Функция подставить в excel примеры
Функция ПОДСТАВИТЬ
В этой статье описаны синтаксис формулы и использование ПОДСТАВИТЬ в Microsoft Excel.
Описание
Подставляет значение аргумента "нов_текст" вместо значения аргумента "стар_текст" в текстовой строке. Функция ПОДСТАВИТЬ используется, когда нужно заменить определенный текст в текстовой строке; функция ЗАМЕНИТЬ используется, когда нужно заменить любой текст начиная с определенной позиции.
Синтаксис
ПОДСТАВИТЬ(текст;стар_текст;нов_текст;[номер_вхождения])
Аргументы функции ПОДСТАВИТЬ описаны ниже.
-
Текст Обязательный. Текст или ссылка на ячейку, содержащую текст, в котором подставляются знаки.
-
Стар_текст Обязательный. Заменяемый текст.
-
Нов_текст Обязательный. Текст, на который заменяется "стар_текст".
-
Номер_вхождения Необязательный. Определяет, какое вхождение фрагмента "стар_текст" нужно заменить фрагментом "нов_текст". Если этот аргумент определен, то заменяется только заданное вхождение фрагмента "стар_текст". В противном случае все вхождения фрагмента "стар_текст" в тексте заменяются фрагментом "нов_текст".
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|---|---|---|
|
Сведения о продажах |
< |
|
|
Квартал 1, 2008 г. |
< |
|
|
Квартал 1, 2011 г. |
< |
|
|
Формула |
Описание (результат) |
Результат |
|
=ПОДСТАВИТЬ(A2; "продажах"; "ценах") |
Замена "ценах" на "продажах" ("Сведения о ценах") |
Сведения о ценах |
|
=ПОДСТАВИТЬ(A3; "1"; "2"; 1) |
Замена первого экземпляра "1" на "2" ("Квартал 2, 2008 г.") |
Квартал 2, 2008 г. |
|
=ПОДСТАВИТЬ(A4; "1"; "2"; 3) |
Замена третьего экземпляра "1" на "2" ("Квартал 1, 2012 г.") |
Квартал 1, 2012 г. |
См. также
Функция ЗАМЕНИТЬ, ЗАМЕНИТЬБ
Функция СЖПРОБЕЛЫ
Замена текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
Замена одного текста на другой внутри заданной текстовой строки - весьма частая ситуация при работе с данными в Excel. Реализовать подобное можно двумя функциями: ПОДСТАВИТЬ (SUBSTITUTE) и ЗАМЕНИТЬ (REPLACE). Эти функции во многом похожи, но имеют и несколько принципиальных отличий и плюсов-минусов в разных ситуациях. Давайте подробно и на примерах разберем сначала первую из них.
Её синтаксис таков:
=ПОДСТАВИТЬ(Ячейка; Старый_текст; Новый_текст; Номер_вхождения)
где
- Ячейка - ячейка с текстом, где производится замена
- Старый_текст - текст, который надо найти и заменить
- Новый_текст - текст, на который заменяем
- Номер_вхождения - необязательный аргумент, задающий номер вхождения старого текста на замену
Обратите внимание, что:
- Если не указывать последний аргумент Номер_вхождения, то будут заменены все вхождения старого текста (в ячейке С1 - обе "Маши" заменены на "Олю").
- Если нужно заменить только определенное вхождение, то его номер задается в последнем аргументе (в ячейке С2 только вторая "Маша" заменена на "Олю").
- Эта функция различает строчные и прописные буквы (в ячейке С3 замена не сработала, т.к. "маша" написана с маленькой буквы)
Давайте разберем пару примеров использования функции ПОДСТАВИТЬ для наглядности.
Замена или удаление неразрывных пробелов
При выгрузке данных из 1С, копировании информации с вебстраниц или из документов Word часто приходится иметь дело с неразрывным пробелом - спецсимволом, неотличимым от обычного пробела, но с другим внутренним кодом (160 вместо 32). Его не получается удалить стандартными средствами - заменой через диалоговое окно Ctrl+H или функцией удаления лишних пробелов СЖПРОБЕЛЫ (TRIM). Поможет наша функция ПОДСТАВИТЬ, которой можно заменить неразрывный пробел на обычный или на пустую текстовую строку, т.е. удалить:
Подсчет количества слов в ячейке
Если нужно подсчитать количество слов в ячейке, то можно применить простую идею: слов на единицу больше, чем пробелов (при условии, что нет лишних пробелов). Соответственно, формула для расчета будет простой:
Если предполагается, что в ячейке могут находиться и лишние пробелы, то формула будет чуть посложнее, но идея - та же.
Извлечение первых двух слов
Если нужно вытащить из ячейки только первые два слова (например ФИ из ФИО), то можно применить формулу:
У нее простая логика:
- заменяем второй пробел на какой-нибудь необычный символ (например #) функцией ПОДСТАВИТЬ (SUBSTITUTE)
- ищем позицию символа # функцией НАЙТИ (FIND)
- вырезаем все символы от начала строки до позиции # функцией ЛЕВСИМВ (LEFT)
Ссылки по теме
12 текстовых функций Excel на каждый день
При использовании Excel часто необходимо работать не только с числами, но и с текстом. В этой статье мы разберем 12 основных функций Excel для обработки текста.
Для примера возьмем строку «ExcelGuide.ru – про Excel и не только» и ее будем использовать в наших функциях ниже.
ЛЕВСИМВ
Функция ЛЕВСИМВ возвращает указанное количество знаков с начала строки. В качестве аргументов на первом месте указываем ту строку, из которой хотим извлечь текст, а вторым аргументом количество символов, которое хотим получить.Давайте из нашей строки получим текст «ExcelGuide.ru»:
=ЛЕВСИМВ(B1;13)
ПРАВСИМВ
Функция ПРАВСИМВ аналогична ЛЕВСИМВ, только возвращает указанное количество символов не с начала, а с конца строки. Первым аргументом указываем строку, откуда будем получать часть текста, а вторым аргументом – количество символов.Из нашей строки извлечем текст «про Excel и не только»:
=ПРАВСИМВ(B1;21)
ПСТР
Функция ПСТР позволяет получить указанное количество символов начиная с определенной позиции. У этой функции 3 аргумента: Текст, из которого нам нужно получить часть; стартовая позиция, с которой нужно извлечь символы; количество символов, которое хотим получить.В нашей строке есть слово Excel, давайте его получим:
=ПСТР(B1;21;5)
ДЛСТР
Функция ДЛСТР возвращает количество символов в строке.
=ДЛСТР(B1)
ПОИСК
Функция ПОИСК предназначена для нахождения первого вхождения указанного текста в исходную строку. Аргументы функции: сначала указываем тот текст, который хотим найти; далее строку, в которой ищем текст.
Давайте в нашем примере найдем текст «про Excel»:
=ПОИСК("про Excel";B1)
СЦЕПИТЬ
Функция СЦЕПИТЬ позволяет последовательно объединить несколько текстовых элементов в одну строку.В качестве аргументов необходимо перечислить те текстовые элементы, которые вы хотите соединить.
В качестве примера объединим наш пример и строку «. Пожалуй лучший сайт про Excel )))»:
=СЦЕПИТЬ(B1;". Пожалуй лучший сайт про Excel )))")
СОВПАД
Функция СОВПАД проверяет идентичность двух строк и возвращает Истина, если строки совпадают и ЛОЖЬ, если строки не совпадают.
Сравним нашу строку с текстом «ExcelGuide.ru»:
=СОВПАД(B1;"ExcelGuide.ru")
СЖПРОБЕЛЫ
Функция СЖПРОБЕЛЫ удаляет лишние дублирующие пробелы. В качестве аргумента указываем строку, у которой надо удалить лишние пробелы.=СЖПРОБЕЛЫ(B1)
ЗНАЧЕН
Функция ЗНАЧЕН преобразует текст в число. Часто случается при экспорте из разных информационных систем мы получаем числовые значения в текстовом формате, в таких случаях нам и пригодится этот функционал.
В качестве примера преобразуем текст «1000» в число 1 000:
=ЗНАЧЕН("1000")
ПОДСТАВИТЬ
Функция ПОДСТАВИТЬ заменяет новым текстом старый текст в исходной текстовой строке. Аргументов у функции три: сначала указываем ту строку, в которой будем менять текст; далее указываем старый текст; а затем тот, которым мы хотим заменить.
В качестве примера в нашей строке заменим «про» на «о»:
=ПОДСТАВИТЬ(B1;"про";"о")
ПРОПИСН
Функция ПРОПИСН преобразует все буквы в прописные. У функции только один аргумент – та строка, которую надо преобразовать.=ПРОПИСН(B1)
СТРОЧН
Функция СТРОЧН преобразует все буквы в строчные. У функции один аргумент – тот текст, который мы хотим модифицировать.
=СТРОЧН(B1)
Кстати, если вы хотите более подробно изучить Excel, научиться строить быстро сложные отчеты и графики, то рекомендую вам курс "Excel + Google Таблицы с нуля до PRO" от Skillbox.
Спасибо за внимание. Мы разобрали 12 основных текстовых функций в Excel, которые вам могут пригодиться в ежедневной работе.
Похожие сообщения:
Excel заменить текст в ячейках - Исправление содержимого ячеек при помощи функции автоматической замены текста
Добрый день уважаемый читатель!Сегодня хочу продолжить тему текстовых функций в Excel и предлагаю вам вторую часть по этой теме. Всё же текст занимает достаточно значительную часть работы в программе и игнорировать этот факт не будет правильным поведением, а значится нужно учить или хотя бы просто ознакомиться с данной возможностью. Очень часто в работе встречаются задачи которые можно решить зная возможности работы с текстом и это поможет сохранить ваше время и километры нервных волокон при выполнении заданий, которые стоят перед вами. Так как, казалось бы простая функция, а вот ее применение к месту, может решить трудную задачу.
Ну вот, давайте познакомимся с второй частью функций, которые работают с текстом и вашему вниманию предоставляю очередные 7 инструментов:
- Функция ПОДСТАВИТЬ;
- Функция ПРОПИСН;
- Функция ПСТР;
- Функция СЖПРОБЕЛЫ;
- Функция СОВПАД;
- Функция СТРОЧН;
- Функция ПРОПНАЧ.
Для тех, кто не читал первую часть, я повторюсь где можно отыскать весть набор функций. Перейдите на панели инструментов во вкладку «Формулы» и нажмите иконку «Текстовые», в выпадающем меню выберете функцию которая вам нужна, это будет быстрый способ. Вторым вариантом будет в этой же вкладке нажать иконку «Вставить функцию» и в новом диалоговом окне в категории выбираете «Текстовые», но данный способ я считаю лучшим так как снизу окна идет описание выбранной функции что очень полезно.
Функция ПОДСТАВИТЬ
Эта функция может заменить определённый текст на новый вариант. Работа функции очень схожа с действием функции ЗАМЕНИТЬ, но есть небольшое и принципиальное отличие. Рассматриваемая функция самостоятельно и автоматически находит необходимый текст к замене и меняет его, а функция ЗАМЕНИТЬ, производит замену только указанный вручную посимвольно.
Синтаксис функции:
= ПОДСТАВИТЬ(_текст_; _старый_текст_; _новый_текст_; _[номер_вхождения]_), где:
- текст — это прописанный вручную текст или ссылка на ячейку содержащая текстовое значение;
- старый текст — это условия с первого аргумента, который следует заменить;
- новый текст — условие которые нужно для замены старого текста;
- номер вхождения — является не обязательным аргументом, но если он не будет указан, то произойдет замена всех похожих условий. Обязательно бывает только целым числом, оно означает номер по порядку аргумента «старый текст», который нужно заменить, всё остальное изменяться не будет.
Пример применения:
Дополнительно ознакомится с примерами применения функции можно в статье «5 быстрых способов как заменить точки на запятые в Excel».Функция ПРОПИСН
Простая текстовая функция которая позволяет преобразовать все буквы с нижнего в верхний регистр или проще сделать их прописными. Работает только с буквами и все остальные знаки что ими не являются он попросту игнорирует. Очень часто используется SEO-специалистами в своей работе.
Синтаксис функции:
= ПРОПИСН(_текст_), где:
- текст — текст или ссылка на текст который требует преобразовать.
Пример применения:
Функция ПСТР
Очень полезная функция, она может извлекать из определенной ячейки, ту часть текста в том объёме символов, который вам нужен, начиная с нужного символа. То есть эта текстовая функция может вытянуть любые нужные нам данные, например, номенклатурный номер, название компании, требуемый код и многое другое.
Синтаксис функции:
= ПСТР(_текст_; _начальная_позиция_; _количество_знаков_), где:
- текст — текст или ссылка на текст который содержит текст;
- начальная позиция — указывается номер по порядку символа, с которого формула будет изымать содержимое;
- количество знаков — прописывается то количество символов, которые необходимо отобрать согласно аргументу «начальная позиция». Указывается целым натуральным числом.
Пример применения:
Формулу можно усложнить, сделать ее более гибкой добавив интеграцию с функциями НАЙТИ и ДЛСТР. Более детально, с описаниями и сложными примерами этой функцией можно ознакомится в статье «Функция ПСТР в Excel».Функция СЖПРОБЕЛЫ
Очень простая и эффективная функция, которая может убрать все ненужные пробелы в тексте: удвоенные пробелы между словами, пробелы в начале и конце предложения. После обработки данных этой функцией останутся только нужные одиночные пробелы в предложении или фразе между словами. Хорошо использовать, когда каждый знак имеет значение так как поля ввода могут быть с лимитом, использовать в рабочих листах, которые были импортированы из других внешних источников или же просто красиво оформить текст в вашей таблице. Очень часть импортированные тексты содержат разнообразные непечатаемые символы или лишние пробелы, с помощью функции ПЕЧСИМВ вы можете удалить ненужные символы.
Синтаксис функции:
= СЖПРОБЕЛЫ(_текст_), где:
- текст — текст или ссылка на текст в котором следует убрать лишние пробелы.
Пример применения:
Функция СОВПАД
Главной особенностью функции СОВПАД, это сравнение двух текстовых ячеек на похожесть и в случае совпадение возвращается значение ИСТИНА, а если совпадения нет — ЛОЖЬ. Обращаю ваше внимание что функция чувствительна к регистру, но что радует, что ей без разницы какое форматирование содержит ячейка.
Синтаксис функции:
= СОВПАД(_текст1_;_текст2_), где:
- текст № 1, текст № 2— тексты или ссылка на тексты которые будут сравниваться для получения результата.
Пример применения:
Если же регистр текста для вас не важен, то вполне можно использовать формулу сверки ячеек: =B2=C2 для проверки единичности значений. В пункте 4 вы можете визуально наблюдать что текстовые значения одинаковы, но формула выдает значение ЛОЖЬ, это связано с тем что в ячейке содержатся невидимые пробелы, возникает ошибка в результатах, для ее избежания достаточно ввести в формулу функцию СЖПРОБЕЛЫ, и проблема будет решена.Функция СТРОЧН
Работа функции заключается в преобразовании всех букв в ячейке с верхнего в нижний регистр или сделать весть текст строчным. Оперирует только с буквами, все остальные символы и знаки будут опущены.
Синтаксис функции:
= СТРОЧН(_текст_), где:
- текст — текст или ссылка на текст который требует сделать строчным.
Пример применения:
Функция ПРОПНАЧ
Текстовая функция которая в каждом слове первую букву делает заглавной, а все остальные переделывает в строчные. Вообще идеальная функция для работников кадровых служб или бухгалтеров по заработной плате, так работа со списками ФИО она проделывает просто на 5+.
Синтаксис функции:
= ПРОПНАЧ(_текст_), где:
- текст — текст или ссылка на текст который требует начать с заглавной буквы.
Пример применения:
И снова я не буду с вами прощаться так как о всех текстовых функция в Excel, я еще не рассказал и впереди еще одна, заключительная, часть. А если вы начали читать описание функций с этой статьи и не нашли нужной, посмотрите часть 1 и часть 3, по этой теме.
Как использовать функцию ЗАМЕНЫ в Excel -
Резюме
Функция ЗАМЕНИТЬ в Excel заменяет текст в заданной строке сопоставлением. Например, = SUBSTITUTE ("952-455-7865", "-", "") возвращает "9524557865"; черточка лишена. SUBSTITUTE чувствителен к регистру и не поддерживает подстановочные знаки.
Цель
Заменить текст на основе содержимогоВозвращаемое значение
Обработанный текстСинтаксис
= ПОДСТАВИТЬ (текст; старый_текст; новый_текст; (экземпляр))Аргументы
- text - текст, который нужно изменить.
- old_text - текст для замены.
- new_text - текст для замены.
- instance - (необязательно) экземпляр для замены. Если не поставляется, заменяются все экземпляры.
Версия
Excel 2003Примечания по использованию
Функция ЗАМЕНА в Excel может заменять текст соответствием. Используйте функцию ЗАМЕНА, если вы хотите заменить текст на основе его содержимого, а не положения. При желании вы можете указать экземпляр найденного текста для замены (т.е. первый экземпляр, второй экземпляр и т. Д.).
Примеры
Ниже приведены формулы, использованные в примере, показанном выше:
=SUBSTITUTE(B6,"t","b") // replace all t's with b's =SUBSTITUTE(B7,"t","b",1) // replace first t with b =SUBSTITUTE(B8,"cat","dog") // replace cat with dog =SUBSTITUTE(B9,"#","") // replace # with nothing
Обратите внимание, что SUBSTITUTE чувствителен к регистру. Чтобы заменить один или несколько символов ничем, введите пустую строку (""), как в последнем примере.
Заметки
- SUBSTITUTE находит и заменяет old_text на new_text в текстовой строке.
- Экземпляр ограничивает замену SUBSTITUTE одним конкретным экземпляром old_text . если не указан, все экземпляры old_text заменяются на new_text .
- Используйте SUBSTITUTE для замены текста в зависимости от содержимого. Используйте функцию REPLACE для замены текста в зависимости от его местоположения.
- SUBSTITUTE чувствителен к регистру и не поддерживает подстановочные знаки.
Похожие видео
Как подсчитывать символы с помощью функции LEN В этом видео мы рассмотрим, как использовать функцию LEN для вычисления количества символов в текстовой строке. LEN - удивительно полезная функция, которая встречается во многих формулах. Как собрать все в одном формуле В этом видео мы создаем формулу, которая подсчитывает слова в ячейке с помощью функций LEN и SUBSTITUTE.| Функция и ее синтаксис | Краткое описание работы |
|---|---|
| СИМВОЛ(число) | Возвращает знак с заданным числовым кодом |
| ПЕЧСИМВ (текст) | Удаляет все непечатаемые знаки из текста. Функция ПЕЧСИМВ используется в том случае, когда текст, импортированный из другого приложения, содержит знаки, печать которых невозможна |
| КОДСИМВ (текст) | Возвращает числовой код первого знака во введенной текстовой строке |
| СЦЕПИТЬ (текст1; текст2;…) | Объединяет две или более текстовых строк в одну |
| РУБЛЬ (число; число_знаков) | Функция преобразует число в текстовый формат и добавляет к нему обозначение денежной единицы рубль (р.) |
| СОВПАД (текст1; текст2) | Сравнивает две строки текста и возвращает значение ИСТИНА, если они в точности совпадают, и ЛОЖЬ — в противном случае. Функция учитывает регистр, но игнорирует различия в форматировании |
| НАЙТИ (искомый_текст; просматриваемый_текст; нач_позиция) | Функция находит вхождение одной текстовой строки в другой строке (с учетом регистра) и возвращает начальную позицию первой строки относительно крайнего левого знака второй строки |
| ФИКСИРОВАННЫЙ (число; число_знаков; без_разделителей) | Округляет число до заданного количества десятичных цифр, форматирует число в десятичном формате с использованием запятой и разделителей тысяч и возвращает результат в виде текста |
| ЛЕВСИМВ (текст; количество_знаков) | Функция ЛЕВСИМВ возвращает первые знаки текстовой строки, исходя из заданного количества знаков |
| ДЛСТР (текст) | Функция ДЛСТР возвращает количество знаков в текстовой строке |
| СТРОЧН (текст) | Преобразует знаки в текстовой строке из верхнего регистра в нижний |
| ПСТР (текст; начальная_позиция; число_знаков) | Функция ПСТР возвращает указанное число знаков из текстовой строки, начиная с указанной позиции |
| ПРОПНАЧ (текст) | Первая буква в строке текста и все первые буквы, следующие за знаками, отличными от букв, преобразуются в прописные (верхний регистр). Все прочие буквы в тексте преобразуются в строчные (нижний регистр) |
| ЗАМЕНИТЬ (старый_текст;нач_поз; число_знаков;новый текст) | Функция ЗАМЕНИТЬ замещает указанную часть знаков текстовой строки другой строкой текста |
| ПОВТОР (текст; число_повторений) | Повторяет текст заданное число раз. Функция ПОВТОР используется для заполнения ячейки заданным количеством вхождений текстовой строки |
| ПРАВСИМВ (текст; число_знаков) | Функция ПРАВСИМВ возвращает заданное число последних знаков текстовой строки |
| ПОИСК (искомый_текст; текст_для_поиска; нач позиция) | Функция находит одну текстовую строку внутри второй текстовой строки (без учета регистра) и возвращает номер начальной позиции первой строки, отсчитывая его от первого знака второй строки |
| ПОДСТАВИТЬ (текст; стар_текст; нов_текст; номер_вхождения) | Подставляет значение аргумента «нов_текст» вместо значения аргумента «стар_текст» в текстовой строке. Функция ПОДСТАВИТЬ используется, когда нужно заменить определенный текст в текстовой строке |
| Т (значение) | Возвращает текст, ссылка на который задается аргументом «значение» |
| ТЕКСТ (значение; формат) | Преобразует значение в текст в заданном числовом формате заданном |
| СЖПРОБЕЛЫ (текст) | Удаляет из текста все пробелы, за исключением одиночным пробелов между словами |
| ПРОПИСН (текст) | Делает все буквы в тексте прописным |
| ЗНАЧЕН (текст) | Преобразует строку текста, отображающую число, в число |
Автозамена в Excel 2010. Основы использования
Функция: SUBSTITUTE (ПОДСТАВИТЬ)
Функция SUBSTITUTE (ПОДСТАВИТЬ) заменяет старый текст на новый текст внутри текстовой строки. Функция заменит все повторения старого текста, пока не будет выполнено определённое условие. Она чувствительна к регистру.
Как можно использовать функцию SUBSTITUTE (ПОДСТАВИТЬ)?
Функция SUBSTITUTE (ПОДСТАВИТЬ) заменяет старый текст новым внутри текстовой строки. Вы можете использовать её для того, чтобы:
- Изменять название региона в заголовке отчёта.
- Удалить непечатаемые символы.
- Заменить последний символ пробела.
Синтаксис SUBSTITUTE (ПОДСТАВИТЬ)
Функция SUBSTITUTE (ПОДСТАВИТЬ) имеет вот такой синтаксис:
SUBSTITUTE(text,old_text,new_text,instance_num) ПОДСТАВИТЬ(текст;стар_текст;нов_текст;номер_вхождения)
- text (текст) – текстовая строка или ссылка, где будет осуществлена замена текста.
- old_text (стар_текст) – текст, который надо заменить.
- new_text (нов_текст) – текст, который будет вставлен.
- instance_num (номер_вхождения) – номер вхождения текста, который нужно заменить (не обязательный аргумент).
Замена или удаление неразрывных пробелов
При выгрузке данных из 1С, копировании информации с вебстраниц или из документов Word часто приходится иметь дело с неразрывным пробелом – спецсимволом, неотличимым от обычного пробела, но с другим внутренним кодом (160 вместо 32). Его не получается удалить стандартными средствами – заменой через диалоговое окно Ctrl+H или функцией удаления лишних пробелов СЖПРОБЕЛЫ (TRIM)
. Поможет наша функция
ПОДСТАВИТЬ
, которой можно заменить неразрывный пробел на обычный или на пустую текстовую строку, т.е. удалить:
Поиск или замена текста и чисел на листе
В этом курсе:
Функции поиска и замены в Excel используются для поиска в книге необходимой информации, например определенного числа или текстовой строки. Вы можете найти элемент поиска для справки или заменить его другим. Вы также можете найти ячейки, к которым применен определенный формат.
Чтобы найти текст или числа, нажмите клавиши CTRL + F
или перейдите на вкладку
главная
>
редактирование
>
найти & выберите
>
найти
.
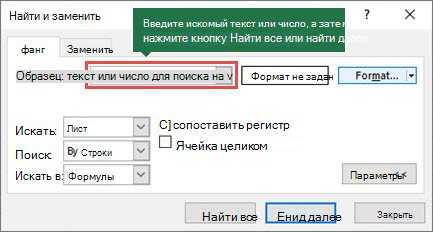
В поле найти
введите текст или числа, которые вы хотите найти, или щелкните стрелку в поле
найти
и выберите в списке последний элемент поиска.
В условиях поиска можно использовать подстановочные знаки, например вопросительный знак (?) и звездочку (*).
Звездочка используется для поиска любой строки знаков. Например, если ввести г*д
, то будут найдены слова «год» и «город».
Вопросительный знак заменяет один любой знак. Например, если ввести г?д
, то будут найдены слова «гад», «гид» и «год».
Совет:
Для поиска на листе звездочек, вопросительных знаков и знаков тильды (
) перед ними следует ввести в поле Найти
знак тильды. Например, чтобы найти данные, содержащие слово «?», введите в качестве условия поиска строку
? . Для ввода тильды нажмите клавиши SHIFT +
, где клавиша тильда обычно находится над клавишей TAB.
Чтобы выполнить поиск, нажмите кнопку найти все
или
Найти далее
.
Совет:
Когда вы нажимаете кнопку
найти все
, выводится каждое вхождение условия, которое вы ищете, и щелчок по определенному вхождению в списке выберет ячейку. Чтобы отсортировать результаты поиска »
найти все
«, щелкните заголовок столбца.
При необходимости нажмите кнопку Параметры
, чтобы дополнительно задать условия поиска.
Для поиска данных на листе или во всей книге выберите в поле Искать
вариант
на листе
или
в книге
.
Для поиска данных в строках или столбцах выберите в поле Просматривать
вариант
по строкам
или
по столбцам
.
Чтобы найти данные с определенными подробностями, в поле Искать в
выберите пункт
формулы
,
значения
,
заметки
или
Примечания
.
Примечание:
Формулы
,
значения
,
заметки
и
Примечания
доступны только на вкладке »
Поиск
«. на вкладке
заменить
доступны только
формулы
.
Для поиска данных с учетом регистра установите флажок Учитывать регистр
.
Для поиска ячеек, содержащих только символы, введенные в поле Найти
, установите флажок
Ячейка целиком
.
Если вы хотите найти текст или числа с определенным форматированием, нажмите кнопку Формат
и выберите необходимые параметры в диалоговом окне
Найти формат
.
Совет:
Чтобы найти ячейки, точно соответствующие определенному формату, можно удалить все условия в поле
Найти
, а затем выбрать ячейку с нужным форматированием в качестве примера. Щелкните стрелку рядом с кнопкой
Формат
, выберите пункт
Выбрать формат из ячейки
, а затем щелкните ячейку с форматированием, которое требуется найти.
Дисперсия выборки
Дисперсия выборки ( выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно среднего .
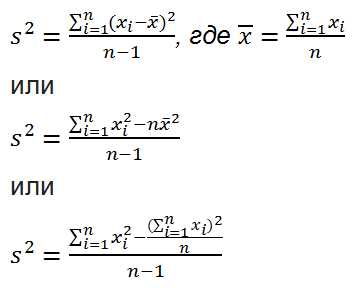
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ) =КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1) – обычная формула =СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1 ) – формула массива
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье Доверительный интервал для оценки дисперсии в MS EXCEL .
Массовая замена слов
Предположим, что нам необходимо заменить все «ул.» на листе на «улица «. Или русское слово «дом» на английское «house». Или еще интереснее: все английские буквы на русские. Например, английская «а» должна быть заменена на русскую «a», английская «c» на русскую «с», английская «H» на русскую «Н» и т.д. А такое тоже нередко бывает и доставляет проблемы. Ведь если в одной таблице будут русские буквы, а в другой английские — то применение большинства встроенных функций поиска(та же ВПР) просто не найдут соответствия. Если подобную замену надо сделать для одного сочетания, то все просто: жмем Ctrl+H и указываем что заменить и на что. Но если таких замен надо сделать 20? Или 120? Это надо будет 120 раз нажать и ввести что заменять и на что. А если это надо сделать еще и не в одном документе — то. Думаю сами справитесь с умножением количества замен на количество файлов, в которых это надо сделать. И вроде бы простая операция превращается в ваш личный ад на работе. Недавно на форуме участнику потребовалось автоматизировать именно такую штуку. Т.к. код несложный — решил написать и чуть дополнив выложить для всех кому код может потребоваться:
Option Explicit Sub Replace_Mass() Dim s As String Dim lCol As Long Dim avArr, lr As Long Dim lLastR As Long Dim lToFindCol As Long, lToReplaceCol As Long, lLookAt As Long ‘запрашиваем направление перевода — с русского на англ. или наоборот lCol = Val(InputBox(«Укажите направление перевода:» & vbNewLine & _ » 1 — ru-en» & vbNewLine & _ » 2 — en-ru», «Запрос», 1)) If lCol = 0 Then Exit Sub ‘запрашиваем по части ячейки искать или по всему тексту ‘по умолчанию — по части lLookAt = Val(InputBox(«Искать соответствие по части ячейки или по всему тексту:» & vbNewLine & _ » 1 — по всему тексту» & vbNewLine & _ » 2 — по части ячейки», «Запрос», 2)) If lLookAt = 0 Then Exit Sub Select Case lCol Case 1 lToFindCol = 1 lToReplaceCol = 2 Case 2 lToFindCol = 2 lToReplaceCol = 1 End Select Application.ScreenUpdating = 0 ‘Получаем с листа Соответствия значения, которые надо заменить в выделенном диапазоне With ThisWorkbook.Sheets(«Соответствия») lLastR = .Cells(.Rows.Count, 1).End(xlUp).Row avArr = .Cells(1, 1).Resize(lLastR, 2) End With ‘заменяем For lr = 1 To UBound(avArr, 1) s = avArr(lr, lToFindCol) If Len(s) Then ‘если значение для замены не пустое Selection.Replace s, avArr(lr, lToReplaceCol), lLookAt End If Next lr Application.ScreenUpdating = 1 End Sub
Как это работает. В книге есть специальный лист с именем «Соответствия». На нем в столбце А записаны слова, которые необходимо заменить, а в столбце В — на что эти слова заменить. Если в столбце А пусто — то замена не будет произведена. Если в столбце В пусто — то значение из столбца А будет просто удалено. Замены производятся исключительно в выделенных на листе ячейках. Ячейки могут быть несмежными.
Итак, необходимо сделать много замен. Скачиваете файл:
Массовая замена слов (54,5 KiB, 6 171 скачиваний)
Примечание: Я сделал файл как переводчик. Т.е. в первом столбце русские слова, во втором английские. Но в столбцах может быть что угодно — хоть слова, хоть символы, хоть числа. На лист «Соответствия» записываете в столбец А — что заменять, в столбец В — на что заменять. Переходите на лист книги, в котором необходимо произвести замену. Выделяете ячейки, значения в которых надо найти и заменить. После чего жмете Alt+F8 и выбираете макрос «Tips_Macro_ReplaceMASS.xls!Replace_Mass»(или просто «Replace_Mass», если код в той же книге, что и ячейки для поиска и замены). Первым появится окно с запросом направления перевода. По умолчанию 1(ru-en). Т.е. будет браться слово из столбца А и заменяться словом из столбца В. Но если указать 2 — то будет браться слово из столбца В и заменяться словом из столбца А. Т.е. аналог переводчика — с рус. на англ. и наоборот. Либо из А в В, либо из В в А. Вторым появится запрос на метод просмотра данных:
- если указать «1 — по всему тексту» — данные из столбца А будут заменять только в том случае, если ячейка в выделенном для замены диапазоне полностью совпадает со значением из столбца А листа «Соответствия». Например, в любой из выделенных ячеек записано «На столе книга», а на листе «Соответствия» в столбце А есть только слово «книга». Замена не будет произведена, т.к. необходимо, чтобы в столбце А было так же «На столе книга».
- если указать «2 — по части ячейки» — данные из столбца А будут заменять в случае, если ячейка в выделенном для замены диапазоне содержит любое слово из столбца А листа «Соответствия». На том же примере — «На столе книга». Если выбрать 2, то в тексте «На столе книга» слово книга будет заменено на слово из столбца В — «book».
И еще один практический пример чуть модифицированного кода. Предположим, имеется таблица выручки по реализации продукции:
Как видно, здесь присутствую только номера статей, но нет их расшифровки. Зато расшифровка есть в отдельном листе «Справочник»:
Как видно, в справочнике присутствуют нужные номера статей и можно было бы применить ту же ВПР(VLOOKUP) для замен. Если бы не одно но: в таблице по реализации помимо номеров статьей есть еще лишний текст «Статья затрат:». Конечно, можно сначала заменить этот текст, потом в отдельном столбце применить ВПР, заменить формулу значениями и вернуть в исходный столбец. Если при этом надо еще оставить текст «Статья затрат:», то надо будет сделать еще доп.манипуляции либо при составлении формулы, либо после. В любом случае — слишком много лишних телодвижений. А значит бОльшие времязатраты. Приложенный ниже файл поможет сделать это в разы быстрее: Скачать файл с примером и кодом:
Массовая замена слов — статьи.xls (91,5 KiB, 1 413 скачиваний)
и в итоге за пару секунд получим следующий результат:
Достаточно выделить столбец со статьями на листе с реализацией и запустить код(либо нажатием кнопки заменить значения, либо нажав
Alt+F8 и выбрав из списка макросов макрос Replace_Mass ). После нажатия на кнопку будут запрошены следующие параметры:
- указать номер столбца значений в листе «Справочник», в котором искать соответствия номерам статей(в нашем случае это столбец 1(А))
- указать номер столбца, значениями которого заменять найденные в таблице реализации значения(это может быть один из трех столбцов справочника: Группа затрат, Статья затрат, Подстатьи затрат). Логичнее всего указать столбец 4, т.к. он наиболее детализирован и конкретнее указывает расшифровку статьи
- далее будет предложено указать точность поиска:
- если указать » 1 — по всему тексту » — данные будут заменены только в том случае, если значение ячейки в выделенном для замены диапазоне полностью совпадает со значением из столбца А листа «Справочник». Т.е. если бы у нас в таблице реализации был бы записан только номер статьи(1.01), тогда можно было бы указать именно 1
- если указать » 2 — по части ячейки » — данные будут заменены только в том случае, если значение ячейки в выделенном для замены диапазоне содержит любое значение из столбца А листа «Справочник». Это больше подходит к описанному случаю, т.к. нам необходимо заменить исключительно номер статьей на их расшифровку, оставив при этом текст «Статья затрат: «
Если все указано корректно, то на листе будут произведены все необходимые замены. Возможные ошибки, которые предусмотрены кодом и о которых будет сообщено соответствующим сообщением(код прервется, замены не будут произведены):
- на листе Справочник нет значений
- в качестве столбца для поиска значений и для замены значений на листе Справочник указано одно и то же число
- в качестве столбца значений для замены указано число, превышающее общее количество столбцов на листе Справочник
Особое внимание хочу уделить случаю, когда выбирается замена по части ячейки. В этом случае лучше список на листе Справочник отсортировать по длине текста по тому столбцу, в котором будут значения для поиска. Зачем это надо: т.к. значение по части ячейки будет заменять не полное соответствие, то есть вероятность неверных замен. Например, есть текст «Статья затрат: 1.011» . В то же время на листе Справочник есть статьи «1.01» и «1.011» . Т.к. «1.01» идет раньше в большинстве случаев, то текст будет заменен некорректно: «Статья затрат: ТВ 1 » . Чтобы получить длину строки текста можно использовать функцию ДЛСТР(LEN): =ДЛСТР( A2 ) =LEN(A2)
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее функцию распределения .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна математическому ожиданию квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
Если случайная величина имеет дискретное распределение , то дисперсия вычисляется по формуле:
где x i – значение, которое может принимать случайная величина, а μ – среднее значение ( математическое ожидание случайной величины ), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет непрерывное распределение , то дисперсия вычисляется по формуле:
где р(x) – плотность вероятности .
Для распределений, представленных в MS EXCEL , дисперсию можно вычислить аналитически, как функцию от параметров распределения. Например, для Биномиального распределения дисперсия равна произведению его параметров: n*p*q.
Примечание : Дисперсия, является вторым центральным моментом , обозначается D[X], VAR(х), V(x). Второй центральный момент – числовая характеристика распределения случайной величины, которая является мерой разброса случайной величины относительно математического ожидания .
Примечание : О распределениях в MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х – случайная величина, а – константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2 )-E(2*X*E(X))+(E(X)) 2 =E(X 2 )-2*E(X)*E(X)+(E(X)) 2 =E(X 2 )-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y – случайные величины, Cov(Х;Y) – ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе стандартной ошибки среднего .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения доверительного интервала для разницы 2х средних .
Определение метода Range.Replace
Range.Replace – это метод, который находит по шаблону подстроку в содержимом ячеек указанного диапазона, заменяет ее на другую подстроку и возвращает значение типа Boolean.
Метод имеет некоторые особенности, которые заключаются в следующем:
- при присвоении булева значения, возвращаемого методом Range.Replace, переменной, необходимо список параметров (аргументов) метода заключать в круглые скобки;
- если метод используется без присвоения возвращаемого значения переменной, параметры должны быть указаны без заключения их в круглые скобки.
Стандартное отклонение выборки
Стандартное отклонение выборки – это мера того, насколько широко разбросаны значения в выборке относительно их среднего .
По определению, стандартное отклонение равно квадратному корню из дисперсии :
Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) – отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ) =КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Ренат, огромное спасибо за «Ctrl+J » — я так долго искала, как указать знак переноса в «Найти». Не поленилась написать сообщение, чтобы сказать еще раз спасибо ))
Согласен, хороший трюк, сам пользуюсь)
Спасибо огромное. Ctrl+j — это меша круто! !
Как найти и заменить масив данных к примеру из базы в 200 000 вычистить одно
Как найти и заменить массив данных, к примеру из базы в 200 000 вычистить одной операцией 2 000 контактов?
Спасибо большое! Нигде больше не мог найти описание, что это именно Ctrl+J!
Ctrl+J спас меня.
Добрый день! А не подскажете ли, как найти (и выделить) пустой текст в ячейке? Объясню, чего хочу. В одном файле формулой обрабатываются штрих-коды, в текстовом формате, так как код больше 13 символов. При копировании в другой файл на месте отсутствующих штрих-кодов вставляется пустой текст «». О не видим и в ячейке никак не отображается. Для выгрузки в 1С нужно такие ячейки очистить.
Всем привет, такие вопросы по Эксель: 1. ФИО в нашей базе записано в одну стороку, как разбить на три отдельных, не потеряв данные. 2. Телефон в столбце, имеет разные форматы, пример: 375 29 123456, 8029-223456, 375-29-123456. Как привести в один правильный порядок: +37529123456. Спасибо за ответы.
Андрей, нужно выделить столбец с ФИО, нажать вкладку «данные» на ПИ, «текст по столбцам», «фиксированной ширины», несколько раз «далее», готово!!
Здравствуйте, Я смотрел Ваше руководство по вопросу найти определенное слово в Excel. У меня возникла одна задача и есть к Вам вопрос. А можно это слово которое ищешь по тексту в Excel затем, как нашел все варианты, заменить их на такое же самое слово, но только что бы оно было полужирным курсивом выделено по всей таблице. Я пытался так сделать с помощью найти и заменить, но оно заменяет на жирный формать весь текст, а не заданое слово. Что Вы мне посоветуете? Спасибо Вам зарание
Примеры использования СТАНДОТКЛОН.В, СТАНДОТКЛОН.Г, СТАНДОТКЛОНА и СТАНДОТКЛОНПА
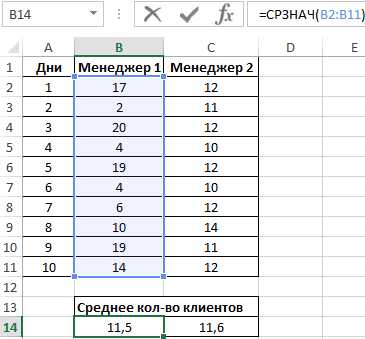
Пример 1. На предприятии работают два менеджера по привлечению клиентов. Данные о количестве обслуженных клиентов в день каждым менеджером фиксируются в таблице Excel. Определить, какой из двух сотрудников работает эффективнее.
Таблица исходных данных:
Вначале рассчитаем среднее количество клиентов, с которыми работали менеджеры ежедневно:
=СРЗНАЧ(B2:B11)
Данная функция выполняет расчет среднего арифметического значения для диапазона B2:B11, содержащего данные о количестве клиентов, принимаемых ежедневно первым менеджером. Аналогично рассчитаем среднее количество клиентов за день у второго менеджера. Получим:
На основе полученных значений создается впечатление, что оба менеджера работают примерно одинаково эффективно. Однако визуально виден сильный разброс значений числа клиентов у первого менеджера. Произведем расчет стандартного отклонения по формуле:
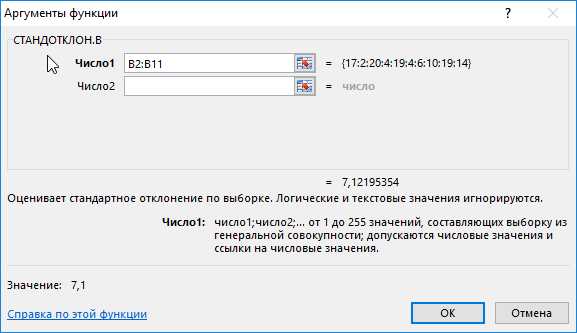
=СТАНДОТКЛОН.В(B2:B11)
B2:B11 – диапазон исследуемых значений. Аналогично определим стандартное отклонение для второго менеджера и получим следующие результаты:
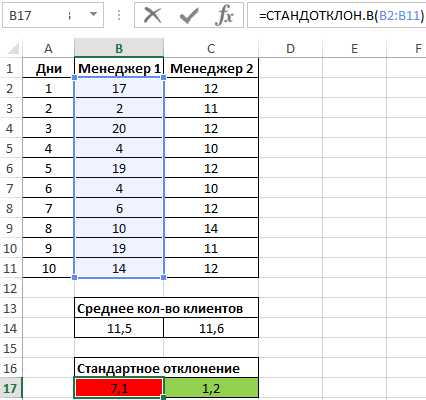
Как видно, показатели работы первого менеджера отличаются высокой вариабельностью (разбросом) значений, в связи с чем среднее арифметическое значение абсолютно не отражает реальную картину эффективности работы. Отклонение 1,2 свидетельствует о более стабильной, а, значит, и эффективной работе второго менеджера.
Метод 6: системные настройки
И напоследок, рассмотрим еще один метод, который схож с тем, который описан выше, но предполагает изменение настроек не Эксель, а операционной системы Windows.
- Заходим в Панель управления любым удобным способом. Например, это можно сделать через Поиск, набрав нужное название и выбрав найденный вариант.
- Настраиваем просмотр в виде мелких или крупных значков, после чего щелкаем по разделу “Региональные стандарты”.
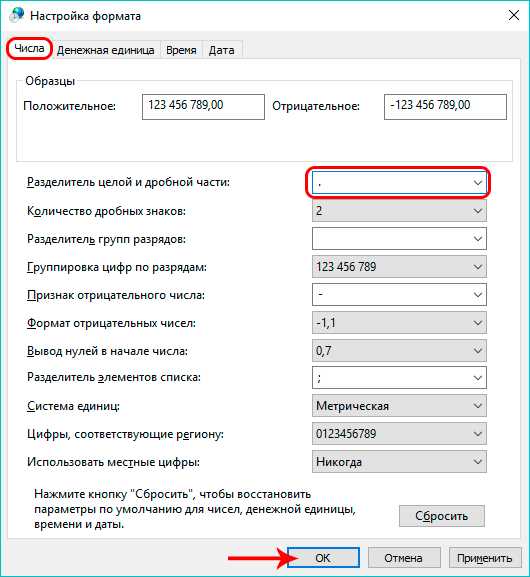
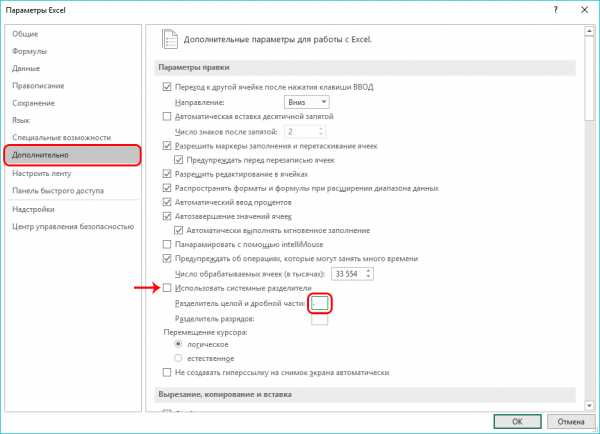
- Появится окно настроек региона, в котором, находясь во вкладке “Форматы” щелкаем по кнопке “Дополнительные настройки”.
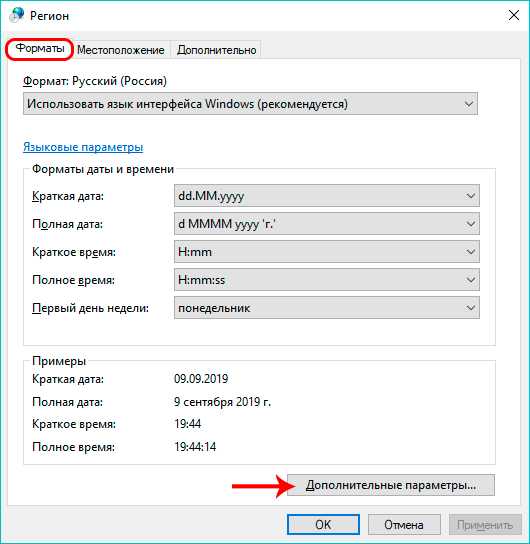
- В появившемся следом окне с настройками формата видим параметр “Разделитель целой и дробной части” и значение, установленной для него. Вместо запятой пишем точку и нажимаем OK.
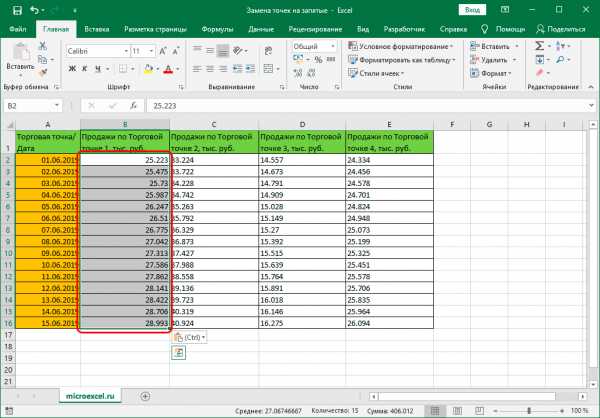
- Аналогично рассмотренному выше пятому методу, производим копирование данных из Excel в Блокнот и обратно.
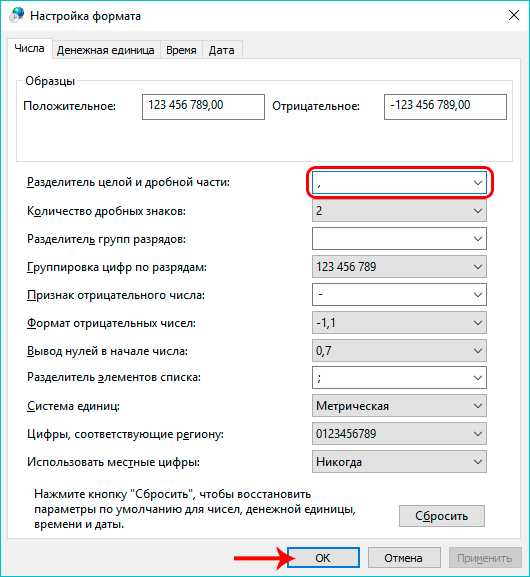
- Возвращаем настройки формата в исходное положение. Данное действие критически важно, так как противном случае возможны ошибки в работе других программ и утилит.
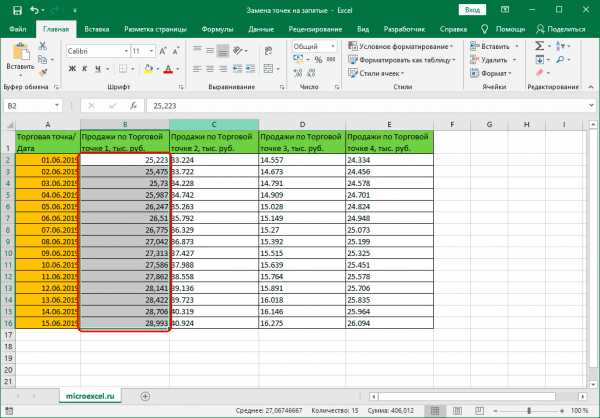
- Все точки в столбце, над которым мы работали, автоматически заменились на запятые.
Пример использования функции СТАНДОТКЛОНА в Excel
Пример 2. В двух различных группах студентов колледжа проводился экзамен по одной и той же дисциплине. Оценить успеваемость студентов.
Таблица исходных данных:
Определим стандартное отклонение значений для первой группы по формуле:
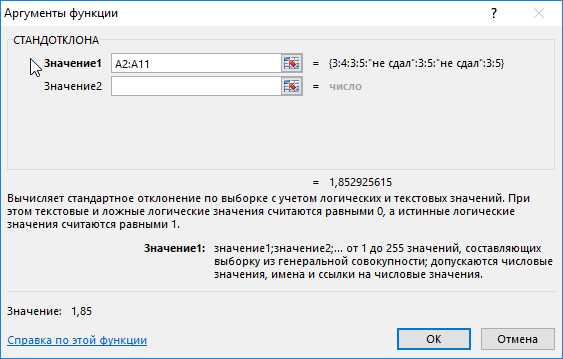
=СТАНДОТКЛОНА(A2:A11)
Аналогичный расчет произведем для второй группы. В результате получим:
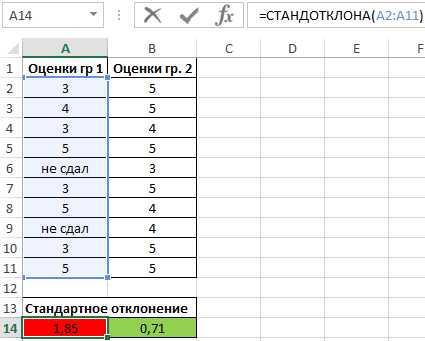
Полученные значения свидетельствуют о том, что студенты второй группы намного лучше подготовились к экзамену, поскольку разброс значений оценок относительно небольшой. Обратите внимание на то, что функция СТАНДОТКЛОНА преобразует текстовое значение «не сдал» в числовое значение 0 (нуль) и учитывает его в расчетах.
Microsoft Excel. Как в Экселе найти и заменить?
Эта функция в Экселе точно такая же как в Ворде. Необходимо вызвать функцию поиска (Contrl + F) в строке «Найти» ввести искомое слово а в строке «Заменить» ввести нужное слово и нажать «заменить». Если искомое слово не одно а несколько раз повторяется то можно нажать «заменить все»
То, что спрашивается в этом вопросе делается очень легко, последовательность не отличается от Ворда.
Первым делом нажимаем на «Ctrl» + «F», есть и другой вариант, но это более быстрый.
Заходим на второе окно «Заменить», теперь в строке «Найти» пишем слово, которое нужно найти, а в графе «Заменить на» пишем слово на которое будем менять искомое значение.
Как видно выше все достаточно очень просто.
Хочет также рассказать о том, что если выделить определенный столбец или строку, или, например, группу столбцов и сток, то искать Эксель и соответственно заменять искомое значение будет непосредственно в этом выделенном диапазоне.
В Microsoft Excel поиск нужного слова и его замену можно осуществить двумя способами. Легче воспользоваться горячим клавишами, которые привязаны к функции поиска — Ctrl + F. Набираем ее с клавиатуры и получаем следующее окно.
Вводим в окне Заменить нужное слово, ниже — вариант его замены и подтверждаем действие. Или просто ищем слово в разделе Найти и меняем его вручную.
Второй вариант — найти нужную кнопку в меню. Она находится в меню Главная — Редактирование. Кнопка скрыта, обычно отображается лишь кнопка Найти и выделить. Нажимаем на небольшую стрелочку под кнопкой и из появившегося меню выбираем пункт Заменить. И попадаем в аналогичное меню.
Функция ПОДСТАВИТЬ() vs ЗАМЕНИТЬ()
Пусть в ячейке А2 введена строка Продажи (январь) . Чтобы заменить слово январь , на февраль , запишем формулы:
=ЗАМЕНИТЬ(A2;10;6;”февраль”) =ПОДСТАВИТЬ(A2; “январь”;”февраль”)
т.е. для функции ЗАМЕНИТЬ() потребовалось вычислить начальную позицию слова январь (10) и его длину (6). Это не удобно, функция ПОДСТАВИТЬ() справляется с задачей гораздо проще.
Кроме того, функция ЗАМЕНИТЬ() заменяет по понятным причинам только одно вхождение строки, функция ПОДСТАВИТЬ() может заменить все вхождения или только первое, только второе и т.д. Поясним на примере. Пусть в ячейке А2 введена строка Продажи (январь), прибыль (январь) . Запишем формулы: =ЗАМЕНИТЬ(A2;10;6;”февраль”) =ПОДСТАВИТЬ(A2; “январь”;”февраль”) получим в первом случае строку Продажи (февраль), прибыль (январь) , во втором – Продажи (февраль), прибыль (февраль) . Записав формулу =ПОДСТАВИТЬ(A2; “январь”;”февраль”;2) получим строку Продажи (январь), прибыль (февраль) .
Кроме того, функция ПОДСТАВИТЬ() может работает с учетом регистра, а ЗАМЕНИТЬ() по понятным причинам не может.
Замена нескольких значений на несколько
Эта задача более сложная, чем замена на одно значение. Как ни странно, функция «ЗАМЕНИТЬ» здесь не подходит — она требует явного указания позиции заменяемого текста. Зато может помочь функция «ПОДСТАВИТЬ».
Массовая замена с помощью функции «ПОДСТАВИТЬ»
Используя несколько условий в сложной формуле, можно производить одновременную замену нескольких значений. Excel позволяет использовать до 64 уровней вложенности — свобода действий высока. Например, вот так можно перевести кириллицу в латиницу:
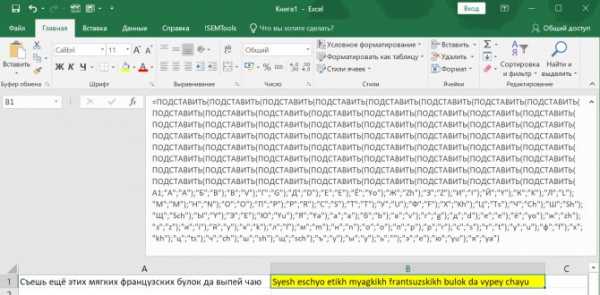
При этом, если использовать в качестве подставляемого фрагмента пустоту, можно использовать функцию для удаления нескольких символов — смотрите как удалить цифры из ячейки этим способом.
Но у решения есть и свои недостатки:
- Функция ПОДСТАВИТЬ регистрозависимая, что заставляет при замене одного символа использовать два его варианта — в верхнем и нижнем регистрах. Хотя, в некоторых случаях, как пример на картинке выше, это и преимущество.
- максимум 64 замены — хоть и много, но все же ограничение.
- формально процедура замены таким способом будет происходить массово и моментально, однако, длительность написания таких формул сводит на нет это преимущество. За исключением случаев, когда они будут использоваться многократно.
Файл-шаблон с формулой множественной замены
Вместо явного прописывания заменяемых паттернов в формуле, можно использовать внутри формулы ссылки на ячейки, значения в которых можно прописывать на свое усмотрение. Это сократит время, т.к. не требует редактирования сложной формулы.
Файл доступен по ссылке, но можно и не скачивать его, а просто скопировать текст формулы ниже и вставить ее в любую ячейку, кроме диапазона A1:B64. Формула заменяет в ячейке C1 значения в столбце A стоящими напротив в столбце B.
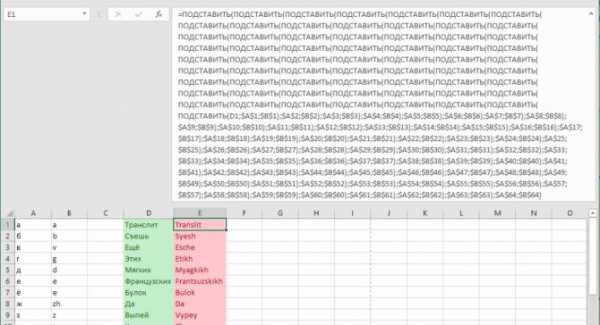
Формула в файле-шаблоне для множественной замены на примере транслитерации
А вот и она сама (тройной клик по любой части текста = выделить всю формулу). Обращается к ячейке D1, делая 64 замены по правилам, указанным в ячейках A1-B64. При этом в столбцах можно удалять значения — это не нарушит ее работу.
Функция ПОДСТАВИТЬ при условии подставляет значение
Пример 1. В результате расчетов, произведенных в некотором приложении, были получены некоторые значения, записанные в таблицу Excel. Некоторые величины рассчитать не удалось, и вместо числового представления была сгенерирована ошибка “NaN”. Необходимо заменить все значения “NaN” на число 0 в соответствующих строках.
Таблица данных:
Для замены и подстановки используем рассматриваемую формулу в качестве массива. Вначале выделим диапазон ячеек C2:C9, затем введем формулу через комбинацию Ctrl+Shift+Enter:
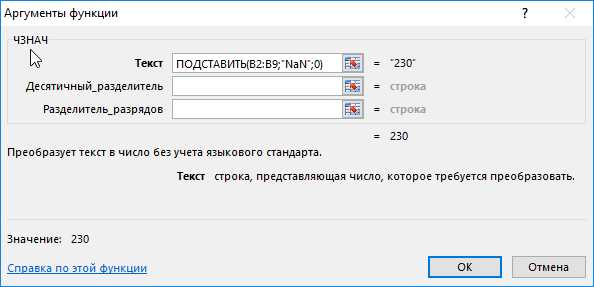
Функция ЧЗНАЧ выполняет преобразование полученных текстовых строк к числовым значениям. Описание аргументов функции ПОДСТАВИТЬ:
- B2:B9 – диапазон ячеек, в которых требуется выполнить замену части строки;
- “NaN” – фрагмент текста, который будет заменен;
- 0 – фрагмент, который будет вставлен на место заменяемого фрагмента.
Для подстановки значений во всех ячейках необходимо нажать Ctrl+Shift+Enter, чтобы функция была выполнена в массиве. Результат вычислений:
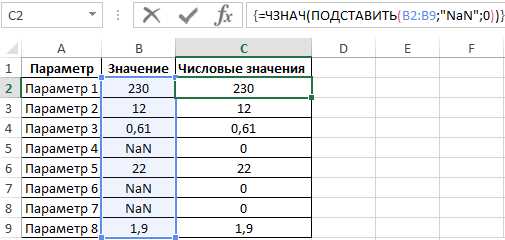
Таким же образом функция подставляет значения и другой таблицы при определенном условии.
Метод 5: настройка параметров Эксель
Реализуя этот метод, нам нужно изменить определенные настройки программы.
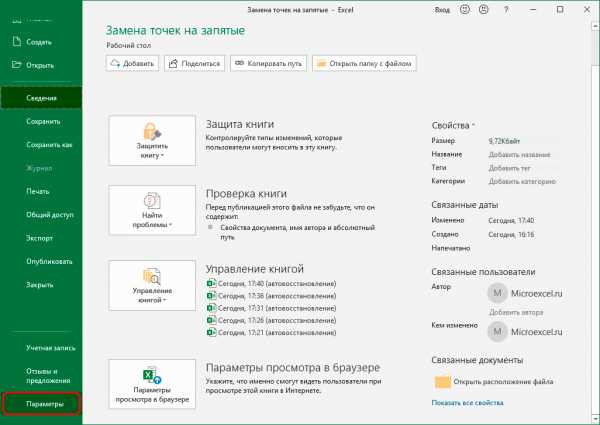
- Заходим в меню “Файл”, где щелкаем по разделу “Параметры”.
- В параметрах программы в перечне слева кликаем по разделу “Дополнительно”. В блоке настроек “Параметры правки” убираем флажок напротив опций “Использовать системные разделители”. После этого активируются поля для ввода символов в качестве разделителей. В качестве разделителя целой и дробной части пишем символ “.” (точка) и сохраняем настройки нажатием кнопки OK.
- Визуальных изменений в таблице не произойдет. Поэтому движемся дальше. Для этого копируем данные и вставляем их в Блокнот (рассмотрим на примере одного столбца).
- Выделяем данные из Блокнота и вставляем обратно в таблице Эксель в том же самое месте, откуда скопировали их. При этом выравнивание данных сменилось с левого края на правый. Это означает то, что теперь программа эти значения воспринимает как числовые.
- Снова заходим в параметры программы (раздел “Дополнительно”), где возвращаем флажок напротив пункта “Использовать системные разделители” на место и нажимаем кнопку OK.
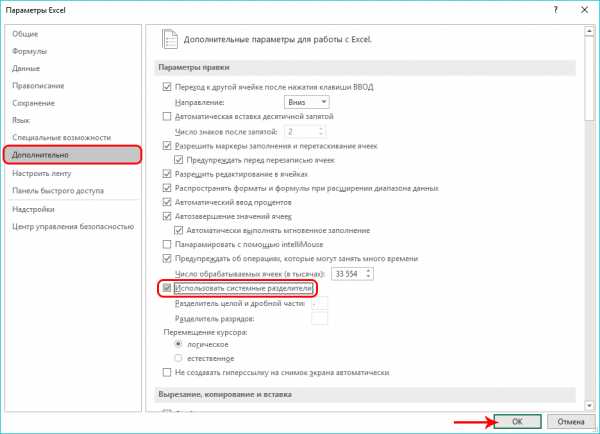
- Как видим, точки были автоматически заменены программой на запятые. Не забываем сменить формат данных на “Числовой” и можно работать с ними дальше.
Автозамена значения в текстовых ячейках с помощью функции ПОДСТАВИТЬ
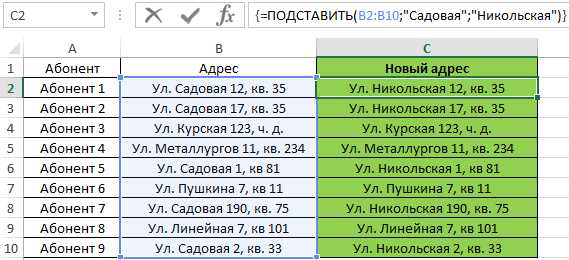
Пример 2. Провайдер домашнего интернета хранит данные о своих абонентах в таблице Excel. Предположим, улица Садовая была переименована в Никольскую. Необходимо быстро произвести замену названия улицы в строке данных об адресе проживания каждого клиента.
Таблица данных:
Для выполнения заданного условия используем формулу:
Примечание: в данном примере ПОДСТАВИТЬ также используется в массиве Ctrl+Shift+Enter.
В результате получим:
Источники
- https://office-guru.ru/excel/30xl30d-podstavit-substitute-157.html
- https://www.planetaexcel.ru/techniques/7/2775/
- https://excel2.ru/articles/funkciya-sovpad-v-ms-excel-sovpad
- https://excel2.ru/articles/dispersiya-i-standartnoe-otklonenie-v-ms-excel
- https://exceltable.com/funkcii-excel/primery-funkciy-standotklon
- https://excel2.ru/articles/funkciya-podstavit-v-ms-excel-podstavit
- https://excelhack.ru/funkciya-substitute-podstavit-v-excel/
- https://exceltable.com/funkcii-excel/primer-funkcii-podstavit
Редактируем словарь автозамены
Как мы уже ранее упомянули, цель автозамены – помощь в исправлении допущенных ошибок или опечаток. В программе изначально предусмотрен стандартный список соответствий слов и символов для выполнения замены, однако, у пользователя есть возможность добавить свои варианты.
- Снова заходим в окно с параметрами автозамены, руководствуясь шагами, описанными выше (меню “Файл” – раздел “Параметры” – подраздел “Правописание” – кнопка “Параметры автозамены”).
- В поле “Заменять” пишем символ (слово), которое в дальнейшем будет идентифицироваться программой как ошибка. В поле “На” указываем значение, которое будет использоваться в качестве замены. По готовности нажимаем кнопку “Добавить”.
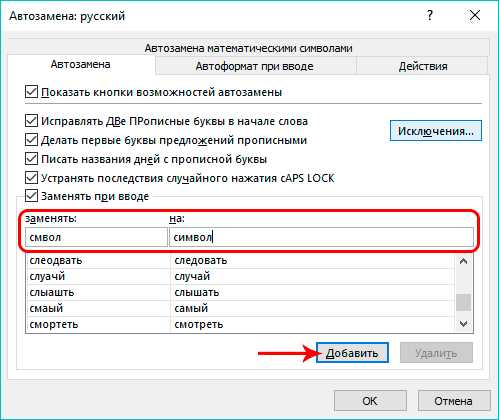
- В итоге мы можем добавить в этот словарь все самые распространенные опечатки и ошибки, совершаемые нами (если их нет в исходном списке), чтобы не тратить время на их дальнейшее исправление.
Атозамена математическими символами
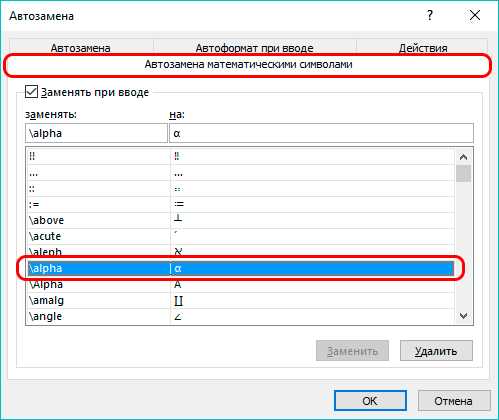
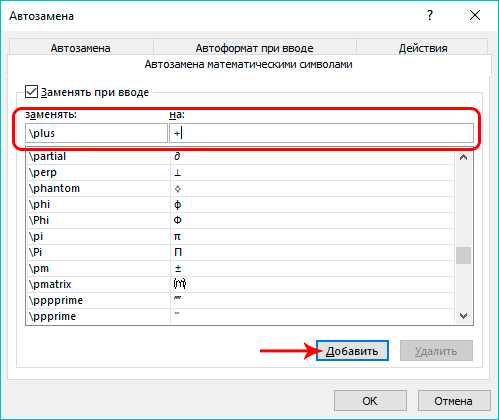
Переходим в одноименную вкладку в параметрах автозамены. Здесь мы найдем перечень значений, которые будут заменяться программой на математические символы. Данная опция крайне полезна, когда нужно ввести знак, которого нет на клавиатуре. Например, чтобы ввести символ “α” (альфа), достаточно будет набрать “\alpha”, после чего программа вместо данное значения подставить требуемый символ. Подобным образом вводятся и другие символы.
Также, в этот список можно добавить свои варианты.
Удаление сочетания из автозамены
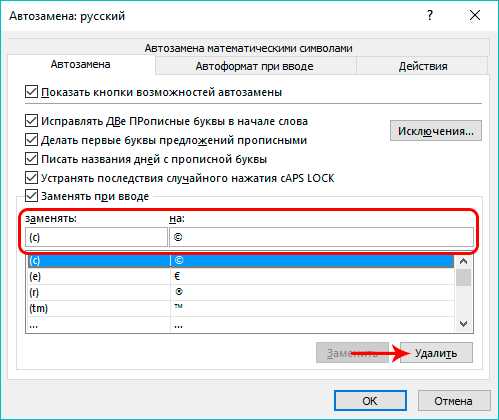
Чтобы удалить из списка автозамен ненужное сочетание слов или символов, просто выделяем его кликом мыши, после чего нажимаем кнопку “Удалить”.
Также, выделив определенное соответствие, вместо того, чтобы его удалить, можно просто скорректировать одно из его полей.
Поиск нестрогого соответствия символов
Иногда пользователь не знает точного сочетания искомых символов что существенно затрудняет поиск. Данные также могут содержать различные опечатки, лишние пробелы, сокращения и пр., что еще больше вносит путаницы и делает поиск практически невозможным. А может случиться и обратная ситуация: заданной комбинации соответствует слишком много ячеек и цель поиска снова не достигается (кому нужны 100500+ найденных ячеек?).
Для решения этих проблем очень хорошо подходят джокеры (подстановочные символы), которые сообщают Excel о сомнительных местах. Под джокерами могут скрываться различные символы, и Excel видит лишь их относительное расположение в поисковой фразе. Таких джокеров два: звездочка «*» (любое количество неизвестных символов) и вопросительный знак «?» (один «?» – один неизвестный символ).
Так, если в большой базе клиентов нужно найти человека по фамилии Иванов, то поиск может выдать несколько десятков значений. Это явно не то, что вам нужно. К поиску можно добавить имя, но оно может быть внесено самым разным способом: И.Иванов, И. Иванов, Иван Иванов, И.И. Иванов и т.д. Используя джокеры, можно задать известную последовательно символов независимо от того, что находится между. В нашем примере достаточно ввести и*иванов и Excel отыщет все выше перечисленные варианты записи имени данного человека, проигнорировав всех П. Ивановых, А. Ивановых и проч. Секрет в том, что символ «*» сообщает Экселю, что под ним могут скрываться любые символы в любом количестве, но искать нужно то, что соответствует символам «и» + что-еще + «иванов». Этот прием значительно повышает эффективность поиска, т.к. позволяет оперировать не точными критериями.
Создание пользовательских функций в Excel
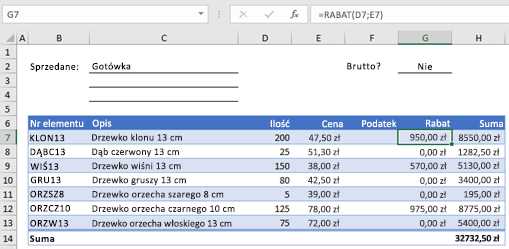
Теперь вы можете использовать новую функцию СКИДКА. Закройте редактор Visual Basic, выберите ячейку G7 и введите следующую команду:
.= СКИДКА (D7; E7)
Excel вычисляет 10-процентную скидку для 200 единиц по цене 47,50 долларов США за единицу и возвращает 950,00 долларов США.
Первая строка кода VBA указывает, что функция СКИДКА (количество, цена) указывает, что функция СКИДКА требует два аргумента: количество и цена. При вызове функции в ячейке рабочего листа эти два аргумента должны быть включены. В формуле = СКИДКА (D7, E7) количество равно аргументу количества, а E7 аргументу цене. Теперь вы можете скопировать формулу СКИДКА в G8: G13, чтобы получить результаты, как показано ниже.
Давайте посмотрим, как выполнить эту функцию в Excel. Когда вы нажимаете клавишу Enter , , Excel ищет имя СКИДКА в текущей книге и находит эту пользовательскую функцию в модуле VBA.Имена аргументов в скобках , количество и цена являются заполнителями для значений, на которых основан расчет скидки.
Инструкция If в следующем блоке кода проверяет количество аргументов и определяет, больше или равно ли количество проданных товаров 100:
Если количество> = 100 Тогда СКИДКА = количество * цена * 0,1 Еще СКИДКА = 0 Конец, если
Если количество проданных товаров больше или равно 100, VBA выполняет следующую инструкцию, умножает значение количества на значение цены, а затем умножает результат на 0,1:
Скидка = количество * цена * 0.1
Результат сохраняется как переменная Скидка . Инструкция VBA, которая сохраняет значение в переменной, называется оператором присваивания, потому что она оценивает выражение справа от знака равенства и присваивает результат имени переменной слева. Переменная Скидка имеет то же имя , что и процедура функции, поэтому значение, хранящееся в переменной, возвращается в формулу рабочего листа с именем ФУНКЦИЯ.СКИДКА.
Если число на меньше 100, VBA выполняет следующие операторы:
Скидка = 0
Наконец, следующий оператор округляет значение, присвоенное переменной Скидка , до двух знаков после запятой:
Скидка = Заявка.Раунд (Скидка, 2)
VBA не имеет функции ON, но Excel работает. Таким образом, использование функции ROUND в этом операторе требует, чтобы функция VBA искала метод (функцию) Round в объекте Application (Excel). Вы можете сделать это, добавив слово Application перед словом Round. Используйте этот синтаксис всякий раз, когда вы хотите получить доступ к Excel из модуля VBA.
.КАК: заменить данные функцией ПОДСТАВИТЬ в Excel
REPLACE Эта функция может заменить существующие слова, текст или символы новыми данными. Примеры использования функций включают удаление непечатаемых символов из импортированных данных, замену ненужных символов пробелами и создание разных версий одного и того же рабочего листа.
01 из 03Синтаксис функции ПОДСТАВИТЬ
Синтаксис функции замены и аргументы
Синтаксис функции относится к макету функции и включает имя функции, круглые скобки и аргументы.Синтаксис функции ЗАМЕНИТЬ :
= ПОДСТАВИТЬ (текст, старый_текст, новый_текст, количество_видов)
Аргументы функции следующие:
Текст: (обязательно) данные, содержащие заменяемый текст. Этот аргумент может быть
- Фактические данные, заключенные в кавычки - вторая строка на картинке выше.
- Ячейка, которая ссылается на расположение текстовых данных на листе — третья строка выше.
Old_text: (обязательно) текст для замены.
New_text: (обязательно) текст, который заменит Old_text .
Номер_экземпляра: (необязательно) номер.
- Если опущено, каждый экземпляр Old_text заменяется на New_text .
- Если включено, заменяется только указанный экземпляр Old_text , например первый или третий экземпляр, как показано в строках 5 и 6 выше.
Аргументы для REPLACE Функция чувствительна к регистру, что означает, что данные, введенные в файл Old_text аргумент, не имеют того же регистра, что и данные в ячейке аргумента Text , подстановка не происходит.
Продолжить чтение ниже
02 из 03Использование функции ПОДСТАВИТЬ
Хотя можно ввести всю формулу в ячейку рабочего листа вручную, другой вариант — использовать Мастер формул , как описано в следующих шагах, вводя функцию и ее аргументы в ячейку, например B3.
= ПОДСТАВИТЬ (A3, «Продажи», «Доход»)
Преимущество использования построителя формул заключается в том, что Excel разделяет каждый аргумент запятой и заключает старые и новые текстовые данные в кавычки.
- Щелкните ячейку B3 , чтобы стать активной ячейкой.
- Нажмите на вкладку меню ленты Formulas .
- Щелкните значок Text на ленте, чтобы открыть меню «Текстовые функции».
- Нажмите REPLACE в списке, чтобы вызвать мастер формул .
- Нажмите на строку Text .
- Щелкните ячейку A3 , чтобы ввести ссылку на эту ячейку.
- Нажмите на строку Old_text .
- Введите Поворот , который является текстом, который мы хотим заменить - нет необходимости заключать текст в кавычки.
- Нажмите на строку New_text .
- Введите Доход как текст для замены.
- Экземпляр Аргумент пуст, поскольку слово Revolutions встречается только один раз в ячейке A3 .
- Нажмите Готово для завершения этой функции.
- Текст Отчет о доходах должен появиться в ячейке B3.
Продолжить чтение ниже
03 из 03ПОДСТАВИТЬ или ЗАМЕНИТЬ Особенности
REPLACE отличается от REPLACE Эта функция используется для замены указанного текста в любом месте выбранных данных, в то время как REPLACE предназначена для замены любого текста, который встречается в указанном месте данных.
.Функция ПОИСКПОЗ Excel - Avendi
MS OfficeФункция ПОИСКПОЗ находит первое вхождение значения, которое соответствует заданному (искомому) тексту или числу в заданном массиве.
Используйте его, если вы хотите узнать позицию заданного значения в диапазоне, а не содержимое конкретной ячейки. Функция возвращает позицию значения, найденного внутри массива, а не само значение.
Функция не различает прописные и строчные буквы.
Если искомое значение не найдено, функция возвращает ошибку #Н/Д!
В английской версии Excel функция называется ПОИСКПОЗ.
Аргументы функции:
искомое_значение - значение, которое мы ищем внутри указанного массива. Искомое значение может быть текстом, числом или логическим значением. Способ сравнения искомого значения с элементами массива определяется последним аргументом функции, т.е. типом_сравнения.
Search_tab — непрерывный диапазон ячеек, в которых мы ищем значение, указанное в lookup_value
compare_type — это необязательный аргумент.Если его опустить, то значением по умолчанию будет 1. Этот аргумент может принимать значения -1, 0, 1. Они означают соответственно:
- 1 - функция найдет наибольшее значение, меньшее или равное искомое значение. Значения в искомом массиве должны быть отсортированы по возрастанию.
Пример 1: искомое значение равно 3. Искомый массив с данными: 1,2,3,4. Найдено значение 3. Результатом является значение 3. Это позиция, в которой находится искомая тройка. Пример 2: искомое значение равно 3. Искомый массив с данными: 1,2,4,5. В массиве нет значения 3. Значит, будет найдено значение 2 (это наибольшее значение, меньшее искомого). Выход устанавливается на 2. Это позиция, в которой находятся найденные два.
- 0 - функция найдет первое значение, точно равное искомому значению. Значения в искомом массиве не нужно сортировать.
Если мы выбираем тип сравнения 0 и искомое значение является текстом, мы можем использовать звездочку (*) и вопросительный знак (?) Заполнители
- -1 - функция находит наименьшее значение, большее или равное искомое значение.Значения в искомом массиве должны быть отсортированы по убыванию
Пример 1: искомое значение равно 3. Искомый массив с данными: 4,3,2,1. Найдено значение 3. Результатом является значение 2. Это позиция, в которой находится искомая тройка. Пример 2: искомое значение равно 3. Искомый массив с данными: 5,4,2,1. В массиве нет значения 3. Следовательно, будет найдено значение 4 (это наименьшее значение больше искомого).Результат устанавливается равным 2. Это позиция, в которой находится четыре.
Вы можете вложить ПОИСКПОЗ() в функцию ИНДЕКС(). Это позволяет:
- получить значение также слева или выше диапазона поиска. Вы не можете сделать это с функциями ВПР() и ГПР(). Функция ВПР() позволяет извлекать значения только справа, а функция ГПР() только ниже искомого диапазона
- одновременный горизонтальный и вертикальный поиск
Пример 1 В приведенном ниже примере мы хотим создать поисковую систему — после ввода названия продукта и месяца должна отображаться стоимость продаж для выбранного продукта и месяца.В примере ищем стоимость продажи яблочного продукта в марте:
Решаем задачу следующим образом:
- используем функцию ПОИСКПОЗ() и находим позицию продукта. Для этого: в качестве значения выберите товар (значение из ячейки А245), искомый массив представляет собой диапазон ячеек, содержащих товары (от А239 до А242), в аргументе «тип_сравнения» введите значение 0.
- .ITEM() и найти, где находится месяц. Для этого: в качестве искомого значения выберите месяц (значение из ячейки B245), искомый массив представляет собой диапазон ячеек, содержащих месяцы (от B238 до F238), в аргументе «тип_сравнения» введите значение 0.
- . В этой функции первым аргументом является массив для поиска. В качестве второго аргумента мы должны передать номер строки. Мы вычислили это число с помощью первой функции GIVE.ПУНКТ (). Поэтому мы вкладываем его в функцию ИНДЕКС(). В качестве третьего аргумента мы должны указать номер столбца. Это число мы нашли с помощью второй функции ПОИСКПОЗ(). Поэтому мы также вкладываем его в функцию ИНДЕКС().
Пример 2 В следующем примере мы хотим найти максимальную сумму продажи и день продажи.
В ячейке B276 мы используем функцию MAX(), чтобы найти максимальную стоимость продаж. Затем используйте функции ИНДЕКС () и ПОИСКПОЗ.ITEM() найдет подходящую дату. Приводим аргументы функции ИНДЕКС():
- в первом аргументе отмечаем массив, который будет искаться. В примере диапазон ячеек составляет от A265 до A274.
- во втором аргументе даем номер строки, содержащей искомую дату. Мы вычислили это число с помощью функции ПОИСКПОЗ(). Поэтому мы будем вкладывать эту функцию в функцию ИНДЕКС().
- в третьем аргументе мы вводим число 1, потому что мы хотим получить данные из первого столбца
В этом примере мы не сможем использовать функцию ПРОСМОТР.VERTICAL(), потому что мы искали столбец B и значение было взято из столбца A (слева от искомого столбца). Функция ВПР() позволяет получить значение справа от искомого столбца. Для получения информации о ВПР () см. ВПР в Excel ()
Пример 3 В примере мы хотим найти стоимость продаж для данного региона и года.
Решаем задачу с помощью функции ИНДЕКС().Мы даем следующие аргументы:
- в первом аргументе мы выбираем таблицу для поиска, т.е. диапазон ячеек от B289 до E293
- во втором аргументе мы должны указать номер строки, из которой будут получены данные . Находим это число с помощью ПОИСКПОЗ(). Эта функция вернет значение 3. Это номер строки, в которой находится год 2016.
- в третьем аргументе мы должны указать номер столбца, из которого будут извлекаться данные. Мы вычислим это число, используя функцию ДАТЬ.ПУНКТ (). Эта функция вернет значение 3. Это номер столбца северного региона.
Разделить строку в Excel | Томбукту
Связанные страницы:
Объединение строк в Excel
На этой странице описывается, как разделить строку в Excel с помощью левой, центральной и правой функций Excel.
Разделить строку в указанной позиции
есть три встроенные функции Excel, предназначенные для разделения строки в определенной позиции. Существуют левые, центральные и правые функции Excel. Эти функции описаны ниже:
Excel Левая, средняя и правая функции
Функция Excel Left Возвращает указанное количество символов слева (начало) предоставленной текстовой строки.
В следующем примере функция Left возвращает первые два символа «тестовой строки»:
= ВЛЕВО ("тестовая строка", 2) возвращает текстовую строку "te"
Функция Excel Mid Возвращает указанное количество символов из середины предоставленной текстовой строки, начиная с указанного символа.,
В приведенном ниже примере функция Mid возвращает 3 символа из середины «тестовой строки», начиная с символа 6:
= MID ("тестовая строка", 6, 3) возвращает текстовую строку "str".
Функция Excel Right Возвращает указанное количество символов справа (конец) предоставленной текстовой строки.,
В следующем примере функция Right возвращает два последних символа тестовой строки:
= ПРАВО ("Тестовая строка", 2) возвращает текстовую строку "ng"
, разделить текстовую строку на первое вхождение указанного символа
Если вы хотите разделить текстовую строку Excel по первому вхождению определенного символа (т. е. по первому пробелу), для этого нет встроенной функции Excel.Однако вы можете выполнить эту задачу с помощью функций «Слева», «По центру» или «Справа» в сочетании с другими встроенными функциями Excel.,
Другие функции Excel, которые могут быть полезны при разбиении строки на определенную позицию:
| Найти | - | Возвращает позицию подстроки в предоставленной строке (с учетом регистра). |
| Поиск | - | Возвращает позицию подстроки в заданной строке (без учета регистра). |
| Лен | - | Возвращает длину предоставленной текстовой строки., |
Обратите внимание, что единственная разница между функциями поиска и поиска заключается в том, что функция поиска чувствительна к регистру, а функция поиска — нет.
разбить текстовую строку на указанный символ -
примеровПример 1. Возврат текста От начала текстовой строки до первого пробела
Если вы хотите использовать формулу для разделения текстовой строки по первому пробелу, а затем вернуть левую часть разделенной строки, вы можете сделать это, объединив функцию «Влево» с функцией «Найти»., Это показано в следующем примере:
| А | ||||
|---|---|---|---|---|
| 1 | тестовая строка | = ЛЕВЫЙ (A1, НАЙТИ ("", A1) - 1) | - Возвращает результат "теста" |
В приведенной выше формуле find возвращает 5 в качестве пробела в заданной «тестовой строке». Вычитание 1 из этого значения дает значение 4, которое затем передается левой функции,
.Пример 2. Возвращает текст в конце текстовой строки
Если вы хотите использовать формулу для разделения текстовой строки на первый пробел, а затем вернуть правую (конечную) часть строки, вы можете сделать это, объединив правильную функцию с функцией поиска Excel и функцией Excel Len., Это показано в следующем примере:
| А | ||||
|---|---|---|---|---|
| 1 | тестовая строка | = ПРАВО (A1, ДЛИН (A1) - НАЙТИ ("", A1)) | - Возвращает "строку" |
В приведенной выше формуле функция len возвращает 11 в качестве длины тестовой строки, а функция поиска возвращает 5 в качестве пробела.
, поэтому выражение ДЛСТР (A1) - НАЙТИ ("", A1) оценивается как 6 (= 11 - 5), которое затем передается соответствующей функции.,
, поэтому функция Right возвращает последние 6 символов указанной строки.
, разделить строку на N 'с этим экземпляром указанного символа
Проблема с функциями поиска и поиска в Excel заключается в том, что их можно использовать только для поиска первого вхождения указанного символа (или строки) после указанной начальной позиции. Итак, что вы можете сделать, если хотите разбить свою строку на N 'этого пространства?,
Один из способов найти положение N-го вхождения символа — использовать функцию-заполнитель Excel в сочетании с функцией поиска или поиска в Excel.
Заполнитель заменяет N 'этого экземпляра указанной строки второй предоставленной строкой. Затем функцию Find можно использовать для возврата позиции замещающей строки, и эта позиция затем может быть доставлена в левую, центральную или правую функцию.
Пример этого показан ниже.,
разделить строку W N 'с этим вхождением указанного символа - пример
в этом примере мы возвращаем левую часть исходной текстовой строки "sample text string" до третьего пробела., iv >
| А | |||
|---|---|---|---|
| 1 | ОБРАЗЕЦ текстовой строки | ||
| 2 | = замена (A1, "", "|", 3) | — возвращает «образец текста | строка» | |
| 3 | = НАЙТИ ("|", A2) | - Возвращает "16" | |
| 4 | = ЛЕВЫЙ (A1, A3 - 1) | — возвращает «образец текста» td |
на первом шаге приведенной выше формулы мы заменили третий пробел на «|»., Причина выбора этого символа в том, что мы знаем, что его нет в исходном тексте.
Три шага, показанные в ячейках A2–A4 приведенной выше электронной таблицы, возвращают левую часть исходной текстовой строки до третьего пробела. Если вы уверены в формуле Excel, вы можете объединить эти три шага в одна формула, как показано ниже:
одиночная формула:
| 1 | ОБРАЗЕЦ текстовой строки | тд |
|---|---|---|
| 2 | = Левый (A1, найти ("/", подставить (A1, "", "|", 3)) - 1) | - Возвращает "образец текста" |
Сделайте снимок, Excel преобразует его в таблицу. Что еще нового в Office 365?
Сегодня первый день конференции Microsoft Ignite 2018, а это значит, что мы не обошлись без презентации некоторых функций Office 365. Мы уже писали о Microsoft Search и Windows Virtual Desktop, но это еще не все.
Весьма важной новинкой являются OneDrive Files On-Demand, которые появятся на компьютерах Mac, и на данный момент они могут быть протестированы инсайдерами Office.Известная (и столь же долгожданная) функция позволяет создавать файлы замены на локальном устройстве, которые, однако, не занимают места, поскольку фактически находятся в облаке и, как следует из названия, доступны. по требованию. Если файл доступен только онлайн, его необходимо загрузить на диск, чтобы открыть. Локальная память снова освобождается после завершения задания. Теперь известная и любимая функция появится на компьютерах с macOS.
Следующие новости из Excel. Новые типы данных, анонсированные в прошлом году, наконец-то стали общедоступными.Также появляется функция Вставить данные из изображения . Это позволяет вам сфотографировать таблицу и извлечь данные в электронную таблицу. Функция теперь доступна на Android.
Office 365, в свою очередь, все больше и больше интегрируется с LinkedIn. Они сводятся к возможности отправлять электронную почту и обмениваться файлами с ближайшими соединениями LinkedIn из приложений Office — Word, Excel, PowerPoint и Outlook. В этом году вы также сможете просматривать информацию из чьего-либо профиля LinkedIn в приглашениях на собрания.Интеграции пока не много и это скорее исключение из правил, учитывая, как охотно Microsoft интегрирует свои, казалось бы, далекие продукты.
В Office также появится новая функция «Идеи». Вы можете использовать его, чтобы включить «умные рекомендации» в приложениях пакета. Сначала эта функция появится в Excel и PowerPoint. Вам нужно будет нажать на молнию, чтобы попробовать.
[НОВОЕ] Размытие фона теперь доступно в #MicrosoftTeams! #MSIgnitehttps: // t.co / 9bhJZMopoL pic.twitter.com/VXISjXSKrf
— Microsoft Teams (@MicrosoftTeams) 24 сентября 2018 г.
Давайте, наконец, перейдем к Teams. Microsoft фокусируется здесь на интеллектуальной функции размытия фона, которая может распознавать лицо на изображении с камеры и размывать все, что находится за ним. Это позволяет нам сохранить большую конфиденциальность, когда мы не можем позволить себе разговор на однородном фоне, а также убрать с изображения ненужные элементы, например, беспорядок в комнате. Microsoft также упоминает функцию записи собрания, которая предоставляет стенограмму и другие метаданные .Эти функции появятся позже в этом году.
Вам нравится эта статья? Поделись с другими!
.Excel (английский): группировка и промежуточные итоги
Урок 21: Группы и промежуточные итоги
/ en / tr_pl-excel / фильтрация данных / контент /
Введение
Рабочие листы с большим количеством данных могут иногда казаться громоздкими и даже трудными для чтения. К счастью, Excel может организовать данные в групп , что позволяет легко отображать и скрывать различных разделов рабочего листа. Вы также можете суммировать различные группы с помощью команды Промежуточный итог и создать K на листе.
Необязательно: Загрузите нашу рабочую книгу.
Посмотрите видео ниже, чтобы узнать больше о группах и промежуточных итогах в Excel.
Чтобы сгруппировать строки или столбцы:
- Выберите строк или столбцов , которые вы хотите сгруппировать. В этом примере мы выбираем столбцы B , C и D.
- Выберите вкладку Данные на ленте , а затем щелкните Группа .
- Выбранные строки или столбцы будут сгруппированы по . В нашем примере столбцы B , C и D сгруппированы.
Чтобы разгруппировать данные , выберите сгруппированные строки или столбцы, а затем щелкните Разгруппировать .
Чтобы скрыть и показать группы:
- Чтобы скрыть группу, щелкните знак минус, также известный как кнопка Скрыть детали .
- Группа будет скрытой .Чтобы отобразить скрытую группу, щелкните значок «плюс», также известный как кнопка «Показать подробности ».
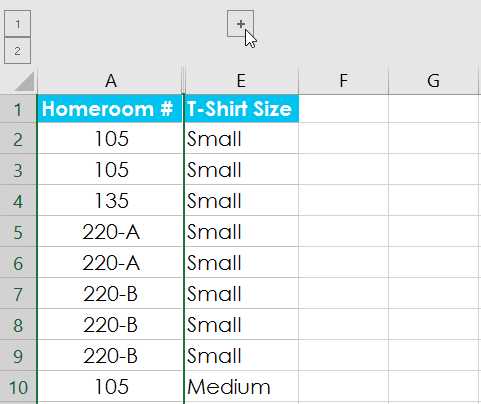
Создать промежуточные итоги
Команда промежуточного итога позволяет автоматически создавать группы и использовать общие функции, такие как СУММ, СЧЕТ и СРЗНАЧ, чтобы помочь суммировать данных. Например, команда Промежуточный итог может помочь вам рассчитать стоимость канцелярских товаров по типам на основе большого заказа инвентаризации.Эта команда создаст иерархию групп под названием схема , чтобы помочь вам организовать свой рабочий лист.
Перед использованием команды «Промежуточный итог» ваши данные должны быть правильно отсортированы , поэтому вы можете просмотреть наш урок по сортировке данных, чтобы узнать больше.
Чтобы создать промежуточный итог:
В нашем примере мы будем использовать команду «Промежуточный итог» с формой заказа футболки, чтобы определить, сколько футболок было заказано для каждого размера (маленький, средний, большой и X-большой).Это создаст контур для нашего рабочего листа с группой по для каждого размера тройника, затем будет подсчитано общее количество тройников в каждой группе.
- Сначала отсортируйте рабочий лист в соответствии с данными, которые вы хотите обобщить. В этом примере мы собираемся создать промежуточный итог для каждого размера тройника, поэтому наш рабочий лист был отсортирован по размеру тройника от наименьшего к наибольшему.
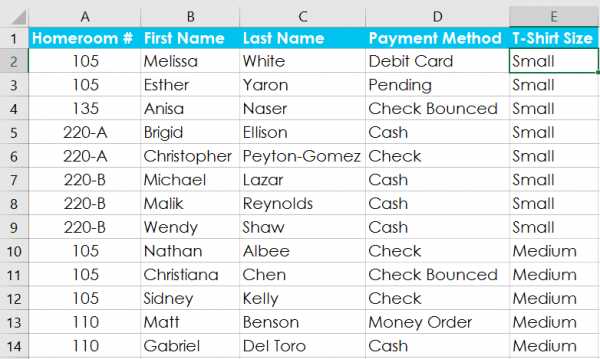
- Выберите вкладку Данные и щелкните Итого .
- Появится диалоговое окно Промежуточный итог . Щелкните стрелку раскрывающегося списка в поле . Для для каждого изменения в: выберите столбец , который вы хотите суммировать. В нашем примере мы выберем размер тройники .
- Щелкните стрелку раскрывающегося списка в поле Использовать функцию :, чтобы выбрать функцию , которую вы хотите использовать .В нашем примере мы выберем COUNT, , чтобы подсчитать количество заказанных рубашек каждого размера.
- В поле Добавить промежуточный итог к: выберите столбец , где вы хотите, чтобы отображался рассчитанный промежуточный итог . В нашем примере мы выберем размер тройники . Если вы удовлетворены своим выбором, нажмите OK .
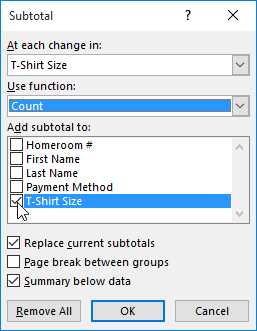
- Рабочий лист будет разделен на на групп, промежуточные итоги и будут , перечисленные ниже каждой группы.В нашем примере данные теперь сгруппированы по размеру рубашки, и под каждой группой отображается количество заказанных рубашек этого размера.
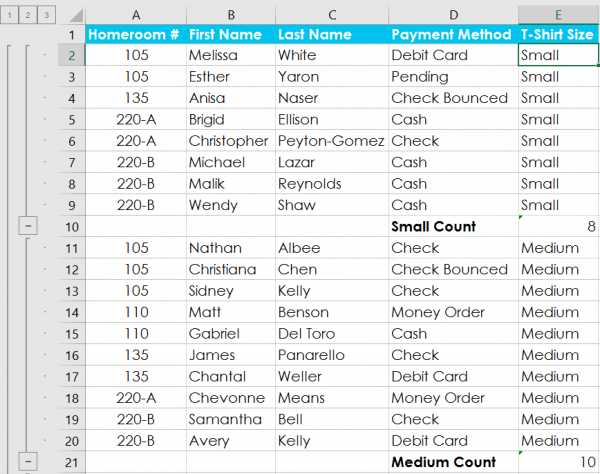
Для просмотра групп по уровню:
При создании промежуточных итогов рабочий лист разбивается на разные уровни . Вы можете переключаться между уровнями, чтобы быстро управлять объемом информации, отображаемой на рабочем листе, нажимая кнопки уровня в левой части рабочего листа.В нашем примере мы будем переключаться между всеми тремя уровнями в нашей схеме. Хотя этот пример содержит только три уровня, Excel может вместить до восьми.
- Нажмите для самого низкого уровня, для наименьшей детализации. В нашем примере мы выбираем уровень 1 , который содержит только Total count или общее количество заказанных футболок.
- Щелкните на следующем уровне, , чтобы открыть более подробную информацию.В нашем примере мы выбираем уровень 2 , который содержит каждую строку промежуточных итогов, но скрывает все остальные данные на листе.
- Нажмите для верхнего уровня, для просмотра и развертывания всех данных листа. В нашем примере мы выбираем уровень 3 .
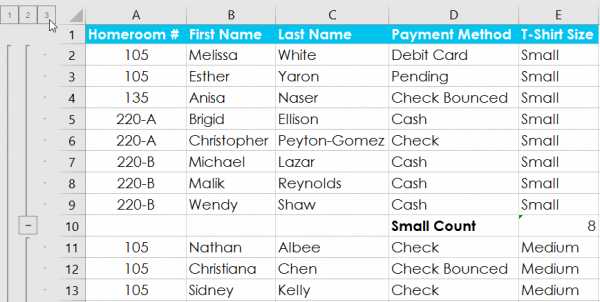
Вы также можете использовать кнопки Показать детали и Скрыть детали, для отображения и скрытия групп в схеме.
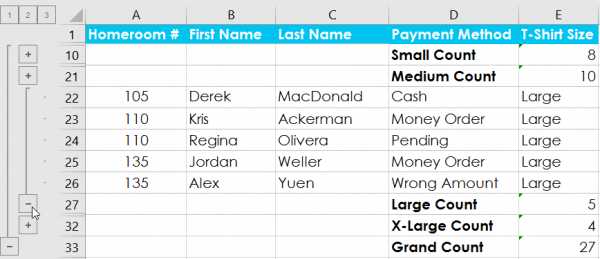
Чтобы удалить промежуточные итоги:
Иногда вы можете не захотеть хранить промежуточные итоги на листе, особенно если вы хотите реорганизовать свои данные различными способами.Если вы больше не хотите использовать промежуточный итог, вы должны удалить и из рабочего листа.
- Выберите вкладку Данные и щелкните Итого .
- Появится диалоговое окно Промежуточный итог . Нажмите Удалить все .
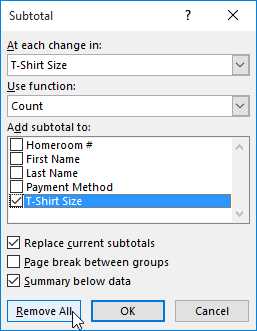
- Все данные журнала будут разгруппированы , а промежуточные итоги будут удалены .
Чтобы удалить все группы без удаления промежуточных итогов, щелкните стрелку раскрывающегося списка Разгруппировать , а затем выберите Очистить структуру .
Вызов!
- Откройте нашу рабочую тетрадь.
- Щелкните вкладку Challenge в левом нижнем углу рабочей книги.
- Сортировка рабочей тетради по Оценка от меньшего к большему.
- Используйте команду Промежуточный итог, для группировки по каждому изменению до Оценка . Используйте функцию SUM и добавьте промежуточные итоги к Amount Raised .
- Выберите уровень 2, , чтобы увидеть только короткие суммы и общую сумму.
- По завершении рабочая книга должна выглядеть так:
/ru/tr_pl-excel/таблицы/контент/
.Как рассчитать Z-Score с помощью Microsoft Excel - SamaGame
[ОБЗОР]: как рассчитать Z-индекс с помощью Microsoft Excel
Z-Score— это статистическое значение, которое сообщает вам, сколько стандартных отклонений данного значения получено из среднего значения всего набора данных. Вы можете использовать формулы AVERAGE и STDVEV или PDEV для расчета среднего значения и стандартного отклонения ваших данных, а затем использовать эти результаты для определения Z-показателя для каждого значения.
Что такое указатель Z и для чего нужны функции AVERAGE, STDEVS и STDVF?
Z-Score— это простой способ сравнить значения из двух разных наборов данных. Он определяется как количество стандартных отклонений от среднего значения точки данных. Общая формула выглядит так:
= (СРЕДНЕЕ значение точки данных (набор данных)) / стандартное отклонение (набор данных)
Вот пример для пояснения. Предположим, вы хотите сравнить баллы по алгебре двух учеников, которых обучают разные учителя.Вы знаете, что первый ученик получил 95% на выпускном экзамене в одном классе, а ученик второго — 87%.
На первый взгляд, оценка 95% более впечатляющая, но что, если бы учитель второго класса дал более сложный тест? Вы можете рассчитать Z-балл каждого учащегося на основе средних баллов для каждого класса и стандартного отклонения баллов для каждого класса. Сравнение оценок обоих учащихся может показать, что учащийся, набравший 87 % оценок, показал лучшие результаты по сравнению с остальными учениками своего класса, чем учащийся, набравший 98 % по сравнению с остальными учениками своего класса.
Первым необходимым статистическим значением является "среднее", и функция Excel "СРЕДНИЙ" вычисляет это значение. Он просто суммирует все значения в диапазоне ячеек и делит эту сумму на количество ячеек, содержащих числовые значения (пустые ячейки игнорируются).
Еще одна необходимая нам статистика — «стандартное отклонение», и в Excel есть две разные функции для вычисления стандартного отклонения немного другим способом.
Более ранние версии Excel имели только файл «DEV.СТАНДАРТ», который вычисляет стандартное отклонение, рассматривая данные как «выборку» из совокупности. Excel 2010 разделил это на две функции, вычисляющие стандартное отклонение:
ST.Dev.S: Эта функция идентична предыдущей функции «СТАНДАРТНОЕ отклонение». Вычисляет стандартное отклонение, используя данные в качестве «выборки» из генеральной совокупности. Образцом населения может быть что-то вроде конкретных комаров, собранных в рамках исследовательского проекта, или автомобилей, которые были отложены и использовались для испытаний на безопасность при столкновении.
STDV.P: Эта функция вычисляет стандартное отклонение, рассматривая данные как всю совокупность. Все население было бы подобно каждому комару на Земле или каждому автомобилю в производственной серии определенной модели.
Выбор зависит от набора данных. Разница обычно будет небольшой, но результат "STDVF.P" всегда будет меньше, чем результат "STDVS" для того же набора данных. Более консервативный подход состоит в том, чтобы предположить, что данные более разнообразны.
Давайте посмотрим на пример
В нашем примере у нас есть два столбца («Значения» и «Результат Z») и три «вспомогательных» ячейки для хранения результатов «СРЕДНИЙ», «СТАНДОТКЛОН» и «СТАНДАРТНЫЙ». В столбце «Значения» есть десять случайных чисел с центром вокруг 500, а в столбце «Z-оценка» мы будем вычислять Z-оценку на основе результатов, хранящихся во «вспомогательных» ячейках.
Сначала вычисляем среднее значение с помощью функции "СРЗНАЧ".Выберите ячейку, в которой вы будете хранить результат функции «СРЗНАЧ».
Введите следующую формулу и нажмите клавишу ввода или используйте меню «Формулы».
= СРЕДНИЙ (E2: E13)
Чтобы получить доступ к функциям из меню «Формулы», выберите раскрывающееся меню «Дополнительные возможности», выберите «Статистика», а затем нажмите «СРЕДНЕЕ».
В окне «Аргументы функции» выберите все ячейки в столбце «Значения» в качестве входных данных для поля «Число1». Вам не нужно беспокоиться о поле «Number2».
Теперь нажмите "ОК".
Далее нам нужно рассчитать стандартное отклонение значений с помощью функций «STDVS» или «STDVP». В этом примере мы покажем вам, как рассчитать оба значения, начиная с «STDVS». Выберите ячейку, в которой будет сохранен результат.
Чтобы рассчитать стандартное отклонение с помощью функции "СТАНДОТКЛ. S", введите эту формулу и нажмите клавишу Enter (или перейдите к ней через меню "Формулы").
= ДЕВ.СТАНДАРТ S (E3: E12)
Чтобы получить доступ к функциям из меню «Формулы», выберите раскрывающееся меню «Дополнительные функции», выберите «Статистика», прокрутите немного вниз и нажмите «СТАНДОТКЛОН.С».
В окне «Аргументы функции» выберите все ячейки в столбце «Значения» в качестве входных данных для поля «Число1». Вам также не нужно беспокоиться о поле «Число2».
Теперь нажмите "ОК".
Далее мы рассчитаем стандартное отклонение с помощью функции 'DEV.СТАНДАРТ.П». Выберите ячейку, в которой будет сохранен результат.
Чтобы рассчитать стандартное отклонение с помощью функции "СТАНДАРТ-DEVI.P", введите эту формулу и нажмите клавишу Enter (или перейдите к ней через меню "Формулы").
= СТАНДОТКЛОН (E3: E12)
Чтобы получить доступ к функциям из меню «Формулы», выберите раскрывающееся меню «Дополнительные функции», выберите «Статистика», немного прокрутите вниз и щелкните формулу «СТАНДОТКЛОН.П».
В окне «Аргументы функции» выберите все ячейки в столбце «Значения» в качестве входных данных для поля «Число1».Опять же, вам не нужно беспокоиться о поле «Число2».
Теперь нажмите "ОК".
Теперь, когда мы рассчитали среднее значение и стандартное отклонение наших данных, у нас есть все необходимое для расчета коэффициента Z. Мы можем использовать простую формулу, которая ссылается на ячейки, содержащие результаты «СРЕДНЕГО» и «СТАНДАРТНОГО ОТКЛОНЕНИЯ». или "DEV."Функции.STANDARD.P".
Выберите первую ячейку в столбце Z-Score. В этом примере мы будем использовать результат функции «STDV.S", но можно использовать и результат "STDev.P".
Введите следующую формулу, нажмите Enter:
= (Е3-$G$3)/$h4$
Кроме того, вы можете использовать следующие шаги, чтобы ввести формулу вместо ввода:
Щелкните ячейку F3 и введите = (
Выберите ячейку E3. (Вы можете нажать клавишу со стрелкой влево один раз или использовать мышь)
Введите знак минус -
Выберите ячейку G3, затем нажмите F4, чтобы добавить «$», чтобы создать « абсолютная" ссылка на ячейку (вы пройдете через "G3″>"$G$3″>"G$3″>"$G3″>»G3" если будете продолжать нажимать F4)
Введите) /
Выберите ячейку h4 (или I3, если вы используете «STDEV.P») и нажмите F4, чтобы добавить два символа «$».
нажмите введите
был рассчитан для первого значения. Это на 0,15945 стандартного отклонения ниже среднего. Чтобы проверить результаты, вы можете умножить стандартное отклонение на этот результат (6,271629 * -0,15945) и убедиться, что результат равен разнице между значением и средним значением (499-500). Оба результата одинаковы, поэтому значение имеет смысл.
Давайте рассчитаем Z-оценку оставшихся значений. Выберите весь столбец «Z-Score», начиная с ячейки, содержащей формулу.
Нажмите Ctrl + D, и формула в верхней ячейке будет скопирована во все остальные выбранные ячейки.
Теперь формула "заполнена" во всех ячейках, и каждая ячейка всегда будет ссылаться на правильные ячейки "СРЕДНИЙ" и "СТАНДАРТНЫЙ" или "СТАНДАРТНЫЙ" или "СТАНДАРТНЫЙ" из-за символов "$". Если вы обнаружите какие-либо ошибки, вернитесь и убедитесь, что символы «$» включены во введенную формулу.
Расчет Z-показателя без использования
вспомогательных ячеекВспомогательные ячейки хранят результаты, такие как те, которые хранят результаты для "СРЕДНЕГО", "РАЗВИТИЯ".СТАНДАРТ.С» и «СТАНДАРТ ДЕВ..П». Они могут быть полезны, но не всегда необходимы. Вместо этого их можно полностью исключить при расчете Z-показателя, используя следующие обобщенные формулы.
Вот тот, который использует функцию "STDVS":
= (СРЕДНЕЕ значение (значения)) / STDev S (значения)
И тот, который использует функцию "STEV.P":
= (СРЕДНЕЕ значение (значения)) / STDev P (значения)
При вводе диапазонов ячеек для "Значения" в функциях обязательно добавлять абсолютные ссылки ("$" с F4), чтобы при "заполнении" не вычислялось среднее или стандартное отклонение другого диапазона ячеек в каждом формула.
Если у вас большой набор данных, может быть более эффективно использовать вспомогательные ячейки, так как они не вычисляют каждый раз результаты "СРЕДНИЙ" и "СТАНДОТКЛОН" или "СТАНДОТКЛОН", экономя ресурсы ЦП и ускоряя время, необходимое для расчета результаты, достижения.
Кроме того, для "$G$3" требуется меньше байтов для хранения и меньше оперативной памяти для загрузки, чем для "СРЕДНЕГО ($E$3:$E$12)". Это важно, поскольку стандартная 32-разрядная версия Excel ограничена 2 ГБ ОЗУ (у 64-разрядной версии нет ограничений на объем используемой ОЗУ).
.







Видео-курс
