для службы поиска SharePoint Server. использовать по умолчанию для сканирования. Для простоты лучше всего использовать эту учетную запись для обхода как можно большего объема контента, указанного вашими источниками контента. Чтобы изменить учетную запись для доступа к контенту по умолчанию, см.
раздел Изменение учетной записи по умолчанию для обхода контента в SharePoint Server.
Если вы не можете использовать учетную запись доступа к контенту по умолчанию для обхода определенного URL-адреса (например, из соображений безопасности), вы можете создать правило обхода, чтобы указать один из следующих вариантов аутентификации сканера:
-
Другой контент доступ к учетной записи
-
Сертификат клиента
-
Учетные данные формы
-
Файл cookie для сканирования
-
Анонимный доступ
Дополнительные сведения см. в разделе Управление правилами обхода контента в SharePoint Server.
Эффективное использование источников контента
Источник контента — это набор параметров в приложении-службе поиска, который используется для указания каждого из следующих компонентов:
-
Один или несколько начальных адресов для сканирования.
-
Тип содержимого в начальных адресах (например, сайты SharePoint Server, общие файловые ресурсы или бизнес-данные).
В источнике контента можно указать только один тип контента для обхода. Например, вы можете использовать один источник контента для обхода сайтов SharePoint Server, а другой — для обхода файловых ресурсов.
-
Расписание обхода и приоритет обхода для полного или добавочного обхода, которые будут применяться ко всем репозиториям контента, указанным источником контента.
При создании приложения-службы поиска система поиска автоматически создает и настраивает один источник контента с именем Локальные сайты SharePoint . Этот предварительно настроенный источник контента предназначен для обхода профилей пользователей и для обхода всех сайтов SharePoint Server в веб-приложениях, с которыми связано приложение-служба поиска. Вы также можете использовать этот источник контента для обхода контента в других фермах SharePoint Server, включая фермы SharePoint Server 2007, фермы SharePoint Server 2010, фермы SharePoint Server 2013 или другие фермы SharePoint Server.
Создавайте дополнительные источники контента, когда хотите выполнить любую из следующих задач:
-
Сканирование других типов контента
-
Ограничение или увеличение объема контента для сканирования
-
Более или менее часто сканировать определенный контент
-
Установка разных приоритетов для обхода определенного контента (это требование относится к полному и добавочному обходу, но не к непрерывному обходу)
-
Обходить определенный контент по разным расписаниям (это требование относится к полному и добавочному обходу, но не к непрерывному обходу)
Однако для максимального упрощения администрирования мы рекомендуем ограничить количество создаваемых и используемых источников контента.
Использование источников контента для планирования обходов
Вы можете отредактировать предварительно настроенный источник контента Локальные сайты SharePoint , чтобы указать расписание обхода; по умолчанию он не определяет расписание сканирования.
 Для любого источника контента можно запускать обход контента вручную, но мы рекомендуем запланировать добавочные обходы или включить непрерывные обходы, чтобы обеспечить регулярное обход контента.
Для любого источника контента можно запускать обход контента вручную, но мы рекомендуем запланировать добавочные обходы или включить непрерывные обходы, чтобы обеспечить регулярное обход контента. Рассмотрите возможность использования разных источников контента для обхода контента по разным расписаниям по следующим причинам.
-
Для учета времени простоя сервера и периодов пиковой нагрузки на сервер.
-
Для обхода содержимого, размещенного на более медленных серверах, отдельно от содержимого, размещенного на более быстрых серверах.
-
Для более частого сканирования содержимого, которое чаще обновляется.
Сканирование содержимого может значительно снизить производительность серверов, на которых размещается содержимое. Эффект зависит от того, достаточно ли ресурсов хост-серверов (особенно ЦП и ОЗУ) для обработки нагрузки. Таким образом, при планировании расписания сканирования учитывайте следующие рекомендации:
-
Запланируйте сканирование для каждого источника контента в то время, когда серверы, на которых размещается контент, доступны и когда потребность в ресурсах сервера низкая.

-
Распределить графики обхода так, чтобы нагрузка на серверы обхода и хост-серверы распределялась по времени. Вы можете оптимизировать графики обхода таким образом, когда ознакомитесь с типичной продолжительностью обхода для каждого источника контента, проверив журнал обхода. Дополнительные сведения см. в разделе Журнал обхода контента в статье Просмотр диагностики поиска в SharePoint Server.
-
Запускать полный обход контента только при необходимости. Дополнительные сведения см. в статье Причины для выполнения полного обхода в статье Планирование обхода контента и федерации в SharePoint Server. Любые административные изменения, для вступления в силу которых требуется полный обход контента, например создание правила обхода, вносятся незадолго до следующего полного обхода, чтобы дополнительный полный обход не требовался. Дополнительные сведения см. в статье Управление правилами обхода контента в SharePoint Server.
Обходить профили пользователей перед обходом сайтов SharePoint Server
По умолчанию в первом приложении-службе поиска в ферме предварительно настроенный источник контента Локальные сайты SharePoint содержит как минимум два следующих начальных адреса:
-
https://webAppUrl, предназначенный для обхода зоны по умолчанию.
 URL-адрес, указанный для существующих веб-приложений
URL-адрес, указанный для существующих веб-приложений -
sps3s://myWebAppUrl для сканирования профилей пользователей
Однако, если вы развертываете «Поиск людей», мы рекомендуем вам создать отдельный источник контента для начального адреса sps3s://myWebAppUrl и сначала выполнить сканирование для этого источника контента. Причина выполнения сканирования заключается в том, что после его завершения поисковая система создает список для стандартизации имен людей. Это сделано для того, чтобы, когда имя человека имеет разные формы в одном наборе результатов поиска, все результаты для этого человека отображаются в одной группе (известной как блок результатов ). Например, для поискового запроса «Энн Вейлер» все документы, созданные Анной Вейлер или А. Вейлер или псевдонимом АннеВ, могут отображаться в блоке результатов с пометкой «Документы Энн Вейлер». Точно так же все документы, созданные любым из этих удостоверений, могут отображаться под заголовком «Энн Вейлер» на панели уточнения, если «Автор» является одной из категорий.

Для обхода профилей пользователей и последующего обхода сайтов SharePoint Server
-
Убедитесь, что учетная запись пользователя, которая выполняет эту процедуру, является администратором приложения-службы поиска, которое вы хотите настроить.
-
Следуйте инструкциям в разделе Развертывание поиска людей в SharePoint Server. В рамках этих инструкций вы выполняете следующие задачи:
-
Создайте источник контента, предназначенный только для обхода профилей пользователей (хранилище профилей). Вы можете дать этому источнику контента имя, например «Люди». В новом источнике контента, в Начальные адреса введите sps3s:// myWebAppUrl, где myWebAppUrl — это URL-адрес хоста личного сайта.
-
Запустите сканирование для созданного вами источника контента «Люди».
-
Удалите начальный адрес sps3s://myWebAppUrl из предварительно настроенного источника контента Локальные сайты SharePoint .

-
Подождите около двух часов после завершения обхода источника контента "Люди".
-
Начать первый полный обход источника контента Локальные сайты SharePoint .
Используйте непрерывные обходы, чтобы обеспечить актуальность результатов поиска
Включить непрерывные обходы — это параметр расписания обхода, который можно выбрать при добавлении или изменении источника контента типа Сайты SharePoint . При непрерывном обходе выполняется обход содержимого, которое было добавлено, изменено или удалено с момента последнего обхода. Непрерывное сканирование запускается через определенные промежутки времени. Интервал по умолчанию — каждые 15 минут, но вы можете настроить непрерывный обход контента через более короткие интервалы с помощью Microsoft PowerShell. Поскольку непрерывные обходы происходят очень часто, они помогают обеспечить актуальность поискового индекса даже для часто обновляемого контента SharePoint Server.
 Кроме того, в то время как добавочный или полный обход задерживается из-за нескольких попыток обхода, которые возвращают ошибку для определенного элемента, непрерывный обход может выполнять обход другого контента и способствовать обновлению индекса, поскольку непрерывный обход не обрабатывает и не повторяет элементы, которые неоднократно возвращать ошибки. Такие ошибки повторяются во время «очищающего» добавочного обхода, который автоматически запускается каждые четыре часа для источников контента, для которых включен непрерывный обход. Элементы, которые продолжают возвращать ошибки во время добавочного обхода, будут повторяться во время будущих добавочных обходов, но не будут обнаружены непрерывными обходами до тех пор, пока ошибки не будут устранены.
Кроме того, в то время как добавочный или полный обход задерживается из-за нескольких попыток обхода, которые возвращают ошибку для определенного элемента, непрерывный обход может выполнять обход другого контента и способствовать обновлению индекса, поскольку непрерывный обход не обрабатывает и не повторяет элементы, которые неоднократно возвращать ошибки. Такие ошибки повторяются во время «очищающего» добавочного обхода, который автоматически запускается каждые четыре часа для источников контента, для которых включен непрерывный обход. Элементы, которые продолжают возвращать ошибки во время добавочного обхода, будут повторяться во время будущих добавочных обходов, но не будут обнаружены непрерывными обходами до тех пор, пока ошибки не будут устранены. Один непрерывный обход включает все источники контента в приложении-службе поиска, для которых включен непрерывный обход. Точно так же интервал непрерывного обхода контента применяется ко всем источникам контента в приложении-службе поиска, для которых включен непрерывный обход контента.
 Дополнительные сведения см. в статье Управление непрерывным обходом контента в SharePoint Server.
Дополнительные сведения см. в статье Управление непрерывным обходом контента в SharePoint Server. Непрерывные обходы увеличивают нагрузку на искатель и цели обхода. Убедитесь, что вы планируете и масштабируете это повышенное потребление ресурсов соответствующим образом. Для каждого крупного источника контента, для которого вы включаете непрерывный обход контента, мы рекомендуем настроить один или несколько интерфейсных веб-серверов в качестве выделенных целей для обхода контента. Дополнительные сведения см. в разделе Управление нагрузкой обхода (SharePoint Server 2010).
Используйте правила обхода, чтобы исключить нерелевантный контент из обхода.
Поскольку обход потребляет ресурсы и пропускную способность, при первоначальном развертывании может быть лучше обходить небольшой объем контента, который, как вы знаете, является релевантным, вместо обхода большего объема контента, некоторые из них могут быть неактуальны. Чтобы ограничить объем сканируемого контента, вы можете создать правила сканирования по следующим причинам:
По умолчанию сканер не будет переходить по сложным URL-адресам, то есть URL-адресам, содержащим вопросительный знак, за которым следуют дополнительные параметры, например, http: //contoso/page.
 aspx?x=y. Если вы разрешите сканеру следовать сложным URL-адресам, такая схема может привести к тому, что сканер будет собирать гораздо больше URL-адресов, чем ожидается или целесообразно. Это чрезмерное усвоение может привести к тому, что искатель соберет ненужные ссылки, заполнит базу данных обхода избыточными ссылками и приведет к увеличению индекса.
aspx?x=y. Если вы разрешите сканеру следовать сложным URL-адресам, такая схема может привести к тому, что сканер будет собирать гораздо больше URL-адресов, чем ожидается или целесообразно. Это чрезмерное усвоение может привести к тому, что искатель соберет ненужные ссылки, заполнит базу данных обхода избыточными ссылками и приведет к увеличению индекса. Эти меры могут помочь сократить использование ресурсов сервера и сетевого трафика, а также повысить релевантность результатов поиска. После первоначального развертывания вы можете просмотреть журналы запросов и обхода контента и настроить источники контента и правила обхода, чтобы при необходимости включить больше контента. Дополнительные сведения см. в статье Управление правилами обхода контента в SharePoint Server.
Обход зоны по умолчанию веб-приложений SharePoint Server
При обходе зоны по умолчанию веб-приложения SharePoint Server обработчик запросов автоматически сопоставляет и возвращает URL-адреса результатов поиска, чтобы они соответствовали сопоставлению альтернативного доступа (AAM).
 зона, из которой выполняются запросы. Этот параметр позволяет пользователям легко просматривать и открывать результаты поиска.
зона, из которой выполняются запросы. Этот параметр позволяет пользователям легко просматривать и открывать результаты поиска. Однако при обходе зоны веб-приложения, отличной от зоны по умолчанию, обработчик запросов не сопоставляет URL-адреса результатов поиска, чтобы они относились к зоне AAM, из которой выполняются запросы. Вместо этого URL-адреса результатов поиска будут относиться к просканированной зоне не по умолчанию. Из-за этого параметра пользователи могут не сразу просматривать или открывать результаты поиска.
Например, предположим, что у вас есть следующие AAM для веб-приложения с именем WebApp1:
По умолчанию Общедоступный URL-адрес Поставщик аутентификации По умолчанию https://контосо Аутентификация Windows: NTLM Экстранет https://fabrikam Проверка подлинности на основе форм Интранет http://fabrikam Аутентификация Windows: NTLM Теперь предположим, что вы просматриваете зону по умолчанию, https://contoso.
 Когда пользователи выполняют запросы из https://contoso/searchresults.aspx, все URL-адреса результатов из WebApp1 будут относиться к https://contoso и, следовательно, будут иметь вид https://contoso/ путь / результат .aspx.
Когда пользователи выполняют запросы из https://contoso/searchresults.aspx, все URL-адреса результатов из WebApp1 будут относиться к https://contoso и, следовательно, будут иметь вид https://contoso/ путь / результат .aspx. Аналогичным образом, когда запросы исходят из зоны Экстранета — в данном случае https://fabrikam/searchresults.aspx — все результаты из WebApp1 будут относиться к https://fabrikam и, следовательно, будут иметь вид https:/ /фабрикам/ путь / результат .aspx.
В обоих предыдущих случаях из-за согласованности зон между местоположением запроса и URL-адресами результатов поиска пользователи смогут легко просматривать и открывать результаты поиска без необходимости переключения на другой контекст безопасности другой зоны. .
Однако вместо этого скажите, что вы сканируете нестандартную зону, такую как зона интрасети, http://fabrikam. В этом случае для запросов из любой зоны URL-адреса результатов из WebApp1 всегда будут относиться к просканированной зоне не по умолчанию.
 То есть запрос из https://contoso/searchresults.aspx, https://fabrikam/searchresults.aspx или http://fabrikam/searchresults.aspx даст URL-адреса результатов поиска, которые начинаются с зоны, отличной от зоны по умолчанию. который был просканирован и поэтому будет иметь вид http://fabrikam/ путь / результат .aspx. Этот параметр может вызвать неожиданное или проблемное поведение, например:
То есть запрос из https://contoso/searchresults.aspx, https://fabrikam/searchresults.aspx или http://fabrikam/searchresults.aspx даст URL-адреса результатов поиска, которые начинаются с зоны, отличной от зоны по умолчанию. который был просканирован и поэтому будет иметь вид http://fabrikam/ путь / результат .aspx. Этот параметр может вызвать неожиданное или проблемное поведение, например: -
Когда пользователи пытаются открыть результаты поиска, им может быть предложено ввести учетные данные, которых у них нет. Например, пользователи, прошедшие проверку подлинности на основе форм в зоне экстрасети, могут не иметь учетных данных проверки подлинности Windows.
-
Результаты из WebApp1 будут использовать HTTP, но пользователи могут выполнять поиск в зоне экстрасети по адресу https://fabrikam/searchresults.aspx. Эта операция поиска пользователями может иметь последствия для безопасности, поскольку результаты не будут использовать шифрование уровня защищенных сокетов (SSL).

-
Уточнения могут фильтроваться неправильно, поскольку они фильтруют общедоступный URL-адрес для зоны по умолчанию, а не URL-адрес, который был просканирован. Эта неправильная фильтрация связана с тем, что свойства на основе URL-адреса в индексе будут относиться к просканированному URL-адресу, отличному от используемого по умолчанию.
Уменьшить влияние обхода на целевые объекты обхода SharePoint Server
Вы можете уменьшить влияние обхода на целевые объекты обхода SharePoint Server (то есть интерфейсные веб-серверы SharePoint Server), выполнив следующие задачи:
-
Для небольшой среды SharePoint Server перенаправьте весь трафик сканирования на один интерфейсный веб-сервер SharePoint Server. В большой среде перенаправьте весь трафик сканирования на определенную группу интерфейсных веб-серверов. Этот шаблон перенаправления сканирования не позволяет программе-обходчику использовать те же ресурсы, которые используются для отображения и обслуживания веб-страниц и контента для активных пользователей.

-
Ограничьте использование базы данных поиска в Microsoft SQL Server, чтобы программа-обходчик не использовала общие дисковые и процессорные ресурсы SQL Server во время обхода.
Дополнительные сведения см. в разделе Управление нагрузкой обхода (SharePoint Server 2010).
Использование правил воздействия искателя для ограничения эффекта сканирования
Чтобы ограничить влияние искателя, вы также можете создать правила воздействия искателя, которые доступны на странице Search_service_application_name: Search Administration. Правило воздействия сканера определяет скорость, с которой сканер запрашивает содержимое со начального адреса или диапазона начальных адресов. В частности, правило воздействия сканера либо запрашивает определенное количество документов за один раз с URL-адреса без ожидания между запросами, либо запрашивает один документ за один раз с URL-адреса и ожидает определенное время между запросами. Каждое правило влияния обходчика применяется ко всем компонентам обхода.

Для серверов в вашей организации вы можете установить правила воздействия сканера на основе известной производительности и емкости сервера. Однако этот параметр может быть недоступен для внешних сайтов. Таким образом, вы можете непреднамеренно использовать слишком много ресурсов на внешних серверах, запрашивая слишком много контента или запрашивая контент слишком часто. Такое интенсивное использование контента может привести к тому, что администраторы этих внешних серверов ограничат доступ к серверу, что сделает обход этих репозиториев затруднительным или невозможным для вас. Поэтому установите правила воздействия сканера так, чтобы они оказывали как можно меньшее влияние на внешние серверы, но при этом достаточно часто сканируете контент, чтобы убедиться, что актуальность индекса соответствует вашим требованиям.
Используйте группы Active Directory вместо отдельных пользователей для разрешений
Возможность пользователя или группы выполнять различные действия на сайте определяется назначаемым вами уровнем разрешений.
 Если вы добавляете или удаляете пользователей по отдельности для разрешений сайта или если вы используете группу SharePoint Server для указания разрешений сайта и изменяете членство в группе, обходчик должен выполнить «обход только безопасности», который обновляет все затрагиваемые элементы в индекс поиска, чтобы отразить изменение. Точно так же добавление или обновление политики веб-приложений с другими пользователями или группами SharePoint Server приведет к запуску обхода всего контента, на который распространяется эта политика. Это увеличивает нагрузку сканирования и может снизить актуальность результатов поиска. Поэтому для указания разрешений сайта лучше всего использовать группы доменных служб Active Directory (AD DS), так как эти группы не требуют от обходчика обновления затронутых элементов в индексе поиска.
Если вы добавляете или удаляете пользователей по отдельности для разрешений сайта или если вы используете группу SharePoint Server для указания разрешений сайта и изменяете членство в группе, обходчик должен выполнить «обход только безопасности», который обновляет все затрагиваемые элементы в индекс поиска, чтобы отразить изменение. Точно так же добавление или обновление политики веб-приложений с другими пользователями или группами SharePoint Server приведет к запуску обхода всего контента, на который распространяется эта политика. Это увеличивает нагрузку сканирования и может снизить актуальность результатов поиска. Поэтому для указания разрешений сайта лучше всего использовать группы доменных служб Active Directory (AD DS), так как эти группы не требуют от обходчика обновления затронутых элементов в индексе поиска. Добавьте второй компонент обхода для обеспечения отказоустойчивости
При создании приложения-службы поиска топология поиска по умолчанию включает один компонент обхода.
 Компонент обхода извлекает элементы из репозиториев контента, загружает элементы на сервер, на котором размещается компонент обхода, передает элементы и связанные с ними метаданные компоненту обработки контента и добавляет информацию, относящуюся к обходу, в соответствующие базы данных обхода. Вы можете добавить второй компонент сканирования, чтобы обеспечить отказоустойчивость. Если один компонент обхода станет недоступен, оставшийся компонент возьмет на себя все обходы. Для большинства ферм SharePoint Server достаточно двух компонентов обхода контента.
Компонент обхода извлекает элементы из репозиториев контента, загружает элементы на сервер, на котором размещается компонент обхода, передает элементы и связанные с ними метаданные компоненту обработки контента и добавляет информацию, относящуюся к обходу, в соответствующие базы данных обхода. Вы можете добавить второй компонент сканирования, чтобы обеспечить отказоустойчивость. Если один компонент обхода станет недоступен, оставшийся компонент возьмет на себя все обходы. Для большинства ферм SharePoint Server достаточно двух компонентов обхода контента. Дополнительные сведения см. в следующих статьях:
-
Обзор архитектуры поиска в SharePoint Server
-
Изменение топологии поиска по умолчанию в SharePoint Server
-
Управление компонентами поиска в SharePoint Server
-
Новый SPEnterpriseSearchCrawlComponent
Управляйте ресурсами среды для повышения производительности обхода контента
Когда программа-обходчик просматривает содержимое, загружает его на сервер обхода (сервер, на котором размещен компонент обхода) и передает содержимое компонентам обработки содержимого, несколько факторов могут неблагоприятно повлиять на производительность.
 Чтобы повысить производительность сканирования, вы можете выполнить следующую задачу:
Чтобы повысить производительность сканирования, вы можете выполнить следующую задачу: Для устранения этого потенциального узкого места в производительности Реализовать это решение Медленное время отклика от просканированных серверов Обеспечьте больше ЦП и ОЗУ и более быстрый дисковый ввод-вывод Низкая пропускная способность сети Установите 1 или 2 сетевых адаптера со скоростью один гигабит в секунду на каждом сервере сканирования Обработка контента Предоставьте больше компонентов обработки контента и больше ресурсов ЦП для каждого компонента обработки контента Медленная обработка компонентами индекса Добавить ресурсы ввода-вывода для серверов, на которых размещены компоненты индекса Дополнительные сведения см. в следующих ресурсах:
-
Масштаб поиска интернет-сайтов в SharePoint Server
-
SharePoint 2013: рекомендации по масштабированию сканирования
Перед изменением топологии поиска убедитесь, что обходы не активны.

Перед изменением топологии поиска рекомендуется убедиться, что обходы не выполняются. В противном случае возможно, что изменение топологии не будет происходить плавно.
При необходимости можно вручную приостановить или остановить полное или добавочное сканирование, а также отключить непрерывное сканирование. Дополнительные сведения см. в следующих статьях:
-
Запуск, приостановка, возобновление или остановка сканирования в SharePoint Server
-
Управление непрерывным обходом контента в SharePoint Server
Примечание
Недостаток приостановки обхода состоит в том, что ссылки на компоненты обхода могут остаться в таблице MSSCrawlComponentsState в базе данных администрирования поиска. Это может вызвать проблемы, если вы хотите удалить какие-либо компоненты обхода контента (например, потому что вы хотите удалить из фермы сервер, на котором размещены эти компоненты). Однако при остановке обхода ссылки на компоненты обхода в таблице MSSCrawlComponentsState удаляются.
 Поэтому, если вы хотите удалить компоненты обхода, лучше остановить обход, чем приостановить обход.
Поэтому, если вы хотите удалить компоненты обхода, лучше остановить обход, чем приостановить обход. Чтобы убедиться, что сканирование не выполняется, на странице Search_service_application_name : Управление источниками контента убедитесь, что значение в поле Состояние для каждого источника контента равно Бездействие или Приостановлено . (По завершении обхода или при остановке обхода значение в поле Статус для источника контента изменится на Бездействие .)
Удалите компоненты обхода с узла обхода перед удалением узла с ферма
Если на сервере размещен компонент обхода контента, удаление сервера из фермы может сделать невозможным обход содержимого системой поиска. Поэтому перед удалением узла обхода из фермы настоятельно рекомендуется выполнить следующие задачи:
-
Убедитесь, что обходы не активны.
Дополнительные сведения см. в предыдущем разделе Убедитесь, что обходы не активны, прежде чем изменять топологию поиска.
-
Удалите или переместите компоненты обхода, находящиеся на этом узле.
Дополнительные сведения см. в следующих ресурсах:
-
Управление топологией поиска в SharePoint Server
-
Изменение топологии поиска по умолчанию в SharePoint Server
-
Удаление компонента поиска или перемещение компонента поиска в разделе Управление компонентами поиска в SharePoint Server
-
Удаление сервера из фермы в SharePoint Server 2016
-
SP2010: удаление или повторное присоединение сервера к ферме может нарушить поиск
Проверка функций обхода и запросов после изменения конфигурации обхода или применения обновлений
Мы рекомендуем протестировать функции обхода и запросов в ферме серверов после внесения изменений в конфигурацию или применения обновлений. Следующая процедура является примером простого способа выполнения такого теста.
Проверка функций обхода контента и запросов
-
Убедитесь, что учетная запись пользователя, выполняющая эту процедуру, является администратором приложения-службы поиска, которое вы хотите настроить.

-
Создайте источник контента, который вы будете временно использовать только для этого теста.
В новом источнике контента в разделе Начальные адреса в поле Введите начальные адреса ниже (по одному в строке) укажите начальный адрес, содержащий несколько элементов, которых еще нет в индексе — например, несколько TXT, которые находятся в общей папке. Дополнительные сведения см. в разделе Добавление, изменение или удаление источника контента в SharePoint Server.
-
Начать полный обход этого источника контента.
Дополнительные сведения см. в статье Запуск, приостановка, возобновление или остановка обхода контента в SharePoint Server. По завершении сканирования на странице Search_service_application_name : Управление источниками контента значением в столбце Состояние для источника контента будет Idle . (Чтобы обновить столбец Статус , обновите страницу Управление источниками контента, нажав Обновить .
 )
) -
После завершения обхода перейдите в Центр поиска и выполните поисковые запросы, чтобы найти эти файлы.
Если в вашем развертывании еще нет центра поиска, см. раздел Создание сайта центра поиска в SharePoint Server.
-
После завершения тестирования удалите временный источник контента.
Эта операция удаляет элементы, указанные этим источником контента, из поискового индекса, чтобы они не отображались в результатах поиска после завершения тестирования.
В журнале сканирования отслеживается информация о статусе просканированного содержимого. Журнал включает представления для источников контента, хостов, ошибок, баз данных, URL-адресов и истории. Например, вы можете использовать этот журнал, чтобы определить время последнего успешного обхода источника контента, успешно ли он был добавлен в индекс, был ли он исключен из-за правила обхода или не удалось выполнить обход из-за ошибки. .
Отчеты о работоспособности обхода содержат подробные сведения о скорости обхода, задержке обхода, актуальности обхода, обработке контента, загрузке ЦП и памяти, непрерывных обходах и очереди обхода.











Видео-курс
